airbnb
Instead of waking to overlooked “Do not disturb” signs, Airbnb travelers find themselves rising with the birds in a whimsical treehouse, having their morning coffee on the deck of a houseboat, or cooking a shared regional breakfast with their hosts.
Airbnb旅行者没有醒来却忽略了“请勿打扰”的标志,而是发现自己与异想天开的树屋中的鸟儿一起起床,在船屋甲板上喝早咖啡,或与房东共享区域早餐。
New users on Airbnb can book a place to stay in 34,000+ cities across 190+ countries. By accurately predicting where a new user will book their first travel experience, Airbnb can share more personalized content with their community, decrease the average time to first booking, and better forecast demand.
Airbnb上的新用户可以预订在190多个国家/地区的34,000多个城市中居住的地方。 通过准确地预测新用户将在哪里预订他们的第一次旅行体验,Airbnb可以与社区共享更多个性化的内容,减少首次预订的平均时间,并更好地预测需求。
In this kaggle competition, Airbnb challenges you to predict in which country a new user will make his or her first booking.
在这场kaggle竞赛中,Airbnb挑战您如何预测新用户将在哪个国家/地区进行首次预订。
内容: (Contents :)
- Business Problem 业务问题
- Use of ML ML的使用
- Source of Data 资料来源
- Existing Approaches 现有方法
- My Improvements 我的进步
- EDA EDA
- First Cut Solution 初切解决方案
- Comparison of Models 模型比较
- Kaggle Screenshot Kaggle截图
- Future Work 未来的工作
1.业务问题 (1. Business Problem)
Airbnb, Inc. is an American vacation rental online marketplace company based in San Francisco, California, United States. Airbnb offers arrangement for lodging, primarily homestays, or tourism experiences. The company does not own any of the real estate listings, nor does it host events; it acts as a broker, receiving commissions from each booking.
Airbnb,Inc.是一家美国度假租赁在线市场公司,总部位于美国加利福尼亚州旧金山。 Airbnb提供住宿,主要是寄宿家庭或旅游体验的安排。 该公司不拥有任何房地产清单,也没有举办活动; 它充当经纪人,从每次预订中收取佣金。
New users on Airbnb can book a place to stay in 34,000+ cities across 190+ countries. By accurately predicting where a new user will book their first travel experience, Airbnb can share more personalized content with their community, decrease the average time to first booking, and better forecast demand.
Airbnb上的新用户可以预订在190多个国家/地区的34,000多个城市中居住的地方。 通过准确地预测新用户将在哪里预订他们的第一次旅行体验,Airbnb可以与社区共享更多个性化的内容,减少首次预订的平均时间,并更好地预测需求。
We need to predict in which country a new user will make his or her first booking.
我们需要预测新用户将在哪个国家/地区进行首次预订。
2. ML的使用 (2. Use of ML)
We’ll use machine learning techniques to predict where a new user will book his/her first destination along with 4 other most probable destinations using NDCG score — https://www.kaggle.com/c/airbnb-recruiting-new-user-bookings/overview/evaluation.
我们将使用机器学习技术,使用NDCG分数预测新用户将在哪里预定他/她的第一个目的地以及其他4个最可能的目的地— https://www.kaggle.com/c/airbnb-recruiting-new-user -预订/概述/评估 。
3.数据来源 (3. Source of Data)
The dataset is taken from the kaggle competion page — https://www.kaggle.com/c/airbnb-recruiting-new-user-bookings/data .
