Camel-AI项目模块详解
前提内容
快捷键
- 在Pycharm中使用ctrl+F12查看类中所有方法
- 查看某一个类中的方法的实现类:鼠标点到方法名字上右键→go to→Implementations
camel项目目录如下:
camel/
├── agents/ # 智能体相关代码
├── models/ # 模型集成与管理
├── tools/ # 工具集成与使用
├── conversations/ # 对话管理与处理
├── data/ # 数据处理与管理
├── examples/ # 示例代码
├── docs/ # 文档
├── tests/ # 测试代码
├── .env # 环境配置文件
├── .gitignore # Git忽略文件配置
├── .pre-commit-config.yaml # 预提交钩子配置
├── .style.yapf # 代码风格配置
├── CONTRIBUTING.md # 贡献指南
├── LICENSE # 许可证
├── Makefile # 构建脚本
├── README.md # 项目简介
├── poetry.lock # 依赖锁定文件
└── pyproject.toml # 项目配置文件
Agent两个重要函数
在一个典型的 Agent 系统(如 AI 助手或交互式代理)中,两个重要函数通常是与 消息处理 和 任务执行 相关的功能。以下是通用的两类核心函数及其作用:
1. 消息处理函数
常见实现:step()** 或类似函数**
- 作用:
- 用于接收用户的输入(例如对话消息、图像、问题等),处理这些输入,并生成适当的响应或操作建议。
- 是 Agent 和外部交互的主要入口。
- 典型流程:
- 接收消息:用户的输入被封装为消息对象(如
BaseMessage)。 - 处理消息:Agent 调用模型、执行逻辑,生成响应。
- 返回结果:将响应返回给调用者。
- 接收消息:用户的输入被封装为消息对象(如
- 示例:
def step(self, message):
# 接收用户消息
processed_input = self.preprocess_message(message)
# 调用模型生成响应
response = self.model.generate_response(processed_input)
# 返回响应消息
return self.format_response(response)
- 应用场景:
- 用于处理用户输入的自然语言问题,例如回答问题、生成推荐等。
- 在对话系统中,
step()函数驱动整个对话流程。
2. 任务执行函数
常见实现:run()** 或类似函数**
- 作用:
- 用于执行一项或一组任务,通常是较复杂的、需要多个步骤的逻辑操作。
- 一般会依赖其他子模块(如模型预测、数据库查询、API 调用等)来完成任务。
- 典型流程:
- 接收任务指令:包括任务目标、上下文等信息。
- 执行步骤:调用子任务或模块完成任务。
- 返回结果:返回任务的完成状态或结果数据。
- 示例:
def run(self, task):
# 检查任务参数
if not self.validate_task(task):
raise ValueError("Invalid task parameters")
# 执行任务逻辑
result = self.execute_subtasks(task)
# 处理结果并返回
return self.postprocess_result(result)
- 应用场景:
- 用于完成复杂的操作,例如信息检索、任务规划、数据分析等。
- 在多步对话或任务代理中,
run()是核心调度函数。
总结
- 消息处理函数 (
step()):- 用于处理用户输入和生成即时响应。
- 适合对话代理场景,是 Agent 和用户交互的核心函数。
- 任务执行函数 (
run()):- 用于执行复杂的任务,通常涉及多步骤操作。
- 适合多任务场景,是 Agent 内部逻辑的执行引擎。
这两个函数是 Agent 的核心,因为它们分别负责 对外交互 和 内部任务管理,共同构成了 Agent 的工作机制。run 函数是 step 函数的高层封装,内部可能多次调用 step 来完成任务
run()
├── step() # 第一次交互
├── step() # 第二次交互
└── step() # 最后一次交互
Give BaseMessage to ChatAgent
将baseMessage信息输入给agent
from io import BytesIO
import requests
from PIL import Image
from camel.agents import ChatAgent
from camel.messages import BaseMessage
# 图片信息的输入
url = "https://raw.githubusercontent.com/camel-ai/camel/master/misc/logo_light.png"
response = requests.get(url)
img = Image.open(BytesIO(response.content))
# 创建系统消息,定义聊天代理的角色和行为,为了初始化聊天代理
sys_msg = BaseMessage.make_assistant_message(
role_name="Assistant", # 消息角色
content="You are a helpful assistant.", # 行为是什么
)
# 创建一个聊天代理对象
camel_agent = ChatAgent(system_message=sys_msg)
# 定义用户消息,等会儿传递给聊天代理
user_msg = BaseMessage.make_user_message(
role_name="User", content="""what's in the image?""", image_list=[img] # 包含一个文字问题和图片信息
)
# 发送用户消息并获取响应
response = camel_agent.step(user_msg)
print(response.msgs[0].content)
>>> The image features a logo for "CAMEL-AI." It includes a stylized purple camel graphic alongside the text "CAMEL-AI," which is also in purple. The design appears modern and is likely related to artificial intelligence.
Camel项目重要模块讲解
models模块
该模块包含奖惩评分机制和用到的各种模型
奖惩评分机制工作流程
BaseRewardModel(base_reward_model.py):- 定义了一个抽象基类,规定奖励模型需要实现的两个方法:
evaluate(messages: List[Dict[str, str]]) -> Dict[str, float]:评估消息并返回分数。get_scores_types() -> List[str]:获取奖励模型返回的分数类型列表。
- 具体的奖励模型(如
NemotronRewardModel和SkyworkRewardModel)继承并实现此基类。
- 定义了一个抽象基类,规定奖励模型需要实现的两个方法:
- 具体奖励模型:
NemotronRewardModel(nemotron_model.py):- 使用 OpenAI 的 API 实现,返回五种评分指标(
helpfulness,correctness,coherence,complexity,verbosity)。
- 使用 OpenAI 的 API 实现,返回五种评分指标(
SkyworkRewardModel(skywork_model.py):- 使用 HuggingFace 模型和 PyTorch 实现,返回单一分数(
Score)。
- 使用 HuggingFace 模型和 PyTorch 实现,返回单一分数(
- 评估器 (
evaluator.py):- 提供了基于奖励模型的通用评估和过滤功能:
- 调用奖励模型的
evaluate方法获取分数。 filter_data方法基于给定的阈值对消息进行过滤。
- 调用奖励模型的
- 提供了基于奖励模型的通用评估和过滤功能:
- 初始化 (
__init__.py):- 将
BaseRewardModel,NemotronRewardModel,SkyworkRewardModel, 和Evaluator导出为模块公共接口。
- 将
整体工作流程
- 选择奖励模型:
- 根据需求选择
NemotronRewardModel或SkyworkRewardModel。 - 使用 HuggingFace 的模型时选择
SkyworkRewardModel,否则选择NemotronRewardModel。
- 根据需求选择
- 初始化奖励模型:
- 通过模型类型、API Key 或 URL 初始化奖励模型。
- 调用评估器:
- 通过
Evaluator调用奖励模型的evaluate方法,获取评分。 - 使用
filter_data方法对消息进行过滤。
- 通过
详细实现流程
1. 基础奖励模型:**BaseRewardModel**
- 抽象类,定义奖励模型的基本结构:
evaluate(messages):处理消息并返回评分。get_scores_types():返回模型支持的评分类型列表。
