TextCNN
TextCNN
感觉以前自己写的好辣鸡,引起现在我的极度不适
TextCNN中有个难点就是一维卷积:Conv1d
介绍一下pytorch中的nn.Conv1d
Class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
- in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度
- out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
- kernel_size(int or tuple) -卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
- stride(int or tuple, optional) - 卷积步长
- padding (int or tuple, optional)- 输入的每一条边补充0的层数
- dilation(int or tuple, `optional``) – 卷积核元素之间的间距
- groups(int, optional) – 从输入通道到输出通道的阻塞连接数
- bias(bool, optional) - 如果bias=True,添加偏置
基于神经网络的文本分类
《Convolutional Neural Networks for Sentence Classification》
—基于卷积神经网络的句子分类
作者:Yoon Kim
单位:New York University
发表会议及时间:EMNLP 2014
本篇文章是卷积神经网络作为文本分类的开山之作,极大推动了CNN在NLP领域的发展
- 1.一 论文导读
- 2.二 论文精读
- 3.三 代码实现
- 4.四 问题思索
一 论文导读
1.文本分类的简介
2.卷积神经网络相关技术
1.文本分类的简介
文本分类,指的是给定分类体系,将文本分类到某个或者某几个类别中。
根据其目标类别的数量,文本分类涵盖了二分类、多分类、多标签分类等常见分类场景。
文本分类任务是计算机语言学的一个分支,同时也是自然语言处理中最基础的任务。涵盖了新闻主题分类,情感分类,关系分类,意图识别等等,是具有重大的理论意义和应用价值。
文本分类中的关键问题在于文本表示,文本表示指的是,通过某种方式将自然语言文本编码成计算机可以处理的形式,向量。
主要有两种方式:1.基于独热的词袋子文本表示,2.基于词嵌入的文本表示

文本分类发展历史
基于规则的文本分类 --》基于特征的文本分类 --》 基于神经网络的文本分类