该数据集来自kaggle竞争页面— https://www.kaggle.com/c/airbnb-recruiting-new-user-bookings/data 。
- In this challenge, we are given a list of users along with their demographics, web session records, and some summary statistics. You are asked to predict which country a new user’s first booking destination will be. All the users in this dataset are from the USA. 在这一挑战中,我们将获得用户列表以及他们的人口统计信息,Web会话记录和一些摘要统计信息。 要求您预测新用户的第一个预订目的地将在哪个国家。 该数据集中的所有用户均来自美国。
- There are 12 possible outcomes of the destination country: ‘US’, ‘FR’, ‘CA’, ‘GB’, ‘ES’, ‘IT’, ‘PT’, ‘NL’,’DE’, ‘AU’, ‘NDF’ (no destination found), and ‘other’. ‘NDF’ is different from ‘other’ because ‘other’ means there was a booking, but is to a country not included in the list, while ‘NDF’ means there wasn’t a booking. 目的地国家/地区可能有12种可能的结果:“美国”,“ FR”,“ CA”,“ GB”,“ ES”,“ IT”,“ PT”,“ NL”,“ DE”,“ AU”, “ NDF”(找不到目的地)和“其他”。 “ NDF”与“ other”不同,因为“ other”表示有预订,但未包括在列表中的国家/地区,而“ NDF”表示没有预订。
- The dataset consists of — Train_users.csv, Sessions.csv, Countries.csv, Age_gender_bkts.csv. 数据集包含-Train_users.csv,Sessions.csv,Countrys.csv,Age_gender_bkts.csv。
4.现有方法 (4. Existing Approaches)
- The sessions data has web sessions log for users — for both in the train and test sets 会话数据具有用户的Web会话日志-在训练和测试集中
- user_id: to be joined with the column ‘id’ in users table user_id:与用户表中的“ id”列结合
- action 行动
- action_type action_type
- action_detail action_detail
- device_type 设备类型
- secs_elapsed secs_elapsed
But the problem is that only 35% of the train users have session data along with 99% of the users from the test data.
但是问题在于,只有35%的列车用户拥有会话数据,而测试数据中只有99%的用户具有会话数据。
Now, either we could have used only the train data without making use of the session data or discard 65% of the train data and make use of the session data.
现在,我们可以只使用火车数据而不使用会话数据,或者丢弃65%的火车数据并使用会话数据。
People who used the former approach got a relatively low score as compared with the latter approach.
与后一种方法相比,使用前一种方法的人得分相对较低。
Comparison with other submitted notebooks ordered by best score
1) https://www.kaggle.com/zhugds/test-script - score = 0.87008
== This user doesnt make use of the sessions data, instead uses the entire train data.
== But from our model, we know secs_elapsed and other actions are among the most imp features.
== Thus, we get a better score.
2) https://www.kaggle.com/wallinm1/script-0-1 - score = 0.86987
== This user also doesnt make use of the sessions data, instead uses the entire train data.
== But from our model, we know secs_elapsed and other actions are among the most imp features.
== Thus, we get a better score.
3) https://www.kaggle.com/kapetis/script-0-1 - score = 0.86987
== This user also doesnt make use of the sessions data, instead uses the entire train data.
== But from our model, we know secs_elapsed and other actions are among the most imp features.
== Thus, we get a better score.
4) https://www.kaggle.com/foutik/script-cleaning-data - score = 0.86969
== This user also doesnt make use of the sessions data, instead uses the entire train data.
== But from our model, we know secs_elapsed and other actions are among the most imp features.
== Thus, we get a better score.
5) https://www.kaggle.com/michaelpawlus/xgb-feature-exploration - score = 0.85655
== This user also doesnt make use of the sessions data, instead uses the entire train data.
== But from our model, we know secs_elapsed and other actions are among the most imp features.