- 子类必须实现这两个方法。
2. Nemotron 奖励模型:**NemotronRewardModel**
- 继承自
BaseRewardModel。 - 使用 OpenAI 的 API 实现:
- API 客户端初始化:通过
OpenAI客户端与服务端通信。 evaluate** 方法**:- 调用 OpenAI 的
chat.completions.create接口。 - 对返回的
ChatCompletion对象解析评分。
- 调用 OpenAI 的
- 评分类型:
helpfulness、correctness、coherence、complexity、verbosity。
- API 客户端初始化:通过
- 评分解析逻辑:
- 从
ChatCompletion对象中提取logprobs信息,映射到评分。
- 从
3. Skywork 奖励模型:**SkyworkRewardModel**
- 同样继承自
BaseRewardModel。 - 基于 HuggingFace Transformers 和 PyTorch:
- 加载 HuggingFace 模型和分词器。
- 使用
AutoModelForSequenceClassification和AutoTokenizer处理输入。
evaluate** 方法**:- 将消息通过
tokenizer编码后输入模型。 - 提取模型的输出
logits,作为单一评分(Score)。
- 将消息通过
- 评分类型只有一个:
Score。
4. 评估器:**Evaluator**
- 核心功能:
- 评估:调用奖励模型的
evaluate方法,获取消息评分。 - 过滤:
- 给定阈值(
thresholds),对消息进行过滤。 - 如果任意评分低于阈值,则消息不通过。
- 给定阈值(
- 评估:调用奖励模型的
代码调用示例
初始化并评估消息
from evaluator import Evaluator
from nemotron_model import NemotronRewardModel
# 初始化奖励模型
nemotron_model = NemotronRewardModel(model_type="gpt-4", api_key="sk-xxx")
# 初始化评估器
evaluator = Evaluator(reward_model=nemotron_model)
# 待评估的消息
messages = [{"role": "user", "content": "How can I learn Python?"}]
# 获取评分
scores = evaluator.evaluate(messages)
print("Scores:", scores)
过滤消息
# 阈值设定
thresholds = {"helpfulness": 0.8, "correctness": 0.9}
# 过滤消息
is_valid = evaluator.filter_data(messages, thresholds)
print("Message valid:", is_valid)
模型模块
核心作用是对多个大型语言模型(LLM)的统一接口封装。实现了不同模型的后端支持和配置管理,主要包括 OpenAI、Anthropic、Azure OpenAI、Cohere 和 DeepSeek 等服务。
作用分析
1. 核心抽象:**BaseModelBackend**
- 文件位置:
base_model.py。 - 作用:
- 提供一个抽象基类,定义了所有模型后端的共同功能,包括:
run(messages): 执行推理任务,返回推理结果。token_counter: 计数器,用于统计消息的 token 数。check_model_config: 校验模型配置是否合法。
- 各具体模型后端都继承此类,实现其特定的推理逻辑。
- 提供一个抽象基类,定义了所有模型后端的共同功能,包括:
模型后端实现逻辑
每个模型后端继承 BaseModelBackend,并实现其特定逻辑:
a. Anthropic 模型:AnthropicModel
- 文件位置:
anthropic_model.py。 - 作用:
- 支持 Anthropic API(Claude 系列模型)的统一接口。
- 提供 token 计数器、消息转化、以及从 Anthropic 格式到 OpenAI 格式的响应转换。
- 主要功能:
- 通过
AnthropicTokenCounter实现 token 统计。 _convert_response_from_anthropic_to_openai: 转换响应为 OpenAI 格式。
- 通过
b. Azure OpenAI 模型:AzureOpenAIModel
- 文件位置:
azure_openai_model.py。 - 作用:
- 支持 Azure 提供的 OpenAI 模型(例如 GPT 系列)的统一接口。
- 兼容 Azure 的特定配置参数(如
api_version和azure_deployment_name)。
- 主要功能:
- 自定义
api_version和azure_deployment_name检查。 - 通过 Azure OpenAI 客户端执行推理。
- 自定义
c. DeepSeek 模型:DeepSeekModel
- 文件位置:
deepseek_model.py。 - 作用:
- 支持 DeepSeek 服务的统一接口。
- 提供流式推理的能力,通过
Stream[ChatCompletionChunk]支持分块输出。
- 主要功能:
- 支持自定义 URL 和 API Key。
- 校验模型配置中是否包含无效参数。
d. Cohere 模型:CohereModel
- 文件位置:
cohere_model.py。 - 作用:
- 支持 Cohere API 的统一接口。
- 提供 Cohere 专属的消息格式转换和响应格式转换。
- 主要功能:
_to_openai_response: 将 Cohere 的响应转换为 OpenAI 格式。_to_cohere_chatmessage: 将 OpenAI 格式的消息转为 Cohere 格式。
配置管理
- 作用:
- 每个模型后端都有其特定的配置管理逻辑。
- 使用环境变量或配置文件加载必要的 API Keys 和模型参数。
- 关键点:
- 通过
os.environ.get加载 API Key 和其他配置。 - 提供校验功能(例如
check_model_config)以确保配置合法。
- 通过
**文件 **__init__.py
- 文件位置:
__init__.py。 - 作用:
- 将所有模型后端类统一导出,便于模块化使用。
- 包括所有支持的模型(如
OpenAIModel、AzureOpenAIModel等)。
messages模块
该模块主要负责处理信息交互,尤其是工具或者函数调用相关的功能
Hermes数据格式
是一种配合Json的数据格式,通过下面两种标记,嵌入对话信息和结果,使得对话系统能够识别和处理这些交互。
Let me check the weather.
<tool_call>
{"name": "get_weather", "arguments": {"city": "London"}}
</tool_call>
<tool_response>
{"name": "get_weather", "content": {"temperature": 15, "condition": "sunny"}}
</tool_response>
human、gpt、system 或tool四种角色的不同
在ShareGPTMessage中,human、gpt、system 和 tool 表示消息发送方的角色,它们的定义和用途如下:
角色介绍
human
- 含义:由人类用户发送的消息。
- 场景:通常作为对话的输入内容,表示用户的需求、提问或指令。
- 特性:
- 必须出现在对话的开始位置(
ShareGPTConversation的第一条消息)。 - 是 GPT 或工具响应的触发点。
- 必须出现在对话的开始位置(
- 示例:
{
"from": "human",
"value": "What's the weather like in London?"
}
gpt
- 含义:由 AI 助手(GPT 模型)生成的消息。
- 场景:对
human消息进行回应,或者作为工具调用的触发者。 - 特性:
- 可以是对
human消息的直接回答,也可以包含工具调用请求(例如 - 必须跟随
human或tool消息。
- 可以是对
- 示例:
- 直接回复:
{
"from": "gpt",
"value": "The weather in London is sunny with a high of 15°C."
}
- **工具调用**:
{
"from": "gpt",
"value": "Let me check the weather for you. {\"name\": \"get_weather\", \"arguments\": {\"city\": \"London\"}} "
}
system
- 含义:系统生成的消息,用于设置上下文或对话规则。
- 场景:初始化对话环境,为 GPT 或工具提供指令或背景信息。
- 特性:
- 一般在对话的开头设置,用于影响后续对话的生成逻辑。
- 不用于直接交互,但可能隐含对话的全局约束。
- 示例:
{
"from": "system",
"value": "You are a helpful assistant providing weather information."
