- Cool Pi CM5-LAPTOP Linux Quick Start Guide
george-coolpi
linux运维服务器开源arm开发AI编程
MachineIntroductionCOOLPICM5open-sourcenotebookisaproductthatcombineshighperformance,portability,andopen-sourcespirit.Itnotonlymeetsthebasiccomputingneedsofusers,butalsoprovidesanidealplatformforthose
- 第八周 tensorflow实现猫狗识别
降花绘
365天深度学习tensorflow系列tensorflow深度学习人工智能
本文为365天深度学习训练营内部限免文章(版权归K同学啊所有)**参考文章地址:[TensorFlow入门实战|365天深度学习训练营-第8周:猫狗识别(训练营内部成员可读)]**作者:K同学啊文章目录一、本周学习内容:1、自己搭建VGG16网络2、了解model.train_on_batch()3、了解tqdm,并使用tqdm实现可视化进度条二、前言三、电脑环境四、前期准备1、导入相关依赖项2、
- 国产替代Spring Boot框架的最佳之选——Solon
遇码
开发工具springboot后端javasolon
Java很好。SpringBoot也很好。有没有可以与SpringBoot对标的国产框架?请你记住,它叫Solon。本文推荐Solon,是因为我自己的一段经历。我主要使用的开发语言是Python,本着技多不压身的伟大指导思想,很早就想要征服SpringBoot,无奈尝试多次始终不得其要领,也就草草收场。前段时间因为项目需要,偶然了解到Solon,不仅可以平替SpringBoot,还是国产,还有我喜
- Github 2025-01-07Python开源项目日报 Top10
老孙正经胡说
github开源Github趋势分析开源项目PythonGolang
根据GithubTrendings的统计,今日(2025-01-07统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下:开发语言项目数量Python项目10TypeScript项目1C++项目1OpenHands:人工智能驱动的软件开发代理平台创建周期:195天开发语言:Python协议类型:MITLicenseStar数量:31753个Fork数量:3660次关注人数:31753人
- Embabel:下一代企业级JVM AI智能体框架的革命引言:AI时代的Java生态新机遇
DZSpace
软件开发jvm人工智能java
在生成式AI(如ChatGPT、Claude、Gemini)席卷全球的背景下,Python凭借其丰富的AI工具链(如PyTorch、LangChain)成为主流开发语言。然而,在企业级软件开发领域,Java和JVM生态(如Kotlin、Scala)长期以来占据主导地位,尤其是在金融、电信、电商等对稳定性、可扩展性、事务管理要求极高的场景。RodJohnson(Spring框架创始人)敏锐地发现了这
- Spring AI 教程(一)概述
PG Thinker
SpringAISpringChatGPT人工智能springjavaSpringAI
前言 我在23年11月那会儿关注了SpringAI项目,当时我恰好正热衷于大语言模型的开发,然而当时主流的开发语言只有Python,Java生态中并没有强大的框架供我们使用。 我当时也是靠一些封装OpenAI接口的SDK包来玩ChatGPT的,但是整体的体验较差。好在我通过一些技术交流群了解了一个正在处于实验阶段的项目:SpringAI。于是果断前往它的Github仓库进行学习,而我也恰好见证了S