== Thus, we get a better score.5.我的进步 (5. My Improvements)
- Use both data Train.csv and Session.csv for feature extraction and feature engineering. 将数据Train.csv和Session.csv都用于特征提取和特征工程。
- The session csv has multiple records for every ID/user , where each record captures the users’ actions and the time spent doing that action on airbnb. 会话csv对于每个ID /用户都有多个记录,其中每个记录都记录了用户的操作以及在airbnb上执行该操作所花费的时间。
- I collated all the actions into a single field and used TF-IDF vectorizer to capture the prevalence and rarity of each action. 我将所有动作整理到一个字段中,并使用TF-IDF矢量化器捕获每个动作的普遍性和稀有性。
- Feature engineering on age and date columns. 年龄和日期列上的功能工程。
6. EDA (6. EDA)
单变量分析 (Univariate analysis)
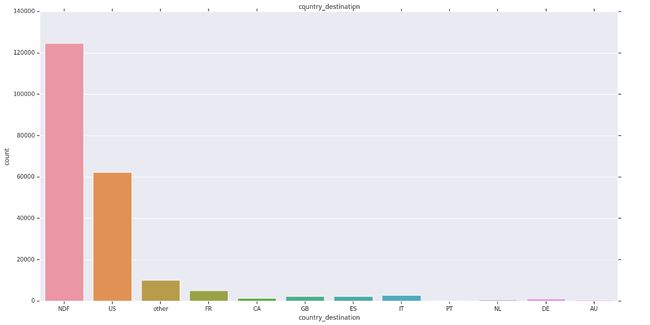
1) The Dataset is highly Imbalanced.
1)数据集高度不平衡。
2) Majority of users didnt do any booking or travelled to the US only.
2)大多数用户没有做任何预订或仅去美国旅行。
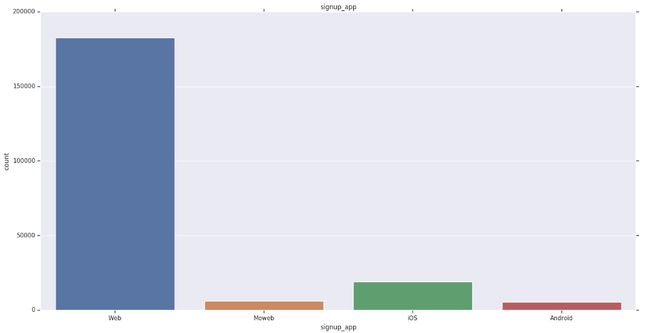
1) Majority of users’ signup app is ‘Web’.
1)大多数用户的注册应用是“ Web”。
2) ‘iOS’ is second most popular.
2)'iOS'是第二受欢迎的。
2) ‘Moweb’ and ‘Android’ have the lowest share.
2)“ Moweb”和“ Android”的份额最低。
1) Majority of users either use Mac or Windows Desktop as first device for booking.
1)大多数用户将Mac或Windows桌面用作第一台预订设备。
2) iPhone and iPad come next in popularity.
2)iPhone和iPad紧随其后。

1) Airbnb’s popularity has increased exponentially from 2010 to 2014.
1)从2010年到2014年,Airbnb的知名度呈指数增长。
2) Dip in 2014 indicates test data has been taken from 2014.
2)2014年下降表示测试数据来自2014年。
双变量分析 (Bivariate analysis)

1) Majority of users travel to ‘other’ after NDF and US.
1)大多数用户在NDF和美国之后前往“其他”。
2) France’s share in female users is more than male users.