}
tool
- 含义:工具或外部系统返回的消息。
- 场景:作为工具调用的响应,返回结果供 GPT 使用或直接返回给用户。
- 特性:
- 必须紧接包含
gpt消息。 - 表示工具调用结果,例如 API 返回的数据。
- 必须紧接包含
- 示例:
{
"from": "tool",
"value": "{\"name\": \"get_weather\", \"content\": {\"temperature\": 15, \"condition\": \"sunny\"}} "
}
角色关系与消息流动
- 对话初始化:
- 由
system或human开始。 - 示例:
- 由
[
{"from": "system", "value": "You are a helpful assistant."},
{"from": "human", "value": "What's the weather today?"}
]
- GPT 回应:
gpt消息直接响应human或调用工具。- 示例:
{"from": "gpt", "value": "Let me check that for you. {\"name\": \"get_weather\", \"arguments\": {\"city\": \"New York\"}} "}
- 工具调用与响应:
tool消息提供工具调用的结果。- 示例:
{"from": "tool", "value": "{\"name\": \"get_weather\", \"content\": {\"temperature\": 22, \"condition\": \"cloudy\"}} "}
- GPT 解析工具响应:
gpt消息处理工具结果并返回给用户。- 示例:
{"from": "gpt", "value": "The weather in New York is 22°C and cloudy."}
总结
human:人类用户输入,用于启动对话或请求信息。gpt:AI 助手生成的消息,负责回复或发起工具调用。system:系统消息,用于设定对话背景或规则。tool:工具的响应消息,返回外部系统处理的结果。一般被包含在gpt中
模块核心组成与作用
- 基础类与模型
BaseMessage(base.py** 中):**- 这是一个核心基类,用于表示通用消息结构,定义了消息的基本属性(如角色、内容、元数据等)和方法(如消息的创建、格式转换)。
ShareGPTMessage** 和ShareGPTConversation(conversation_models.py中):**ShareGPTMessage表示单条消息,ShareGPTConversation表示完整对话。这两者包含了严格的验证逻辑(如消息发送顺序)以保证对话的逻辑性。
- 功能性类
FunctionCallFormatter(function_call_formatter.py** 中):**- 一个抽象基类,定义了处理函数调用和响应的接口方法(如提取、格式化)。
HermesFunctionFormatter(hermes_function_formatter.py** 中):**- 实现了
FunctionCallFormatter接口,为 Hermes 格式提供了函数调用和响应的解析与格式化功能。
- 实现了
FunctionCallingMessage(func_message.py** 中):**- 继承自
BaseMessage,专用于处理函数调用相关的消息,支持 OpenAI、ShareGPT 等多种格式的转换。
- 继承自
- 数据模型
ToolCall** 和ToolResponse(conversation_models.py中):**- 用于定义工具/函数调用与响应的结构。这些模型确保传递的参数和响应内容是 JSON 可序列化的。
AlpacaItem(alpaca.py** 中):**- 表示指令-响应数据格式,支持从结构化字符串解析为对象,主要用于特定任务或训练数据。
模块之间的关系与流程
BaseMessage** 是核心**- 所有消息类型(如函数调用消息、ShareGPT 消息)都以
BaseMessage为基础。 - 提供了多种格式的转换方法(如
from_sharegpt和to_openai_message),使消息在不同系统间无缝流转。
- 所有消息类型(如函数调用消息、ShareGPT 消息)都以
HermesFunctionFormatter** 的格式化功能**- 提供专门的工具调用和响应的解析与格式化方法。
- 主要与
FunctionCallingMessage配合使用,用于提取消息中的工具调用(extract_tool_calls)或工具响应(extract_tool_response)。
- ShareGPT 与 Hermes 的集成
FunctionCallFormatter提供了统一的接口,而HermesFunctionFormatter作为其具体实现,支持 Hermes 格式的函数调用处理。ShareGPTMessage和ShareGPTConversation借助这些工具,保证对话流转逻辑和数据的有效性。
AlpacaItem** 的独立性**AlpacaItem主要服务于指令-响应任务,虽然与其余模块的耦合度较低,但验证逻辑与整体模块一致。
- 验证与格式化
- 模块通过多层验证(如 Pydantic 模型、正则表达式等)确保数据格式的完整性。
- 格式化工具支持不同格式的消息(如 OpenAI、ShareGPT),实现高可扩展性。
核心应用场景
- 工具调用与响应处理
- 用于处理对话中涉及的外部工具调用与响应。
- 由
HermesFunctionFormatter提供解析与格式化支持。
- 多格式消息兼容
- 支持在 ShareGPT、OpenAI 等多种格式之间转换。
- 确保系统在不同平台上的一致性和兼容性。
- 对话流转逻辑的保障
- 通过
ShareGPTConversation的验证功能,确保对话消息的顺序和逻辑性。
- 通过
Memory模块
该模块用于Agent的存储、检索和管理信息。它使代理能够在对话中保持上下文,并从过去的交互中检索相关信息,从而增强了AI响应的一致性和相关性。
- storage:负责存储数据
- retrieve:根据关键字获取相似记录
下面是embedding向量化的核心方法:
def encode(
self,
sentences: str | list[str],
prompt_name: str | None = None,
prompt: str | None = None,
batch_size: int = 32,
show_progress_bar: bool | None = None,
output_value: Literal["sentence_embedding", "token_embeddings"] | None = "sentence_embedding",
precision: Literal["float32", "int8", "uint8", "binary", "ubinary"] = "float32",
convert_to_numpy: bool = True,
convert_to_tensor: bool = False,
device: str = None,
normalize_embeddings: bool = False,
**kwargs,
) -> list[Tensor] | np.ndarray | Tensor:
"""
Computes sentence embeddings.
Args:
sentences (Union[str, List[str]]): The sentences to embed.
prompt_name (Optional[str], optional): The name of the prompt to use for encoding. Must be a key in the `prompts` dictionary,
which is either set in the constructor or loaded from the model configuration. For example if
``prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the sentence "What
is the capital of France?" will be encoded as "query: What is the capital of France?" because the sentence
is appended to the prompt. If ``prompt`` is also set, this argument is ignored. Defaults to None.
prompt (Optional[str], optional): The prompt to use for encoding. For example, if the prompt is "query: ", then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?"
because the sentence is appended to the prompt. If ``prompt`` is set, ``prompt_name`` is ignored. Defaults to None.
batch_size (int, optional): The batch size used for the computation. Defaults to 32.
show_progress_bar (bool, optional): Whether to output a progress bar when encode sentences. Defaults to None.
output_value (Optional[Literal["sentence_embedding", "token_embeddings"]], optional): The type of embeddings to return:
"sentence_embedding" to get sentence embeddings, "token_embeddings" to get wordpiece token embeddings, and `None`,
to get all output values. Defaults to "sentence_embedding".
precision (Literal["float32", "int8", "uint8", "binary", "ubinary"], optional): The precision to use for the embeddings.
Can be "float32", "int8", "uint8", "binary", or "ubinary". All non-float32 precisions are quantized embeddings.
Quantized embeddings are smaller in size and faster to compute, but may have a lower accuracy. They are useful for
reducing the size of the embeddings of a corpus for semantic search, among other tasks. Defaults to "float32".
convert_to_numpy (bool, optional): Whether the output should be a list of numpy vectors. If False, it is a list of PyTorch tensors.
Defaults to True.
convert_to_tensor (bool, optional): Whether the output should be one large tensor. Overwrites `convert_to_numpy`.
Defaults to False.
device (str, optional): Which :class:`torch.device` to use for the computation. Defaults to None.
normalize_embeddings (bool, optional): Whether to normalize returned vectors to have length 1. In that case,
the faster dot-product (util.dot_score) instead of cosine similarity can be used. Defaults to False.
Returns:
Union[List[Tensor], ndarray, Tensor]: By default, a 2d numpy array with shape [num_inputs, output_dimension] is returned.
If only one string input is provided, then the output is a 1d array with shape [output_dimension]. If ``convert_to_tensor``,
a torch Tensor is returned instead. If ``self.truncate_dim <= output_dimension`` then output_dimension is ``self.truncate_dim``.