趋势:对文本中的关键信息捕获的更准确
一 基于规则的文本分类
基本思想:使用人工编写的特定规则进行分类,一般情况下,含有特定的词语、短语或者模式时就将其判断为相应的类别,是最早和最简单的一种分类方法。
大体流程:输入文本–》规则匹配–》输出类别
二 基于特征的文本分类
基本思想:通过人工设计和提取,例如:词法特征、句法特征等,使用机器学习模型来捕获句子中所蕴涵的关键信息,从而来减少噪声对最终结果的影响。
以空间向量模型为例:
- 使用词袋子模型来表示每个词
- 使用词项作为特征项,使用词在文档中的TF-IDF值作为词的权重(特征权重)
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- 使用加权求和得到文本表示
- 训练一个分类器(LR\SVM )进行文本分类
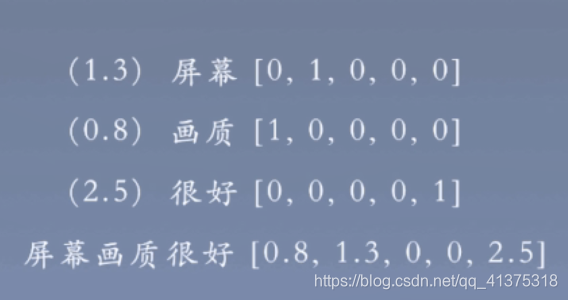
三 基于神经网络的文本分类
基本思想:首先将输入的文本进行分词等一系列基础操作,随后将句子中的单词转化为低维的词表示,使用编码器(卷积神经网络、循环神经网络)得到句子表示,最终得到文本的目标类别。
大体流程:输入文本–》词表示–》编码器–》文本表示–》输出类别
总结:
基于规则的文本分类方法:
优点:易于实现、无需训练数据
缺点:人工成本较高,效果较差
基于特征的文本分类方法:
优点:易于复用、能够进行信息的筛选
缺点:人工提取特征的成本很高
基于神经网络的文本分类方法:
优点:无需人工特征、一般效果较好
缺点:可解释性差、训练资源消耗大
2.卷积神经网络相关技术
卷积神经网络:多层感知机是一种全连接结构,但是全连接的网路会存在一定的冗余,卷积神经网络通过局部连接和权重共享的方法来实现对多层感知机的共享。
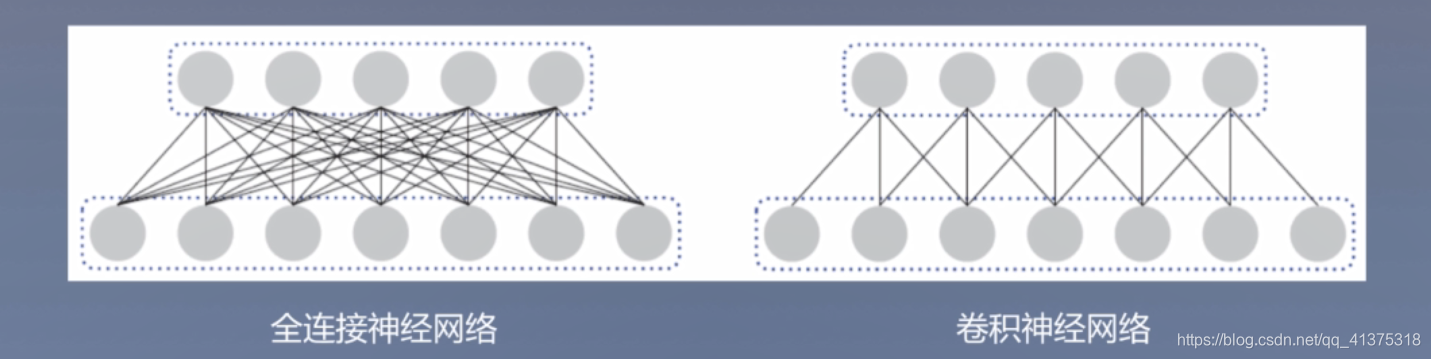
具体操作:
卷积操作
池化操作:池化本身是一种降采样操作,用于降低维度并保留有效信息。
- 减少模型参数,避免过拟合,提高训练速度
- 保证特征的位置、旋转、伸缩不变性(cv方向)
- 将变长的输入转换为固定长度的输入(NLP方向)
二 论文精读
1.论文整体框架
2.传统和经典的方法
3.论文提出的模型
4.实验和结果
5.讨论和总结
1.论文整体框架
0.摘要
1.引言
2.模型
3.数据集和实验设置
4.实验结果和讨论
5.结论
2.传统和经典的方法
基于规则的文本分类方法:
优点:易于实现、无需训练数据
缺点:人工成本较高,效果较差
基于特征的文本分类方法:
优点:易于复用、能够进行信息的筛选
缺点:人工提取特征的成本很高
基于神经网络的文本分类方法:
优点:无需人工特征、一般效果较好