2)法国在女性用户中的份额高于男性。
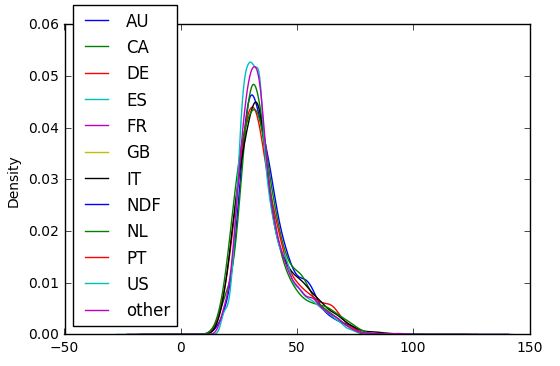
- We can differentiate the countries based on the age of the users. 我们可以根据用户年龄来区分国家。
- We can differentiate the countries based on the total time taken by the users to choose the country. 我们可以根据用户选择国家/地区的总时间来区分国家/地区。
7.初切解决方案 (7. First Cut Solution)
- In my first cut solution, I first transformed the session data from multiple records per user to single record per user . 在第一个剪切解决方案中,我首先将会话数据从每个用户的多个记录转换为每个用户的单个记录。
# Function to convert list into strings
def abcd(action):
"""
Function to convert list into strings
parameters: action
returns : action
"""
action = [ str(i) for i in action ]
action = [ re.sub('nan','',i) for i in action ]
action = ','.join(action)
return action# Function to convert list into strings
def efgh(device):
"""
Function to convert list into strings
parameters: device
returns : device
"""
device = [ str(i) for i in device ]
device = [ re.sub('nan','',i) for i in device ]
device = ','.join(set(device))
return device# Function to convert list into strings
def ijkl(time):
"""
Function to convert list into strings
parameters: time
returns : time
"""
float_time = []
time = [ str(i) for i in time ]
time = [ re.sub('nan','',i) for i in time ]
for i in time:
try:
float_time.append(float(i))
except ValueError:
continue
float_time = sum(float_time)
return float_time- Feature extractions like hour, day , week, month and year from date_account_created and first_active columns for each user. 从每个用户的date_account_created和first_active列中提取功能,例如小时,日,周,月和年。
- Creating 5 year intervals for age column. 为年龄列创建5年间隔。
- Converting all categorical variables to one hot encoded features. 将所有分类变量转换为一种热编码特征。
- Finally, TF-IDF vectorization of text columns. 最后,对文本列进行TF-IDF矢量化。
# TFIDF action
# https://stackoverflow.com/questions/28103992/tfidf-vectorizer-giving-error
vectorizer_action = TfidfVectorizer(min_df=10,max_features=5000,tokenizer=tokens)
vectorizer_action.fit(train_merge['action'].values)
train_merge_action_tfidf = vectorizer_action.transform(train_merge['action'].values)
test_merge_action_tfidf = vectorizer_action.transform(test_merge['action'].values)
print("After vectorizations")
print(train_merge_action_tfidf.shape)
print(test_merge_action_tfidf.shape)
print("="*100)# TFIDF action_type
# https://stackoverflow.com/questions/28103992/tfidf-vectorizer-giving-error
vectorizer_action_type = TfidfVectorizer(min_df=10,max_features=5000,tokenizer=tokens)
vectorizer_action_type.fit(train_merge['action_type'].values)
train_merge_action_type_tfidf = vectorizer_action_type.transform(train_merge['action_type'].values)
test_merge_action_type_tfidf = vectorizer_action_type.transform(test_merge['action_type'].values)
print("After vectorizations")
print(train_merge_action_type_tfidf.shape)
print(test_merge_action_type_tfidf.shape)
print("="*100)# TFIDF action_detail
# https://stackoverflow.com/questions/28103992/tfidf-vectorizer-giving-error
vectorizer_action_detail = TfidfVectorizer(min_df=10,max_features=5000,tokenizer=tokens)