Example:
::
from sentence_transformers import SentenceTransformer
# Load a pre-trained SentenceTransformer model
model = SentenceTransformer('all-mpnet-base-v2')
# Encode some texts
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# (3, 768)
"""
if self.device.type == "hpu" and not self.is_hpu_graph_enabled:
import habana_frameworks.torch as ht
ht.hpu.wrap_in_hpu_graph(self, disable_tensor_cache=True)
self.is_hpu_graph_enabled = True
self.eval()
if show_progress_bar is None:
show_progress_bar = logger.getEffectiveLevel() in (logging.INFO, logging.DEBUG)
if convert_to_tensor:
convert_to_numpy = False
if output_value != "sentence_embedding":
convert_to_tensor = False
convert_to_numpy = False
input_was_string = False
if isinstance(sentences, str) or not hasattr(
sentences, "__len__"
): # Cast an individual sentence to a list with length 1
sentences = [sentences]
input_was_string = True
if prompt is None:
if prompt_name is not None:
try:
prompt = self.prompts[prompt_name]
except KeyError:
raise ValueError(
f"Prompt name '{prompt_name}' not found in the configured prompts dictionary with keys {list(self.prompts.keys())!r}."
)
elif self.default_prompt_name is not None:
prompt = self.prompts.get(self.default_prompt_name, None)
else:
if prompt_name is not None:
logger.warning(
"Encode with either a `prompt`, a `prompt_name`, or neither, but not both. "
"Ignoring the `prompt_name` in favor of `prompt`."
)
extra_features = {}
if prompt is not None:
sentences = [prompt + sentence for sentence in sentences]
# Some models (e.g. INSTRUCTOR, GRIT) require removing the prompt before pooling
# Tracking the prompt length allow us to remove the prompt during pooling
tokenized_prompt = self.tokenize([prompt])
if "input_ids" in tokenized_prompt:
extra_features["prompt_length"] = tokenized_prompt["input_ids"].shape[-1] - 1
if device is None:
device = self.device
self.to(device)
all_embeddings = []
length_sorted_idx = np.argsort([-self._text_length(sen) for sen in sentences])
sentences_sorted = [sentences[idx] for idx in length_sorted_idx]
for start_index in trange(0, len(sentences), batch_size, desc="Batches", disable=not show_progress_bar):
sentences_batch = sentences_sorted[start_index : start_index + batch_size]
features = self.tokenize(sentences_batch)
if self.device.type == "hpu":
if "input_ids" in features:
curr_tokenize_len = features["input_ids"].shape
additional_pad_len = 2 ** math.ceil(math.log2(curr_tokenize_len[1])) - curr_tokenize_len[1]
features["input_ids"] = torch.cat(
(
features["input_ids"],
torch.ones((curr_tokenize_len[0], additional_pad_len), dtype=torch.int8),
),
-1,
)
features["attention_mask"] = torch.cat(
(
features["attention_mask"],
torch.zeros((curr_tokenize_len[0], additional_pad_len), dtype=torch.int8),
),
-1,
)
if "token_type_ids" in features:
features["token_type_ids"] = torch.cat(
(
features["token_type_ids"],
torch.zeros((curr_tokenize_len[0], additional_pad_len), dtype=torch.int8),
),
-1,
)
features = batch_to_device(features, device)
features.update(extra_features)
with torch.no_grad():
out_features = self.forward(features, **kwargs)
if self.device.type == "hpu":
out_features = copy.deepcopy(out_features)
out_features["sentence_embedding"] = truncate_embeddings(
out_features["sentence_embedding"], self.truncate_dim
)
if output_value == "token_embeddings":
embeddings = []
for token_emb, attention in zip(out_features[output_value], out_features["attention_mask"]):
last_mask_id = len(attention) - 1
while last_mask_id > 0 and attention[last_mask_id].item() == 0:
last_mask_id -= 1
embeddings.append(token_emb[0 : last_mask_id + 1])
elif output_value is None: # Return all outputs
embeddings = []
for sent_idx in range(len(out_features["sentence_embedding"])):
row = {name: out_features[name][sent_idx] for name in out_features}
embeddings.append(row)
else: # Sentence embeddings
embeddings = out_features[output_value]
embeddings = embeddings.detach()
if normalize_embeddings:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
# fixes for #522 and #487 to avoid oom problems on gpu with large datasets
if convert_to_numpy:
embeddings = embeddings.cpu()
all_embeddings.extend(embeddings)
all_embeddings = [all_embeddings[idx] for idx in np.argsort(length_sorted_idx)]
if precision and precision != "float32":
all_embeddings = quantize_embeddings(all_embeddings, precision=precision)
if convert_to_tensor:
if len(all_embeddings):
if isinstance(all_embeddings, np.ndarray):
all_embeddings = torch.from_numpy(all_embeddings)
else:
all_embeddings = torch.stack(all_embeddings)
else:
all_embeddings = torch.Tensor()
elif convert_to_numpy:
if not isinstance(all_embeddings, np.ndarray):
if all_embeddings and all_embeddings[0].dtype == torch.bfloat16:
all_embeddings = np.asarray([emb.float().numpy() for emb in all_embeddings])
else:
all_embeddings = np.asarray([emb.numpy() for emb in all_embeddings])
elif isinstance(all_embeddings, np.ndarray):
all_embeddings = [torch.from_numpy(embedding) for embedding in all_embeddings]
if input_was_string:
all_embeddings = all_embeddings[0]
return all_embeddings
Tools模块
可以用来自定义函数,并且传入camel将函数识别为camel的内置函数工具
- 支持定义自己的工具
- 可以利用工具包
- 也可以将工具传递给chatAgent
camel的内置工具包
| 工具箱 | 描述 |
|---|---|
| Arxiv工具包 | 一个用于与 arXiv API 交互以搜索和下载学术论文的工具包。 |
| AskNewsToolkit | 一个工具包,用于使用 AskNews API 根据用户查询获取新闻、故事和其他内容。 |
| CodeExecutionToolkit | 一个用于代码执行的工具包,可以在各种沙箱中运行代码,包括内部 Python、Jupyter、Docker、子进程或 e2b。 |
| DalleToolkit 工具包 | 使用 OpenAI 的 DALL-E 模型生成图像的工具包。 |
| DappierToolkit | 一个工具包,用于使用 Dappier API 在新闻、财经、股票市场、体育、天气等关键垂直领域搜索实时数据和获取 AI 推荐。 |
| DataCommonsToolkit 工具包 | 用于从 Data Commons 知识图谱中查询和检索数据的工具包,包括 SPARQL 查询、统计时间序列数据和属性分析。 |
| 功能工具 | 一个基本工具包,用于创建 OpenAI 聊天模型可以调用的基于函数的工具,并支持架构解析和合成。 |
| GitHub工具包 | 用于与 GitHub 存储库交互的工具包,包括检索问题和创建拉取请求。 |
| GoogleMaps工具包 | 用于访问 Google Maps 服务的工具包,包括地址验证、海拔数据和时区信息。 |
| GoogleScholar工具包 | 用于从 Google 学术搜索中检索作者及其出版物相关信息的工具包。 |
| 人类工具包 | 一个用于在 AI 系统中促进人机交互和反馈的工具包。 |
| LinkedInToolkit 工具包 | 用于 LinkedIn 操作的工具包,包括创建帖子、删除帖子和检索用户个人资料信息。 |
| MathToolkit | 用于执行基本数学运算 (如加法、减法和乘法) 的工具包。 |
| Meshy工具包 | 用于处理 3D 网格数据和操作的工具包。 |
| 概念工具包 | 一个工具包,用于使用 Notion API 从 Notion 页面和工作区中检索信息。 |
| OpenAPIToolkit | 用于处理 OpenAPI 规范和 REST API 的工具包。 |
| OpenBBToolkit | 用于通过 OpenBB 平台访问和分析金融市场数据的工具包,包括股票、ETF、加密货币和经济指标。 |
| Reddit工具包 | 用于 Reddit 操作的工具包,包括收集热门帖子、对评论执行情绪分析以及跟踪关键字讨论。 |
| RetrievalToolkit 工具包 | 一个工具包,用于根据指定的查询从本地向量存储系统中检索信息。 |
| 搜索工具包 | 一个用于使用各种搜索引擎(如 Google、DuckDuckGo、Wikipedia 和 Wolfram Alpha)执行 Web 搜索的工具包。 |
| Slack工具包 | 用于 Slack 操作的工具包,包括创建频道、加入频道和管理频道成员资格。 |
| StripeToolkit | 通过 Stripe 处理付款和管理金融交易的工具包。 |
| 推特工具包 | 用于 Twitter 操作的工具包,包括创建推文、删除推文和检索用户个人资料信息。 |
| 视频工具包 | 一个用于下载视频并选择性地将其拆分为块的工具包,支持各种视频服务。 |
| WeatherToolkit | 一个使用 OpenWeatherMap API 获取城市天气数据的工具包。 |
| WhatsApp工具包 | 用于与 WhatsApp Business API 交互的工具包,包括发送消息、管理消息模板和访问企业简介信息。 |
Prompt模块
使用prompt模版可以创建AI专家,聚合这些专家来创建特定的任务代理
from camel.agents import TaskSpecifyAgent
from camel.configs import ChatGPTConfig
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType, TaskType
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI,
model_type=ModelType.GPT_4O_MINI,
)
task_specify_agent = TaskSpecifyAgent(
model=model, task_type=TaskType.AI_SOCIETY
)
specified_task_prompt = task_specify_agent.run(
task_prompt="Improving stage presence and performance skills",
meta_dict=dict(
assistant_role="Musician", user_role="Student", word_limit=100
),
)
print(f"Specified task prompt:\n{specified_task_prompt}\n")
创建任务时设置指定代理task_type=TaskType.AI_SOCIETY,它会自动唤起带有模板的提示:AISocietyPromptTemplateDict.TASK_SPECIFY_PROMPT,可以设置希望助手扮演的角色。输出将如下所示:
>> Response:
Musician will help Student enhance stage presence by practicing engaging eye contact, dynamic movement, and expressive gestures during a mock concert, followed by a review session with video playback to identify strengths and areas for improvement.