- lstm 输入数据维度_keras中关于输入尺寸、LSTM的stateful问题
weixin_39856269
lstm输入数据维度
补充:return_sequence,return_state都是针对一个时间切片(步长)内的h和c状态,而stateful是针对不同的batch之间的。多层LSTM需要设置return_sequence=True,后面再设置return_sequence=False.最近在学习使用keras搭建LSTM的时候,遇到了一些不明白的地方。有些搞懂了,有些还没有搞懂。现在记下来,因为很快就会忘记!-_
- torch 填充补齐
AI算法网奇
python宝典python
目录行填充补齐1.填充长度(Padding)2.掩码(Masking)3.排序优化(可选)行填充补齐importtorchfromtorch.nn.utils.rnnimportpad_sequence#原始序列(每个序列是二维张量,行数不同)batch_data=[torch.tensor([[1,2,3]])#1行#torch.tensor([[4,5,6],[7,8,9]]),#2行#tor
- lstm 数据输入问题
AI算法网奇
python基础lstm人工智能
lstm我有20*6条数据,20个样本,每个样本6条历史数据,每条数据有5个值,我送给网络输入时应该是20*6*5还是6*20*5你的数据是:20个样本(batchsize=20)每个样本有6条历史数据(sequencelength=6)每条数据有5个值(inputsize=5)✅正确的输入形状是:(20,6,5)#即batch_size=20,seq_len=6,input_size=5前提是你
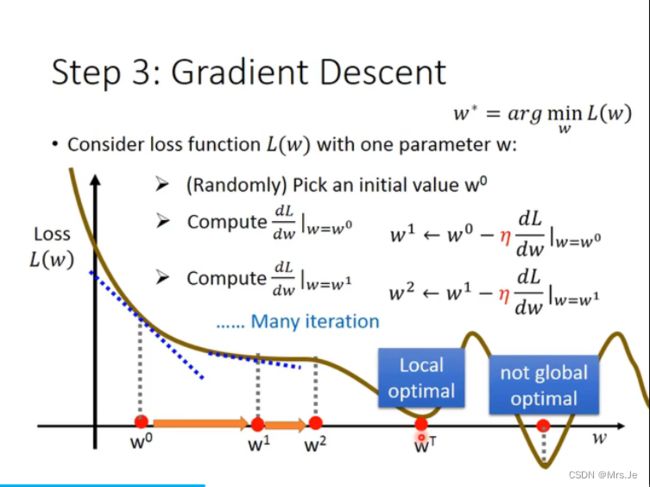
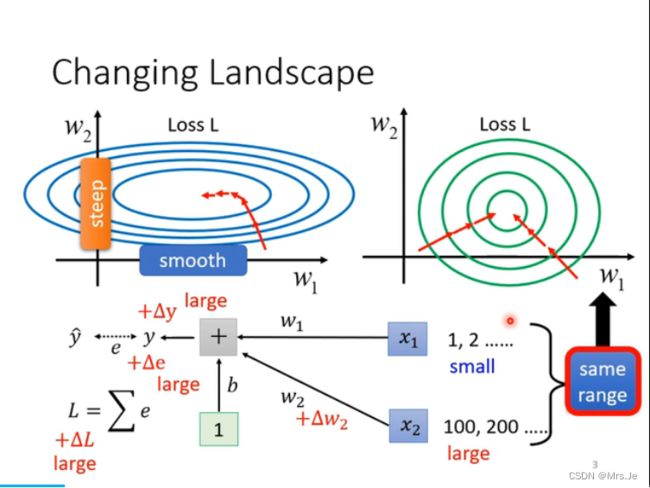
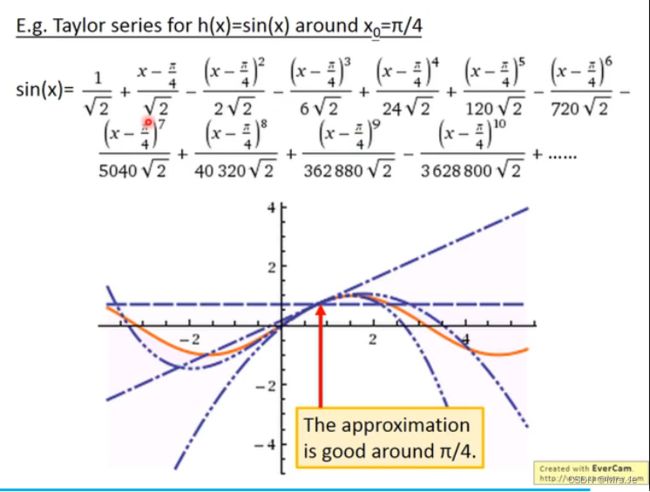
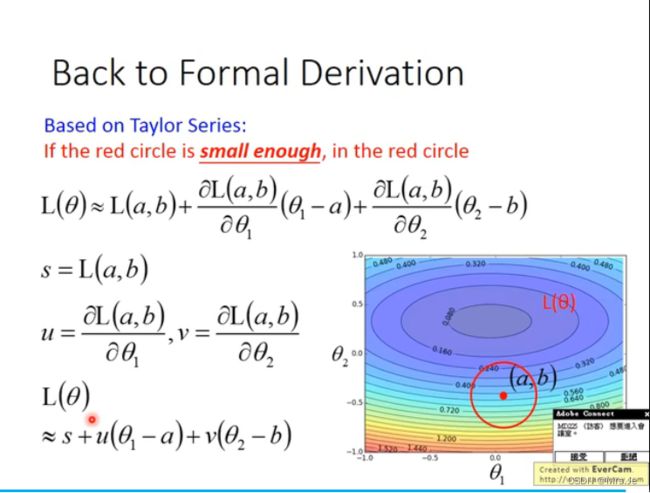
- NLP-D7-李宏毅机器学习---X-Attention&&GAN&BERT&GPT
甄小胖
机器学习自然语言处理机器学习bert
—0521今天4:30就起床了!真的是迫不及待想看新的课程!!!昨天做人脸识别系统的demo查资料的时候,发现一个北理的大四做cv的同学,差距好大!!!我也要努力呀!!不是比较,只是别人可以做到这个程度,我也一定可以!!!要向他学习!!!开始看课程啦!-----0753看完了各种attention,由于attention自己计算的限制,当N很大的时候会产生计算速度问题,从各种不同角度(人工知识输入
- OpenWebUI(8)源码学习-后端utils/telemetry追踪遥测模块
目录目录结构说明`constants.py`核心作用:主要功能:示例代码片段:`exporters.py`核心作用:主要类:`LazyBatchSpanProcessor`特点:技术亮点:`instrumentors.py`核心作用:插桩对象包括:钩子函数(Hooks):Instrumentor类:插桩流程:`setup.py`核心作用:主要功能:典型调用方式:✨总体架构与价值技术亮点总结✅开发建
- 探索Spring Batch的终极指南:高效批处理解决方案
水照均Farrah
探索SpringBatch的终极指南:高效批处理解决方案def-guide-spring-batchSourceCodeforTheDefinitiveGuidetoSpringBatchbyMichaelMinella项目地址:https://gitcode.com/gh_mirrors/de/def-guide-spring-batch项目介绍欢迎来到《TheDefinitiveGuideto