vectorizer_action_detail.fit(train_merge['action_detail'].values)
train_merge_action_detail_tfidf = vectorizer_action_detail.transform(train_merge['action_detail'].values)
test_merge_action_detail_tfidf = vectorizer_action_detail.transform(test_merge['action_detail'].values)
print("After vectorizations")
print(train_merge_action_detail_tfidf.shape)
print(test_merge_action_detail_tfidf.shape)
print("="*100)8.模型比较 (8. Comparison of Models)
- Tested the dataset on 3 ML models — 在3个ML模型上测试了数据集-
- With Logistic Regression, I got a train ndcg score of 0.8157. 使用Logistic回归,我得到的ndcg火车得分为0.8157。
- With Random Forest, I got a train ndcg score of 0.9511 . But, It didnt work that well on the test set as it gave me — 0.88107 because of overfitting on the train set . 使用Random Forest,我的火车ndcg得分为0.9511。 但是,它在测试台上效果不佳,因为它给了我0.88107,因为在火车上过度安装。

- Finally, with Xgboost, I got a train ndcg score of 0.9066. 最后,使用Xgboost,我得到的火车ndcg分数为0.9066。
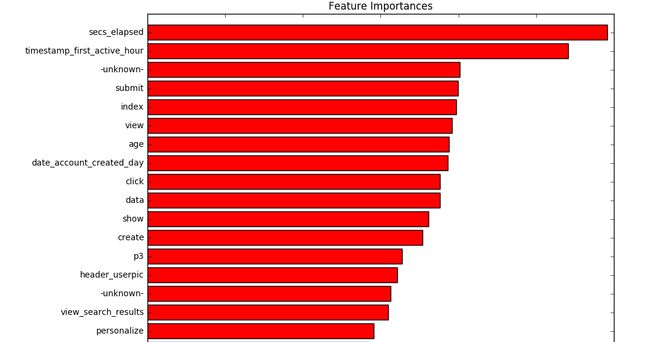
- From the feature importance plot of the model, we can see that except for timestamp_first_active_hour , age and date_account_created_day , all other features are from the session data. 从模型的功能重要性图中,我们可以看到,除了timestamp_first_active_hour,age和date_account_created_day之外,所有其他功能均来自会话数据。
9. Kaggle屏幕截图 (9. Kaggle Screenshot)
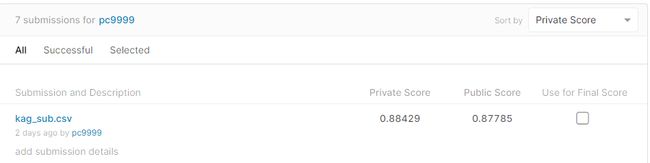
- The Xgboost model gave the best private score of — 0.88429 , which is 13% of the leaderboard. Xgboost模型给出的最高私人得分为0.88429,占页首横幅的13%。
10.未来的工作 (10. Future work)
- More rigorous hyperparameter tuning. 更严格的超参数调整。
- Bigram and Trigram features using the TF-IDF vectorizer which will increase the dimensionality and model complexity significantly , but may give a better score. 使用TF-IDF矢量化器的Bigram和Trigram功能可以显着增加维数和模型复杂度,但可能会给出更好的分数。
- Using deep learning techniques like LSTMs to capture the time series information from the action columns. 使用LSTM等深度学习技术从操作列中捕获时间序列信息。
11.参考 (11. References)
https://pdfs.semanticscholar.org/cbaf/ddba61d0ed622c0ace6c9c80ae4b2d6df58b.pdf
https://pdfs.semanticscholar.org/cbaf/ddba61d0ed622c0ace6c9c80ae4b2d6df58b.pdf
https://www.divaportal.org/smash/get/diva2:1108334/FULLTEXT01.pdf
https://www.divaportal.org/smash/get/diva2:1108334/FULLTEXT01.pdf
3. https://athena.ecs.csus.edu/~shahb/docs/report.pdf
3. https://athena.ecs.csus.edu/~shahb/docs/report.pdf
4. https://pdfs.semanticscholar.org/ca3f/b5f8615a777be4126d75e2dc28d3bee69eee.pdf
4. https://pdfs.semanticscholar.org/ca3f/b5f8615a777be4126d75e2dc28d3bee69eee.pdf
5. https://www.appliedaicourse.com/
5. https://www.appliedaicourse.com/
12. Github回购 (12. Github Repo)
Link to my github repo — https://github.com/pc90/Airbnb-New-User-Bookings---Kaggle-Competition .
链接到我的github仓库— https://github.com/pc90/Airbnb-New-User-Bookings---Kaggle-Competition 。
13. Linkedin的个人资料 (13. Linkedin profile)
Link to my Linkedin profile — https://www.linkedin.com/in/puneet-chandna-050486131/ .
链接到我的Linkedin个人资料— https://www.linkedin.com/in/puneet-chandna-050486131/ 。
翻译自: https://medium.com/swlh/airbnb-new-user-bookings-kaggle-competition-9925ef41b623
airbnb