也可以自己传入模版
from camel.agents import TaskSpecifyAgent
from camel.configs import ChatGPTConfig
from camel.models import ModelFactory
from camel.prompts import TextPrompt
from camel.types import ModelPlatformType, ModelType
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI,
model_type=ModelType.GPT_4O_MINI,
)
my_prompt_template = TextPrompt(
'Here is a task: I\'m a {occupation} and I want to {task}. Help me to make this task more specific.'
) # Write anything you would like to use as prompt template
task_specify_agent = TaskSpecifyAgent(
model=model, task_specify_prompt=my_prompt_template
)
response = task_specify_agent.run(
task_prompt="get promotion",
meta_dict=dict(occupation="Software Engineer"),
)
print(response)
Task模块
定义任务
from camel.tasks import Task
task = Task(
content="Weng earns $12 an hour for babysitting. Yesterday, she just did 51 minutes of babysitting. How much did she earn?",
id="0",
)
多任务定义的结构
# Creating the root task
root_task = Task(content="Prepare a meal", id="0")
# Creating subtasks for the root task
sub_task_1 = Task(content="Shop for ingredients", id="1")
sub_task_2 = Task(content="Cook the meal", id="2")
sub_task_3 = Task(content="Set the table", id="3")
# Creating subtasks under "Cook the meal"
sub_task_2_1 = Task(content="Chop vegetables", id="2.1")
sub_task_2_2 = Task(content="Cook rice", id="2.2")
# Adding subtasks to their respective parent tasks
root_task.add_subtask(sub_task_1)
root_task.add_subtask(sub_task_2)
root_task.add_subtask(sub_task_3)
sub_task_2.add_subtask(sub_task_2_1)
sub_task_2.add_subtask(sub_task_2_2)
# Printing the hierarchical task structure
print(root_task.to_string())
>>>
Task 0: Prepare a meal
Task 1: Shop for ingredients
Task 2: Cook the meal
Task 2.1: Chop vegetables
Task 2.2: Cook rice
Task 3: Set the table
分解或编写任务涉及定义其负责的Agent、提示模板和代理响应解析器
from camel.agents import ChatAgent
from camel.tasks import Task
from camel.tasks.task_prompt import (
TASK_COMPOSE_PROMPT,
TASK_DECOMPOSE_PROMPT,
)
from camel.messages import BaseMessage
sys_msg = BaseMessage.make_assistant_message(
role_name="Assistant", content="You're a helpful assistant"
)
# Set up an agent
agent = ChatAgent(system_message=sys_msg)
task = Task(
content="Weng earns $12 an hour for babysitting. Yesterday, she just did 51 minutes of babysitting. How much did she earn?",
id="0",
)
new_tasks = task.decompose(agent=agent, template=TASK_DECOMPOSE_PROMPT)
for t in new_tasks:
print(t.to_string())
>>>
Task 0.0: Convert 51 minutes into hours.
Task 0.1: Calculate Weng's earnings for the converted hours at the rate of $12 per hour.
Task 0.2: Provide the final earnings amount based on the calculation.
# compose task result by the sub-tasks.
task.compose(agent=agent, template=TASK_COMPOSE_PROMPT)
print(task.result)
任务管理器
from camel.tasks import (
Task,
TaskManager,
)
sys_msg = "You're a helpful assistant"
# Set up an agent
agent = ChatAgent(system_message=sys_msg)
task = Task(
content="Weng earns $12 an hour for babysitting. Yesterday, she just did 51 minutes of babysitting. How much did she earn?",
id="0",
)
print(task.to_string())
>>>Task 0: Weng earns $12 an hour for babysitting. Yesterday, she just did 51 minutes of babysitting. How much did she earn?
task_manager = TaskManager(task)
evolved_task = task_manager.evolve(task, agent=agent)
print(evolved_task.to_string())
>>>Task 0.0: Weng earns $12 an hour for babysitting. Yesterday, she babysat for 1 hour and 45 minutes. If she also received a $5 bonus for exceptional service, how much did she earn in total for that day?
Loader模块
CAMEL 引入了两个 IO 模块Base IO和Unstructured IO,它们专为处理各种文件类型和非结构化数据处理而设计。 此外,还添加了四个新的数据读取器,即Apify Reader,Chunkr Reader,Firecrawl Reader和Jina_url Reader,它们支持检索外部数据以改进数据集成和分析。
Storage模块
Storage 模块是一个全面的框架,旨在处理各种类型的数据存储机制。它由抽象基类和具体实现组成,同时满足键值存储和向量存储系统的需求。
Society模块
社会模块是 Camel 的核心模块之一。通过模拟信息交换过程,该模块研究代理之间的社会行为。
目前,社会模块旨在使代理能够自主协作完成任务,同时与人类意图保持一致,并且需要最少的人工干预。它包括两个框架:RolePlaying和BabyAGI ,用于运行代理的交互行为以实现目标。
用RolePlaying举例,该框架是以遵循指令的方式设计的。这些角色分别独立承担执行和规划任务的职责。对话通过轮流机制不断推进,从而协作完成任务。主要概念包括:
- 任务:任务可以像想法一样简单,由启动提示初始化。
- AI User:需要提供说明的代理。
- AI 助手:预期使用满足指令的解决方案进行响应的代理。
RolePlaying是 CAMEL 独有的合作代理框架。通过这个框架,可以实现例如角色翻转、助手重复指令、片状回复、消息无限循环和对话终止条件。
在 CAMEL 中使用RolePlaying框架时,预定义的提示用于为不同的Agent创建唯一的初始设置。例如,如果用户想要初始化一个助理 Agent,则会使用以下提示初始化 Agent。
- 永远不要忘记你是
,我是 。
这会将所选角色分配给助理代理,并为其提供有关用户角色的信息。
- 永远不要互换角色!永远不要指示我!