- huggingface 笔记: Trainer
UQI-LIUWJ
笔记人工智能
Trainer是一个为Transformers中PyTorch模型设计的完整训练与评估循环只需将模型、预处理器、数据集和训练参数传入Trainer,其余交给它处理,即可快速开始训练自动处理以下训练流程:根据batch计算loss使用backward()计算梯度根据梯度更新权重重复上述流程直到达到指定的epoch数1配置TrainingArguments使用TrainingArguments定义训练
- RustFS:基于Rust的对象存储系统技术解析
光爷不秃
对象存储rust国产开源软件云计算rust数据库开源软件
在数据存储技术快速发展的当下,各类对象存储解决方案不断涌现。本文将从技术特性、功能设计等角度,对基于Rust语言开发的开源对象存储系统RustFS进行客观解析,为关注存储技术的读者提供参考。项目基本信息RustFS是一个开源对象存储系统,其核心目标是构建高性能、高可靠的数据存储架构。该项目选择Rust作为开发语言,主要利用了这门语言在内存安全和运行效率上的特性,同时通过兼容S3API的设计,降低了
- 科研:diffusion生成MNIST程序实现
Menger_Wen
科研:diffusion人工智能机器学习stablediffusionpython
科研:diffusion生成MNIST程序实现第一部分:填写部分的详细解释1.`diffusion.py`中的`batch_extend_like`方法2.`diffusion.py`中的`ode_reverse`方法3.`sde_schedule.py`中的`sde_forward`方法第二部分:逐行解释两个程序1.`diffusion.py`(Diffusion类)`__init__`方法`b
- 【零基础学AI】第33讲:强化学习基础 - 游戏AI智能体
1989
0基础学AI人工智能游戏transformer分类深度学习神经网络
本节课你将学到理解强化学习的基本概念和框架掌握Q-learning算法原理使用Python实现贪吃蛇游戏AI训练能够自主玩游戏的智能体开始之前环境要求Python3.8+PyTorch2.0+Gymnasium(原OpenAIGym)NumPyMatplotlib推荐使用JupyterNotebook进行实验前置知识Python基础编程(第1-8讲)基本数学概念(函数、导数)神经网络基础(第23讲
- PagedAttention和Continuous Batching
流浪大人
大模型深度学习人工智能机器学习
PagedAttention是什么PagedAttention是一种用于优化Transformer架构中注意力机制的技术,主要用于提高大语言模型在推理阶段的效率,特别是在处理长序列数据时能有效减少内存碎片和提高内存利用率。它借鉴了操作系统中虚拟内存分页机制的思想。工作原理传统注意力机制的局限性:传统的注意力机制在处理长序列时,需要为每个位置计算注意力得分并存储中间结果,这会导致内存占用随着序列长度
- 一文读懂Python+Pytest+Allure+Jenkins+Gitee自动化测试框架,手把手教你搭建
Python+Pytest+Allure+Jenkins+Gitee自动化测试框架一、框架整体架构1.技术栈分工Python:测试脚本开发语言Pytest:测试用例管理和执行引擎Allure:测试报告生成与展示Jenkins:持续集成和任务调度Gitee:代码版本管理和触发机制2.数据流向Gitee代码提交→Jenkins触发构建→Pytest执行用例→生成Allure结果→Jenkins收集报告
- 2025——》import matplotlib.pyplot as plt/如何在Jupyter Notebook中使用Matplotlib库?