缺点:可解释性差、训练资源消耗大
3.论文提出的模型
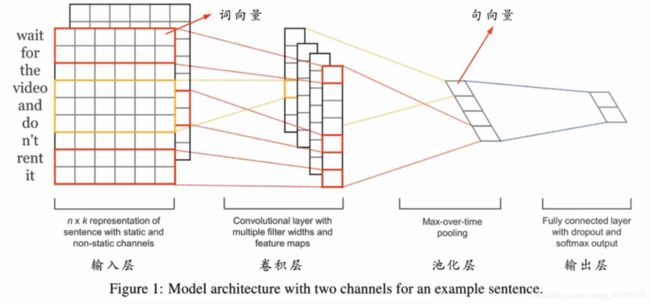
模型结构
下面这张图是最重要的,需要学习者准确无误的了解。
现在再看,emmmm,自己写的解说好垃圾!!!!还是看图就行
- 分四层,输入层–》卷积层–》池化层–》输出层
- 输入层是词的向量表示,卷积层提出特征,池化层进程聚合,最后进过全连接和softmax来进行输出文本的类别
- 输入层,一行代表一个词,有k个值,k也就是embeding词向量的维度,本文中是300,也就是说,一个词用300维的向量表示,一句话按顺序从上到下进行排列。一句话最多有n个词,这里文章中n是64,如果有句子不满64,则用zero padding的方法,即补0
- 下图略有欺骗性,可以先忽视途中黄色线框,只看红色,红色的卷积核大小为
2*6(其实是2*300),但一般会说卷积窗口大小为2,在下图中计算是有错误的,如果红色卷积核的大小为2,步幅为1,则最后应该得到1*8的一维向量,但是图中是1*7的,虽然这无伤大雅。 - 这时,你如果还在意黄色线框,则可以忽略红色线框进行查看,你就会发现,下图还略显合理,因为窗口大小为3的黄卷积核得出的特征图确实要比红色少一格。
- 接着我们继续忽略黄色框,只看红色,就发现一维的特征图,经过池化后得到一个标量(但经过多个卷积核组合起来后是一维向量),池化操作涵盖了一句话的所有词,因而这个标量就代表了这句话。
- 下面就是难点了,一般有困惑就在这里,就像上面说的,既然一个标量就已经代表一句话了,为什么用下图中的
1*4的一维向量去进行分类,其实,下图中的输入层别看是两张n*k的二维矩阵,其实代表的是同一句话,同一句话,同一句话,经过不同大小的卷积核得到多个特征图,从而得到多个标量(代表了这句话),然后把这几个标量进行组合得到句向量(为什么要多个卷积核,因为要获取更多的特征) - 最后再进行全连接进而进行softmax进行分类
- 再做补充:随着卷积层的加深,其实可以获取更多句中词与词之间的联系,这也是后来有文章的创新点,这也体现了深度学习的特点,深度学习的最大特点就是深,特别是在卷积神经网络方面,更特别是在图像方面。
一 输入层
第i个词表示:一个k维实值向量
长度为n的序列表示:
其中的符号为拼接操作,n为最大维度,如果小于n的句子,则补充为全0向量

二 卷积层
卷积操作
上述公式表示使用窗口大小为h的滤波器
得到特征图
即当前滤波器所有输出的拼接
一个滤波器得到一个结果,通常我们会使用多个滤波器(调整感受野)来捕获多种特征
三 输出层
全连接层
将句子向量转化为一个维度和类别相同的数量