这可以防止代理翻转角色。在某些情况下,我们观察到 Assistant 和用户切换角色,其中 Assistant 突然接管控制权并指示用户,而用户则遵循这些指示。
- 如果您因身体、道德、法律原因或您的能力而无法执行我的指示,您必须诚实地拒绝我的指示,并解释原因。
这禁止代理制作有害、虚假、非法和误导性信息。
- 除非我说任务已完成,否则您应该始终从以下位置开始:解决方案:
。 应该是具体的,并为任务解决提供更可取的实现和示例。
这鼓励助理始终以一致的格式进行回应,避免与对话结构有任何偏差,并防止模糊或不完整的回应,我们称之为片状回应,例如“我会做某事”。
- 始终以以下方式结束您的解决方案:Next request。
这可确保助手通过请求新的指令来解决来保持对话的进行。
RolePlaying属性
| 属性 | 类型 | 描述 |
|---|---|---|
| assistant_role_name | str | 助理所扮演的角色的名称。 |
| user_role_name | str | 用户所扮演的角色的名称。 |
| critic_role_name | str | 评论家所扮演的角色的名称。 |
| task_prompt | str | 要执行的任务的提示。 |
| with_task_specify | 布尔 | 是否使用任务指定 agent。 |
| with_task_planner | 布尔 | 是否使用 Task Planner 代理。 |
| with_critic_in_the_loop | 布尔 | 是否在循环中包含评论家。 |
| critic_criteria | str | Critic agent 的 critic 标准。 |
| 型 | BaseModel后端 | 用于生成响应的模型后端。 |
| task_type | TaskType | 要执行的任务类型。 |
| assistant_agent_kwargs | 字典 | 要传递给助理代理的其他参数。 |
| user_agent_kwargs | 字典 | 要传递给用户代理的其他参数。 |
| task_specify_agent_kwargs | 字典 | 要传递给任务的其他参数指定 agent。 |
| task_planner_agent_kwargs | 字典 | 要传递给 Task Planner 代理的其他参数。 |
| critic_kwargs | 字典 | 要传递给批评家的其他论点。 |
| sys_msg_generator_kwargs | 字典 | 要传递给系统消息生成器的其他参数。 |
| extend_sys_msg_meta_dicts | 列表[Dict] | 用于扩展系统消息元 dicts 的 dict 列表。 |
| extend_task_specify_meta_dict | 字典 | 用于扩展任务的 dict specify meta dict with。 |
| output_language | str | 代理程序要输出的语言。 |
使用RolePlaying
from colorama import Fore
from camel.societies import RolePlaying
from camel.utils import print_text_animated
# 主函数
def main(model=None, chat_turn_limit=50) -> None:
# 初始化任务提示,描述要开发一个股票市场的交易机器人
task_prompt = "Develop a trading bot for the stock market"
# 创建一个角色扮演会话,模拟用户与 AI 之间的互动
role_play_session = RolePlaying(
assistant_role_name="Python Programmer", # AI助手角色为Python程序员
assistant_agent_kwargs=dict(model=model), # 使用传入的模型作为助手代理
user_role_name="Stock Trader", # 用户角色为股票交易员
user_agent_kwargs=dict(model=model), # 使用传入的模型作为用户代理
task_prompt=task_prompt, # 任务提示
with_task_specify=True, # 启用任务说明
task_specify_agent_kwargs=dict(model=model), # 任务指定代理的模型参数
)
# 输出 AI 助手的系统消息
print(
Fore.GREEN
+ f"AI Assistant sys message:\n{role_play_session.assistant_sys_msg}\n"
)
# 输出 AI 用户的系统消息
print(
Fore.BLUE + f"AI User sys message:\n{role_play_session.user_sys_msg}\n"
)
# 输出原始的任务提示(黄色)
print(Fore.YELLOW + f"Original task prompt:\n{task_prompt}\n")
# 输出经过任务指定代理处理后的任务提示(青色)
print(
Fore.CYAN
+ "Specified task prompt:"
+ f"\n{role_play_session.specified_task_prompt}\n"
)
# 输出最终的任务提示(红色)
print(Fore.RED + f"Final task prompt:\n{role_play_session.task_prompt}\n")
# 初始化对话
n = 0
input_msg = role_play_session.init_chat()
# 开始对话,直到达到回合限制或检测到终止条件
while n < chat_turn_limit:
n += 1
# 进行一步对话,获取助手和用户的回应
assistant_response, user_response = role_play_session.step(input_msg)
# 检测到AI助手终止对话时,输出终止原因并结束
if assistant_response.terminated:
print(
Fore.GREEN
+ (
"AI Assistant terminated. Reason: "
f"{assistant_response.info['termination_reasons']}."
)
)
break
# 检测到用户终止对话时,输出终止原因并结束
if user_response.terminated:
print(
Fore.GREEN
+ (
"AI User terminated. "
f"Reason: {user_response.info['termination_reasons']}."
)
)
break
# 动画化输出用户的响应
print_text_animated(
Fore.BLUE + f"AI User:\n\n{user_response.msg.content}\n"
)
# 动画化输出助手的响应
print_text_animated(
Fore.GREEN + "AI Assistant:\n\n"
f"{assistant_response.msg.content}\n"
)
# 如果用户响应中包含"CAMEL_TASK_DONE",说明任务完成,跳出循环
if "CAMEL_TASK_DONE" in user_response.msg.content:
break
# 更新输入消息为助手的响应,进行下一回合对话
input_msg = assistant_response.msg
# 程序入口,运行主函数
if __name__ == "__main__":
main()
Embedding模块
为不同类型的数据(文本、图像、视频)创建embedding来将这些输入转换为机器可以理解和有效处理的数字形式。每种类型的embedding都侧重于捕获其各自数据类型的基本特征。
数据类型
文本嵌入
文本嵌入将文本数据转换为数字向量。每个向量都代表文本的语义含义,使我们能够根据文本的含义而不仅仅是原始形式来处理和比较文本。OpenAI Embedding 等技术使用大规模语言模型来理解语言中的上下文和细微差别。另一方面,SentenceTransformerEncoder 是专门为创建句子嵌入而设计的,通常使用类似 BERT 的模型。
请看两句话:
- “一个小男孩在公园里踢足球。”
- “一个孩子在操场上踢足球。”
文本嵌入模型会将这些句子转换为两个高维向量(例如, text-embedding-3-small为1536 维)。尽管措辞不同,但向量将是相似的,捕捉了孩子在户外玩球类游戏的共同概念。这种转换为向量使机器能够理解和比较上下文之间的语义相似性。
图像嵌入
图像嵌入将图像转换为数字向量,从而捕获形状、颜色、纹理和空间层次结构等基本特征。这种转换通常由卷积神经网络 (CNN) 或其他专为图像处理而设计的高级神经网络架构执行。生成的嵌入可用于图像分类、相似性比较和检索等任务。
假设我们有一个猫的图像。图像嵌入模型将分析视觉内容(例如,耳朵的形状、毛皮的图案)并将其转换为矢量。此向量封装了图像的本质,使模型能够将其识别为猫并将其与其他图像区分开来。
Embedding类型
使用OpenAIEmbedding
利用 OpenAI 的模型生成文本嵌入。需要 OpenAI API 密钥。
from camel.embeddings import OpenAIEmbedding
from camel.types import EmbeddingModelType
# Initialize the OpenAI embedding with a specific model
openai_embedding = OpenAIEmbedding(model_type=EmbeddingModelType.TEXT_EMBEDDING_3_SMALL)
# Generate embeddings for a list of texts
embeddings = openai_embedding.embed_list(["Hello, world!", "Another example"])