明—猿
NumPyjupytermatplotlibnumpyjupyter
importmatplotlib.pyplotasplt是Python中用于导入Matplotlib库的绘图模块pyplot并设置别名为plt的标准语句。Matplotlib是一个强大的可视化库,广泛用于数据可视化、图表绘制和科学绘图。以下是关于该语句的详细说明:一、语句解析importmatplotlib.pyplotmatplotlib是基础库,pyplot是其子模块,提供类似MATLAB的绘
- QueryBook常见问题解答:从查询失败到数据文档管理的完整指南
汤力赛Frederica
QueryBook常见问题解答:从查询失败到数据文档管理的完整指南querybookQuerybookisaBigDataQueryingUI,combiningcollocatedtablemetadataandasimplenotebookinterface.项目地址:https://gitcode.com/gh_mirrors/qu/querybook查询执行问题排查当您在QueryBook
- QueryBook项目中的查询引擎支持与集成指南
倪俊炼
QueryBook项目中的查询引擎支持与集成指南querybookQuerybookisaBigDataQueryingUI,combiningcollocatedtablemetadataandasimplenotebookinterface.项目地址:https://gitcode.com/gh_mirrors/qu/querybook概述QueryBook作为一个数据查询与分析平台,其核心功
- Python在人工智能领域的实际应用:示例代码解析
辣条yyds
pythonpython人工智能开发语言
摘要:本文将通过几个典型的人工智能应用场景,展示Python在图像识别、自然语言处理、推荐系统等方面的高级用法。通过示例代码,带大家深入理解Python在人工智能领域的实际应用。正文:Python作为一门流行的编程语言,凭借其简洁的语法、丰富的库和框架,成为了人工智能(AI)领域的主流开发语言。下面,我们将通过几个示例,探讨Python在人工智能方向的实际应用。示例一:图像识别-使用OpenCV进
- Github 2024-05-07 开源项目日报 Tp10
老孙正经胡说
github开源Github趋势分析开源项目PythonGolang
根据GithubTrendings的统计,今日(2024-05-07统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下:开发语言项目数量TypeScript项目4JupyterNotebook项目2Python项目1Batchfile项目1非开发语言项目1Java项目1HTML项目1C#项目1从零开始构建你喜爱的技术创建周期:2156天Star数量:253338个Fork数量:240
- Github 2024-07-07 开源项目日报 Top10
老孙正经胡说
github开源Github趋势分析开源项目PythonGolang
根据GithubTrendings的统计,今日(2024-07-07统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下:开发语言项目数量Python项目4Rust项目2C项目2C++项目1JavaScript项目1HTML项目1JupyterNotebook项目1非开发语言项目1免费编程书籍和学习资源清单创建周期:3762天协议类型:CreativeCommonsAttributio
- java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试
木林网络
mybatisjava数据库
java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试本源码技术栈:项目架构:B/S架构开发语言:Java语言开发软件:ideaeclipse前端技术:Layui、HTML、CSS、JS、JQuery等技术后端技术:JAVA运行环境:Win10、
- 更换SSL证书引发的异常:`sun.security.validator.ValidatorException: PKIX path building failed` `[Nginx跳转失败:501]
猿享天开
技术经验sslnginx网络协议
博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++,C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQLserver,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,
- 1.线性神经网络--线性回归
温柔济沧海
深度学习神经网络线性回归python
1.1从零实现线性回归importrandomimporttorch#fromd2limporttorchasd2limportmatplotlib.pyplotaspltdeftrain_data_make(batch_size,X,y):num_examples=len(X)idx=list(range(num_examples))#生成0-999random.shuffle(idx)#样本需
