论文阅读:Self-supervised spatio-temporal representation learning for videos by predicting motion and app
目录
Contributions
Method
1、Partitioning patterns
2、Motion Statistics
3、Appearance Statistics
Results
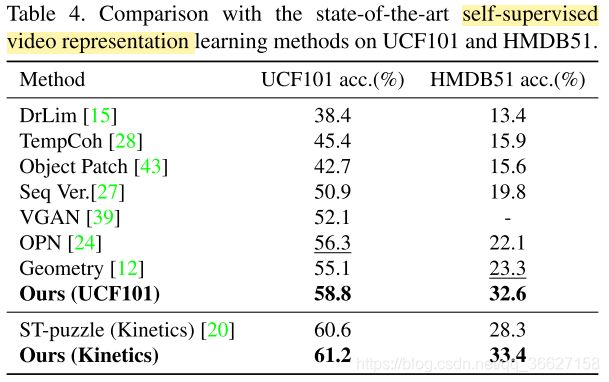
论文标题:Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics(2019 CVPR)
论文作者:Jiangliu Wang, Jianbo Jiao, Linchao Bao, Shengfeng He, Yunhui Liu, Wei Liu
下载地址:https://openaccess.thecvf.com/content_CVPR_2019/html/Wang_Self-Supervised_Spatio-Temporal_Representation_Learning_for_Videos_by_Predicting_Motion_and_CVPR_2019_paper.html
Contributions
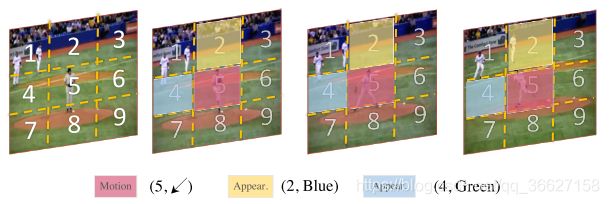
In this paper, we propose a novel self-supervised approach to learn spatio-temporal features for video representation. Inspired by the success of two-stream approaches in video classification, we propose to learn visual features by regressing both motion and appearance statistics along spatial and temporal dimensions, given only the input video data. Specifically, given a video sequence, we design a novel task to predict several numerical labels derived from motion and appearance statistics for spatio-temporal representation learning, in a self-supervised manner. Each video frame is first divided into several spatial regions using different partitioning patterns like the grid. Then the derived statistical labels, such as the region with the largest motion and its direction (the red patch), the most diverged region in appearance and its dominant color (the yellow patch), and the most stable region in appearance and its dominant color (the blue patch), are employed as supervision during the learning. We conduct extensive experiments with C3D to validate the effectiveness of our proposed approach, and the experiments show that our approach can significantly improve the performance ofC3D when applied to video classification tasks.
Method
Inspired by human visual system, we break the process of understanding videos into several questions and encourage a CNN to answer them accordingly:
- Where is the largest motion in the video?
- What is the dominant direction of the largest motion?
- Where is the largest color diversity and what is its dominant color?
- Where is the smallest color diversity, i.e., the potential background of a scene and what is its dominant color?
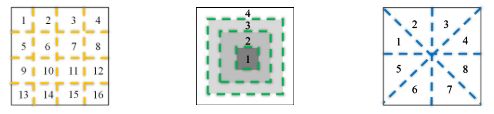
1、Partitioning patterns
Given a video clip, we first divide it into several blocks without overlap using simple patterns.
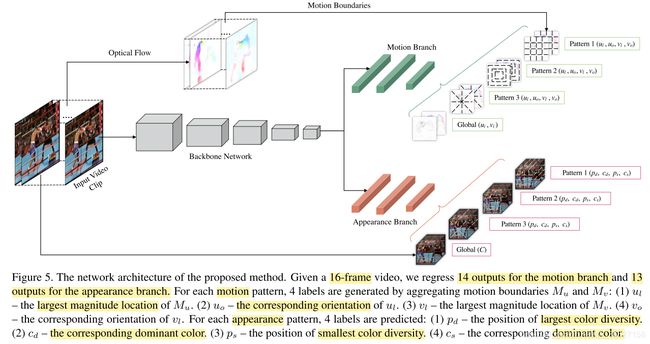
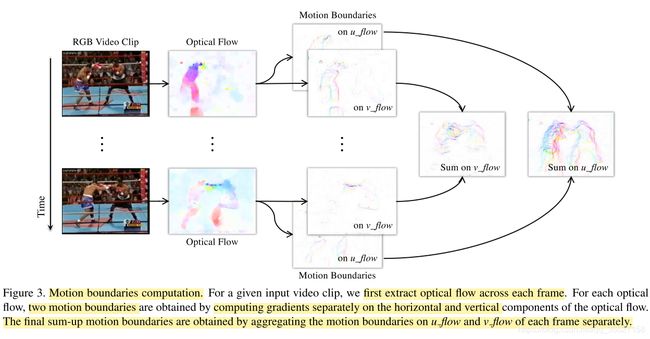
2、Motion Statistics
We use optical flow to derive the motion statistical labels to be predicted in our task. Specifically, for an N-frame video clip, (N − 1) ∗ 2 motion boundaries are computed. Diverse video motion information can be encoded into two summarized motion boundaries by summing up all these (N−1) sparse motion boundaries of each component as follows:
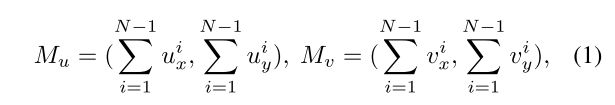
where Mu denotes the motion boundaries on horizontal optical flow u, and Mv denotes the motion boundaries on vertical optical flow v.
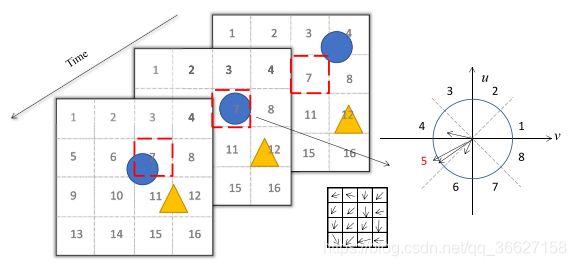
As for the largest motion statistics, we compute the average magnitude of each block and use the number of the block with the largest average magnitude as the largest motion location. We divide 360◦ into 8 bins, with each bin containing 45◦ angle range and again assign each bin to a number to represent its orientation. For each pixel in the largest motion block, we first use its orientation angle to determine which angle bin it belongs to and then add the corresponding magnitude number into the angle bin. The dominant orientation is the number of the angle bin with the largest magnitude sum.
3、Appearance Statistics
Given an N-frame video clip, same as motion statistics, we divide it into several video blocks by patterns described above. For an N-frame video block, we first compute the 3D distribution Vi in 3D color space of each frame i. We then use the In- tersection over Union (IoU) along temporal axis to quantify the spatio-temporal color diversity as follows:

The largest color diversity location is the block with the smallest IoUscore, while the smallest color diversity location is the block with the largest IoUscore. In practice, we calculate the IoUscore on R,G,B channels separately and compute the final IoUscore by averaging them. In the 3-D RGB color space, we evenly divide it into 8 bins. For the two representative video blocks, we assign each pixel a corresponding bin number by its RGB value, and the bin with the largest number of pixels is the dominant color.
Results