使用MistralEmbedding
利用 Mistral 的模型生成文本嵌入。需要 Mistral API 密钥。
from camel.embeddings import MistralEmbedding
from camel.types import EmbeddingModelType
# Initialize the OpenAI embedding with a specific model
mistral_embedding = MistralEmbedding(model_type=EmbeddingModelType.MISTRAL_EMBED)
# Generate embeddings for a list of texts
embeddings = mistral_embedding.embed_list(["Hello, world!", "Another example"])
使用SentenceTransformerEncoder
利用 Sentence Transformers 库中的开源模型生成文本嵌入。
from camel.embeddings import SentenceTransformerEncoder
# Initialize the Sentence Transformer Encoder with a specific model
sentence_encoder = SentenceTransformerEncoder(model_name='intfloat/e5-large-v2')
# Generate embeddings for a list of texts
embeddings = sentence_encoder.embed_list(["Hello, world!", "Another example"])
使用VisionLanguageEmbedding
利用 OpenAI 的模型生成图像嵌入。需要 OpenAI API 密钥。
from camel.embeddings import VisionLanguageEmbedding
vlm_embedding = VisionLanguageEmbedding()
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
test_images = [image, image]
embeddings = vlm_embedding.embed_list(test_images)
Retrievers模块
Retrievers 模块本质上是一个搜索引擎。旨在帮助通过搜索大量文本来查找特定信息。比如有一个巨大的图书馆,想找到提到某些主题或关键词的地方,这个模块就像一个图书管理员,可以帮助做到这一点。
检索器类型
向量检索器
Vector Retriever 通常是指用于信息检索和机器学习的方法或系统,它利用数据的向量表示。这种方法基于将数据(如文本、图像或其他形式的信息)转换为高维空间中的数值向量。
以下是其工作原理的简要概述:
- Embedding Model:首先,它使用 embedding 模型。此模型将文本转换为数学形式 (向量) 。
- 存储信息:该模块获取大型文档,将它们分解成更小的块,然后使用嵌入模型将这些块转换为向量。这些向量存储在向量存储中。
- 检索信息:当我们提出问题或进行查询时,嵌入模型将我们的问题转换为向量,然后在此向量存储中搜索最匹配的向量。最接近的匹配项可能是我们正在寻找的最相关的信息。
关键字检索器
Keyword Retriever 旨在根据关键字匹配检索相关信息。与使用数据的矢量表示的 Vector Retriever 不同,Keyword Retriever 通过识别文档和查询中的关键字或特定术语来查找匹配项。
以下是其工作原理的简要概述:
- 文档预处理:在使用检索器之前,会对文档进行预处理,以对其中的关键字进行标记和索引。分词化是将文本拆分为单个单词或短语的过程,从而更容易识别关键字。
- 查询解析:当我们输入问题或查询时,检索器会解析查询以提取相关关键字。这涉及将查询分解为其组成术语。
- 关键字匹配:确定查询中的关键字后,检索器会在预处理的文档中搜索这些关键字的出现次数。它会检查文档中关键字的完全匹配项。
- 排名和检索:找到包含查询关键字的文档后,检索器会根据各种因素对这些文档进行排名,例如关键字匹配的频率、文档相关性或其他评分方法。然后,排名靠前的文档将作为最相关的结果进行检索。
快速入门
使用 Vector Retriever
初始化 VectorRetrieve:首先,我们需要使用可选的嵌入模型VectorRetriever进行初始化。如果我们不提供嵌入模型,它将使用默认的OpenAIEmbedding :
from camel.embeddings import OpenAIEmbedding
from camel.retrievers import VectorRetriever
# Initialize the VectorRetriever with an embedding model
vr = VectorRetriever(embedding_model=OpenAIEmbedding())
嵌入和存储数据:在我们检索信息之前,我们需要准备数据并将其存储在 vector storage 中。该方法为我们解决了这个问题。它处理来自文件或 URL 的内容,将其划分为块,并将其嵌入存储在指定的矢量存储中。
# Provide the path to our content input (can be a file or URL)
content_input_path = "https://www.camel-ai.org/"
# Create or initialize a vector storage (e.g., QdrantStorage)
from camel.storages.vectordb_storages import QdrantStorage
vector_storage = QdrantStorage(
vector_dim=OpenAIEmbedding().get_output_dim(),
collection_name="my first collection",
path="storage_customized_run",
)
# Embed and store chunks of data in the vector storage
vr.process(content_input_path, vector_storage)
执行查询:现在我们的数据已存储,我们可以执行查询以根据搜索字符串检索信息。该方法执行查询并将检索到的结果编译为字符串。query
# Specify our query string
query = "What is CAMEL"
# Execute the query and retrieve results
results = vr.query(query, vector_storage)
print(results)
>>> [{'similarity score': '0.812884257383057', 'content path': 'https://www.camel-ai.org/', 'metadata': {'filetype': 'text/html', 'languages': ['eng'], 'page_number': 1, 'url': 'https://www.camel-ai.org/', 'link_urls': ['/home', '/home', '/research/agent-trust', '/agent', '/data_explorer', '/chat', 'https://www.google.com/url?q=https%3A%2F%2Fcamel-ai.github.io%2Fcamel&sa=D&sntz=1&usg=AOvVaw1ifGIva9n-a-0KpTrIG8Cv', 'https://www.google.com/url?q=https%3A%2F%2Fgithub.com%2Fcamel-ai%2Fcamel&sa=D&sntz=1&usg=AOvVaw03Z2OD0-plx_zugZZgBb8w', '/team', '/sponsors', '/home', '/home', '/research/agent-trust', '/agent', '/data_explorer', '/chat', 'https://www.google.com/url?q=https%3A%2F%2Fcamel-ai.github.io%2Fcamel&sa=D&sntz=1&usg=AOvVaw1ifGIva9n-a-0KpTrIG8Cv', 'https://www.google.com/url?q=https%3A%2F%2Fgithub.com%2Fcamel-ai%2Fcamel&sa=D&sntz=1&usg=AOvVaw03Z2OD0-plx_zugZZgBb8w', '/team', '/sponsors', '/home', '/research/agent-trust', '/agent', '/data_explorer', '/chat', 'https://www.google.com/url?q=https%3A%2F%2Fcamel-ai.github.io%2Fcamel&sa=D&sntz=1&usg=AOvVaw1ifGIva9n-a-0KpTrIG8Cv', 'https://www.google.com/url?q=https%3A%2F%2Fgithub.com%2Fcamel-ai%2Fcamel&sa=D&sntz=1&usg=AOvVaw03Z2OD0-plx_zugZZgBb8w', '/team', '/sponsors', 'https://github.com/camel-ai/camel'], 'link_texts': [None, 'Home', 'AgentTrust', 'Agent App', 'Data Explorer App', 'ChatBot', 'Docs', 'Github Repo', 'Team', 'Sponsors', None, 'Home', 'AgentTrust', 