- Github 2025-07-05 Rust开源项目日报Top10
老孙正经胡说
githubrust开源Github趋势分析开源项目PythonGolang
根据GithubTrendings的统计,今日(2025-07-05统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下:开发语言项目数量Rust项目10TypeScript项目1uv:极快的Python软件包安装程序和解析器创建周期:147天开发语言:Rust协议类型:ApacheLicense2.0Star数量:7066个Fork数量:200次关注人数:7066人贡献人数:45人O
- 支持向量机(SVM)在肝脏CT/MRI图像分类(肝癌检测)中的应用及实现
猿享天开
医学影像支持向量机机器学习人工智能算法
博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++,C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQLserver,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,
- 2020-10-30
Victor Zhong
AI框架人工智能深度学习机器学习
极片缺陷检测模型验证报告:1:数据准备训练集:326张验证集:81张2:模型准备模型:yolov33:训练参数设置epochs:4603batch_size:8device:RTX2080Ticfg:yolov3-spp-jp4:验证结果5:检测结果部分检测结果图,全部结果图见文件夹result:6:结果分析a.训练数据中,某一类缺陷标注数量相对较少,影响检测该类的目标;可以通过数据增强的方法或增
- 遍历dom 并且存储(将每一层的DOM元素存在数组中)
换个号韩国红果果
JavaScripthtml
数组从0开始!!
var a=[],i=0;
for(var j=0;j<30;j++){
a[j]=[];//数组里套数组,且第i层存储在第a[i]中
}
function walkDOM(n){
do{
if(n.nodeType!==3)//筛选去除#text类型
a[i].push(n);
//con
- Android+Jquery Mobile学习系列(9)-总结和代码分享
白糖_
JQuery Mobile
目录导航
经过一个多月的边学习边练手,学会了Android基于Web开发的毛皮,其实开发过程中用Android原生API不是很多,更多的是HTML/Javascript/Css。
个人觉得基于WebView的Jquery Mobile开发有以下优点:
1、对于刚从Java Web转型过来的同学非常适合,只要懂得HTML开发就可以上手做事。
2、jquerym
- impala参考资料
dayutianfei
impala
记录一些有用的Impala资料
1. 入门资料
>>官网翻译:
http://my.oschina.net/weiqingbin/blog?catalog=423691
2. 实用进阶
>>代码&架构分析:
Impala/Hive现状分析与前景展望:http
- JAVA 静态变量与非静态变量初始化顺序之新解
周凡杨
java静态非静态顺序
今天和同事争论一问题,关于静态变量与非静态变量的初始化顺序,谁先谁后,最终想整理出来!测试代码:
import java.util.Map;
public class T {
public static T t = new T();
private Map map = new HashMap();
public T(){
System.out.println(&quo
- 跳出iframe返回外层页面
g21121
iframe
在web开发过程中难免要用到iframe,但当连接超时或跳转到公共页面时就会出现超时页面显示在iframe中,这时我们就需要跳出这个iframe到达一个公共页面去。
首先跳转到一个中间页,这个页面用于判断是否在iframe中,在页面加载的过程中调用如下代码:
<script type="text/javascript">
//<!--
function
- JAVA多线程监听JMS、MQ队列
510888780
java多线程
背景:消息队列中有非常多的消息需要处理,并且监听器onMessage()方法中的业务逻辑也相对比较复杂,为了加快队列消息的读取、处理速度。可以通过加快读取速度和加快处理速度来考虑。因此从这两个方面都使用多线程来处理。对于消息处理的业务处理逻辑用线程池来做。对于加快消息监听读取速度可以使用1.使用多个监听器监听一个队列;2.使用一个监听器开启多线程监听。
对于上面提到的方法2使用一个监听器开启多线
- 第一个SpringMvc例子
布衣凌宇
spring mvc
第一步:导入需要的包;
第二步:配置web.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi=