'Agent App', 'Data Explorer App', 'ChatBot', 'Docs', 'Github Repo', 'Team', 'Sponsors', 'Home', 'AgentTrust', 'Agent App', 'Data Explorer App', 'ChatBot', 'Docs', 'Github Repo', 'Team', 'Sponsors', None], 'emphasized_text_contents': ['Skip to main content', 'Skip to navigation', 'CAMEL-AI', 'CAMEL-AI', 'CAMEL:\xa0 Communicative Agents for "Mind" Exploration of Large Language Model Society', 'https://github.com/camel-ai/camel'], 'emphasized_text_tags': ['span', 'span', 'span', 'span', 'span', 'span']}, 'text': 'Search this site\n\nSkip to main content\n\nSkip to navigation\n\nCAMEL-AI\n\nHome\n\nResearchAgentTrust\n\nAgent App\n\nData Explorer App\n\nChatBot\n\nDocs\n\nGithub Repo\n\nTeam\n\nSponsors\n\nCAMEL-AI\n\nHome\n\nResearchAgentTrust\n\nAgent App\n\nData Explorer App\n\nChatBot\n\nDocs\n\nGithub Repo\n\nTeam\n\nSponsors\n\nMoreHomeResearchAgentTrustAgent AppData Explorer AppChatBotDocsGithub RepoTeamSponsors\n\nCAMEL:\xa0 Communicative Agents for "Mind" Exploration of Large Language Model Society\n\nhttps://github.com/camel-ai/camel'}]
使用 Auto Retriever
为了进一步简化检索过程,我们可以使用AutoRetriever方法。此方法处理嵌入和存储数据以及执行查询。在处理多个内容输入路径时特别有用。
from camel.retrievers import AutoRetriever
from camel.types import StorageType
# Set the vector storage local path and the storage type
ar = AutoRetriever(vector_storage_local_path="camel/retrievers",storage_type=StorageType.QDRANT)
# Run the auto vector retriever
retrieved_info = ar.run_vector_retriever(
contents=[
"https://www.camel-ai.org/", # Example remote url
],
query="What is CAMEL-AI",
return_detailed_info=True, # Set this as true is we want to get detailed info including metadata
)
print(retrieved_info)
>>> Original Query:
>>> {What is CAMEL-AI}
>>> Retrieved Context:
>>> {'similarity score': '0.8380731206379989', 'content path': 'https://www.camel-ai.org/', 'metadata': {'empha
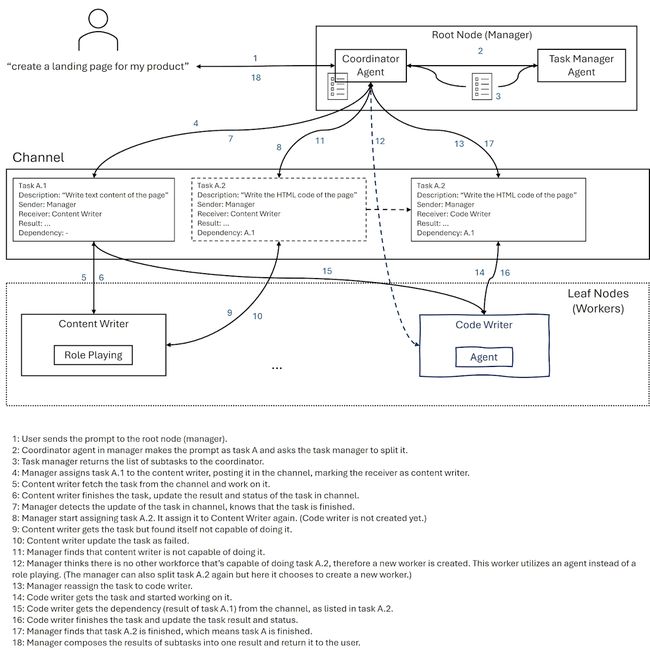
Workorce模块
Workforce 是一个系统,multiple agents协同工作以解决任务。 通过使用 Workforce,用户可以快速设置multi-agent task solving system。
System Design
Architecture
Workforce 遵循分层架构。workforce可以包括多个 Worker 节点,并且每个 Worker 节点都将包含一个或多个Agent作为工作程序。Worker 节点由员工内部的coordinator Agent,coordinator Agent将分配 tasks以及他们的工具集给 worker 节点。
除了 coordinator 代理之外,还有一个 task planner Agent。任务规划器代理将负责分解以及编写任务,以便workforce可以逐步解决任务。
Communication Mechanism
员工内部的通信基于任务通道。这 Workforce 的初始化将创建一个通道,该通道将由所有节点。任务稍后将发布到此频道中,每个 worker 节点将监听通道,接受分配的任务 到它从这个通道解决。
当任务解决时,worker 节点会将结果发布回 channel,结果将作为 其他任务,这些任务将由所有 Worker 节点共享。
借助此机制,员工可以在协作和高效的方式。
Failure Handling
在workforce中,我们有一个处理失败的机制。当任务失败时, 协调代理将采取措施来修复它。操作可以是 将任务分解为较小的任务并再次分配它们,或者创建一个 能够执行该任务的 new worker。
目前,协调器将根据 任务已分解。如果任务已经分解了更多 超过一定次数,协调器将接收新的 worker 创建操作;如果没有,协调器将简单地进行分解 行动。
在某些情况下,任务根本无法通过 代理。在这种情况下,为了防止workforce陷入困境 在无限代理创建循环中,如果执行一项任务 已失败一定次数(默认为 3 次)。
A Simple Example of the Workflow
下面是一个通过简单示例说明工作流的图表。
开始使用
本节展示如何创建 Workforce 实例,添加worker节点到workforce中,最后,如何启动workforce解决任务。
创建 Workforce 实例
要开始使用 Workforce,需要首先创建一个 Workforce 实例,然后将 worker 节点添加到 Workforce。以下是示例:
from camel.societies.workforce import Workforce
# Create a workforce instance
workforce = Workforce("A Simple Workforce")
现在,我们获得一个描述为 “A Simple Workforce” 的workforce实例。 但是,workforce中还没有worker节点。
注意:如何进一步自定义Workforce
您可以使用默认配置快速创建Workforce实例,只需提供workforce的描述。但是,也可以使用更多详细信息配置人力,例如提供 Worker 节点,而不是逐个添加,或者配置通过传递配置来获取 Coordinator Agent 和 Task Planner Agent 添加到 Workforce 实例。
添加 Worker 节点
创建 workforce 实例后,您可以将 worker 节点添加到 workforce。要添加 worker 节点,您需要先创建 worker agent 他们实际上可以完成工作。
假设我们已经创建了一个可以进行 Web 搜索的ChatAgent叫search_agent。现在,我们可以将此 worker agent 添加到人力中。
# Add the worker agent to the workforce
workforce.add_single_agent_worker(
"An agent that can do web searches",
worker=search_agent,
)
adding 函数遵循 Fluent 接口设计模式,因此您可以 在一行中将多个工作人员代理添加到人力中,如下所示:
workforce.add_single_agent_worker(
"An agent that can do web searches",
worker=search_agent,
).add_single_agent_worker(
"Another agent",
worker=another_agent,
).add_single_agent_worker(
"Yet another agent",
worker=yet_another_agent,
)
现在,我们的员工中有一些worker agents。需要创建一个任务并让worker来解决它。
注意:描述并非不重要
将代理(Agent)作为 worker 节点添加到workforce时,第一个参数 是 Worker 节点的描述。虽然这看起来很没有必要,但其实非常重要。该描述将由 coordinator 使用 agent 作为将任务分配给worker节点的基础。因此,建议提供 worker 节点的清晰简洁的描述。
启动 Workforce
将 worker 节点添加到workforce后,启动 workforce以解决任务。首先,我们可以定义一个任务:
from camel.tasks import Task
# the id of the task can be any string to mark the task
task = Task(
content="Make a travel plan for a 3-day trip to Paris.",
id="0",
)
然后,我们可以启动具有任务的workforce:
task = workforce.process_task(task)
任务的最终结果将存储在 task 对象。您可以通过以下方式检查结果:
print(task.result)