- 我的spring学习笔记15-容器扩展点之PropertyOverrideConfigurer
aijuans
Spring3
PropertyOverrideConfigurer类似于PropertyPlaceholderConfigurer,但是与后者相比,前者对于bean属性可以有缺省值或者根本没有值。也就是说如果properties文件中没有某个bean属性的内容,那么将使用上下文(配置的xml文件)中相应定义的值。如果properties文件中有bean属性的内容,那么就用properties文件中的值来代替上下
- 通过XSD验证XML
antlove
xmlschemaxsdvalidationSchemaFactory
1. XmlValidation.java
package xml.validation;
import java.io.InputStream;
import javax.xml.XMLConstants;
import javax.xml.transform.stream.StreamSource;
import javax.xml.validation.Schem
- 文本流与字符集
百合不是茶
PrintWrite()的使用字符集名字 别名获取
文本数据的输入输出;
输入;数据流,缓冲流
输出;介绍向文本打印格式化的输出PrintWrite();
package 文本流;
import java.io.FileNotFound
- ibatis模糊查询sqlmap-mapping-**.xml配置
bijian1013
ibatis
正常我们写ibatis的sqlmap-mapping-*.xml文件时,传入的参数都用##标识,如下所示:
<resultMap id="personInfo" class="com.bijian.study.dto.PersonDTO">
<res
- java jvm常用命令工具——jdb命令(The Java Debugger)
bijian1013
javajvmjdb
用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。
现在应该说日常的开发中很少用到JDB了,因为现在的IDE已经帮我们封装好了,如使用ECLI
- 【Spring框架二】Spring常用注解之Component、Repository、Service和Controller注解
bit1129
controller
在Spring常用注解第一步部分【Spring框架一】Spring常用注解之Autowired和Resource注解(http://bit1129.iteye.com/blog/2114084)中介绍了Autowired和Resource两个注解的功能,它们用于将依赖根据名称或者类型进行自动的注入,这简化了在XML中,依赖注入部分的XML的编写,但是UserDao和UserService两个bea
- cxf wsdl2java生成代码super出错,构造函数不匹配
bitray
super
由于过去对于soap协议的cxf接触的不是很多,所以遇到了也是迷糊了一会.后来经过查找资料才得以解决. 初始原因一般是由于jaxws2.2规范和jdk6及以上不兼容导致的.所以要强制降为jaxws2.1进行编译生成.我们需要少量的修改:
我们原来的代码
wsdl2java com.test.xxx -client http://.....
修改后的代
- 动态页面正文部分中文乱码排障一例
ronin47
公司网站一部分动态页面,早先使用apache+resin的架构运行,考虑到高并发访问下的响应性能问题,在前不久逐步开始用nginx替换掉了apache。 不过随后发现了一个问题,随意进入某一有分页的网页,第一页是正常的(因为静态化过了);点“下一页”,出来的页面两边正常,中间部分的标题、关键字等也正常,唯独每个标题下的正文无法正常显示。 因为有做过系统调整,所以第一反应就是新上
- java-54- 调整数组顺序使奇数位于偶数前面
bylijinnan
java
import java.util.Arrays;
import java.util.Random;
import ljn.help.Helper;
public class OddBeforeEven {
/**
* Q 54 调整数组顺序使奇数位于偶数前面
* 输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半
- 从100PV到1亿级PV网站架构演变
cfyme
网站架构
一个网站就像一个人,存在一个从小到大的过程。养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原则。本文结合我自已14年网站人的经历记录一些架构演变中的体会。 1:积累是必不可少的
架构师不是一天练成的。
1999年,我作了一个个人主页,在学校内的虚拟空间,参加了一次主页大赛,几个DREAMWEAVER的页面,几个TABLE作布局,一个DB连接,几行PHP的代码嵌入在HTM
- [宇宙时代]宇宙时代的GIS是什么?
comsci
Gis
我们都知道一个事实,在行星内部的时候,因为地理信息的坐标都是相对固定的,所以我们获取一组GIS数据之后,就可以存储到硬盘中,长久使用。。。但是,请注意,这种经验在宇宙时代是不能够被继续使用的
宇宙是一个高维时空
- 详解create database命令
czmmiao
database
完整命令
CREATE DATABASE mynewdb USER SYS IDENTIFIED BY sys_password USER SYSTEM IDENTIFIED BY system_password LOGFILE GROUP 1 ('/u01/logs/my/redo01a.log','/u02/logs/m
- 几句不中听却不得不认可的话
datageek
1、人丑就该多读书。
2、你不快乐是因为:你可以像猪一样懒,却无法像只猪一样懒得心安理得。
3、如果你太在意别人的看法,那么你的生活将变成一件裤衩,别人放什么屁,你都得接着。
4、你的问题主要在于:读书不多而买书太多,读书太少又特爱思考,还他妈话痨。
5、与禽兽搏斗的三种结局:(1)、赢了,比禽兽还禽兽。(2)、输了,禽兽不如。(3)、平了,跟禽兽没两样。结论:选择正确的对手很重要。
6
- 1 14:00 PHP中的“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误
dcj3sjt126com
PHP
原文地址:http://www.kafka0102.com/2010/08/281.html
因为需要,今天晚些在本机使用PHP做些测试,PHP脚本依赖了一堆我也不清楚做什么用的库。结果一跑起来,就报出类似下面的错误:“Parse error: syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM in /home/kafka/test/
- xcode6 Auto layout and size classes
dcj3sjt126com
ios
官方GUI
https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/AutolayoutPG/Introduction/Introduction.html
iOS中使用自动布局(一)
http://www.cocoachina.com/ind
- 通过PreparedStatement批量执行sql语句【sql语句相同,值不同】
梦见x光
sql事务批量执行
比如说:我有一个List需要添加到数据库中,那么我该如何通过PreparedStatement来操作呢?
public void addCustomerByCommit(Connection conn , List<Customer> customerList)
{
String sql = "inseret into customer(id
- 程序员必知必会----linux常用命令之十【系统相关】
hanqunfeng
Linux常用命令
一.linux快捷键
Ctrl+C : 终止当前命令
Ctrl+S : 暂停屏幕输出
Ctrl+Q : 恢复屏幕输出
Ctrl+U : 删除当前行光标前的所有字符
Ctrl+Z : 挂起当前正在执行的进程
Ctrl+L : 清除终端屏幕,相当于clear
二.终端命令
clear : 清除终端屏幕
reset : 重置视窗,当屏幕编码混乱时使用
time com
- NGINX
IXHONG
nginx
pcre 编译安装 nginx
conf/vhost/test.conf
upstream admin {
server 127.0.0.1:8080;
}
server {
listen 80;
&
- 设计模式--工厂模式
kerryg
设计模式
工厂方式模式分为三种:
1、普通工厂模式:建立一个工厂类,对实现了同一个接口的一些类进行实例的创建。
2、多个工厂方法的模式:就是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式就是提供多个工厂方法,分别创建对象。
3、静态工厂方法模式:就是将上面的多个工厂方法模式里的方法置为静态,
- Spring InitializingBean/init-method和DisposableBean/destroy-method
mx_xiehd
javaspringbeanxml
1.initializingBean/init-method
实现org.springframework.beans.factory.InitializingBean接口允许一个bean在它的所有必须属性被BeanFactory设置后,来执行初始化的工作,InitialzingBean仅仅指定了一个方法。
通常InitializingBean接口的使用是能够被避免的,(不鼓励使用,因为没有必要
- 解决Centos下vim粘贴内容格式混乱问题
qindongliang1922
centosvim
有时候,我们在向vim打开的一个xml,或者任意文件中,拷贝粘贴的代码时,格式莫名其毛的就混乱了,然后自己一个个再重新,把格式排列好,非常耗时,而且很不爽,那么有没有办法避免呢? 答案是肯定的,设置下缩进格式就可以了,非常简单: 在用户的根目录下 直接vi ~/.vimrc文件 然后将set pastetoggle=<F9> 写入这个文件中,保存退出,重新登录,
- netty大并发请求问题
tianzhihehe
netty
多线程并发使用同一个channel
java.nio.BufferOverflowException: null
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:183) ~[na:1.7.0_60-ea]
at java.nio.ByteBuffer.put(ByteBuffer.java:832) ~[na:1.7.0_60-ea]
- Hadoop NameNode单点问题解决方案之一 AvatarNode
wyz2009107220
NameNode
我们遇到的情况
Hadoop NameNode存在单点问题。这个问题会影响分布式平台24*7运行。先说说我们的情况吧。
我们的团队负责管理一个1200节点的集群(总大小12PB),目前是运行版本为Hadoop 0.20,transaction logs写入一个共享的NFS filer(注:NetApp NFS Filer)。
经常遇到需要中断服务的问题是给hadoop打补丁。 DataNod