随机失活(dropout)
r是失活向量,以一定概率取值为1,否则取值为0
4.实验和结果
数据集
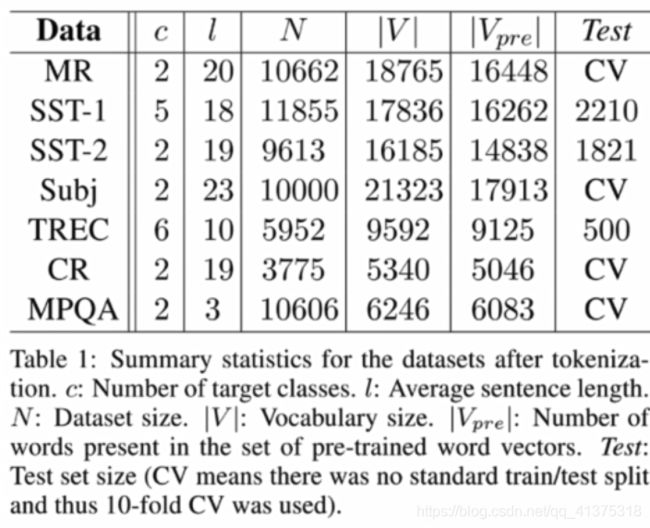
MR:电影评论极性判断数据集(正负极性两个类别)
SST-1:斯坦福情感分类标准数据集
SST-2:斯坦福情感二分类数据集
Subj:主客观判断数据集
TREC:TREC问题类型数据集
CR:商品评价性判断数据集
MOQA: MPQA的观点极性判断数据集
实验设置:

词向量参数会在训练时进行优化
实验结果:
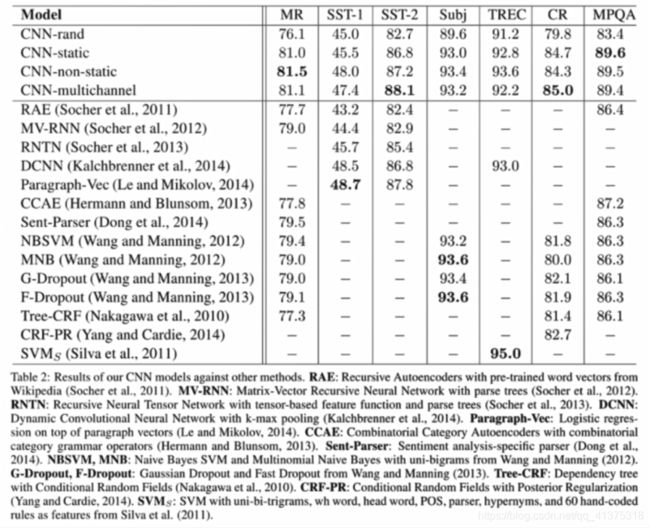
结论:
- 实验对比了之前基于机器学习和人工特征的方法。整体来看,随机初始化词向量(CNN-rand)的方法性能不好,而使用预训练词向量的方法普遍较好。
- CNN-multichannel在小规模的数据集上有更好的表现,体现了一种折中思想,即不希望微调后的词向量距离原始值太远,有允许有一定的变化。
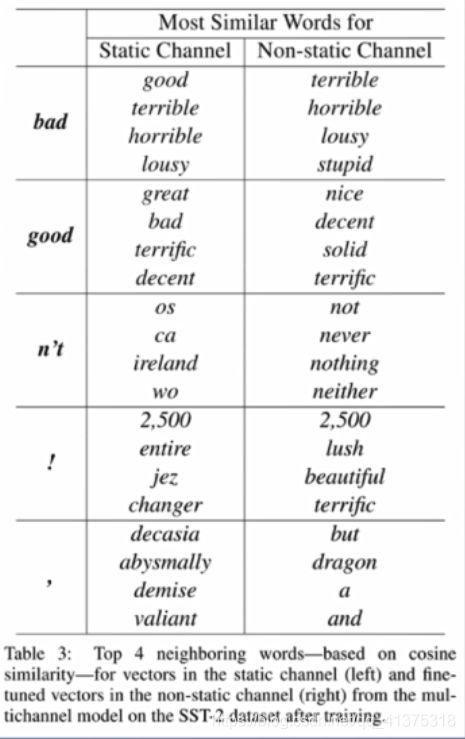
3. 原始词向量训练结果中,bad对应最相近的词为good,因为其上下文语境是极其类似的;在non-static的版本中,bad对应相似的词为terrible,因为在微调的过程中,词向量值发生变化,从而更加贴近数据集
4. 句子中!最接近较为激进的词汇,如lush等,而‘,’更接近于连接词
5.讨论和总结
- 开创性地使用神经网络来解决文本分类问题
- 进行充分的实验分析,探讨词向量对模型性能的影响
- 探讨神经网络中的一些操作对当前文本分类任务的影响
推荐相关论文:
- 《A Sensitivity Analysis of Convolutional Nerual Networks for Sentence Classification》
作者:Ye zhang and Byron C. Wallace
发表会议与时间 IJCNLP 2017
较充分探讨了cnn在文本分类任务上的各种情况,实验分析、挑战指导
三 代码实现
源代码网址:https://github.com/galsang/CNN-sentence-classification-pytorch
1.回顾
2.准备工作
3.数据预处理
4.训练模型
5.测试模型
6.讨论与总结
1.回顾
基于卷积神经网络的文本分类模型(TextCNN)
- 词向量分别使用预训练固定、预训练微调和随机初始化三种方案
- 分析预训练微调后的词向量和原始预训练词向量的差异
- TextCNN:
卷积模型:使用不同大小的滤波器
全连接层:dropout
2.准备工作
注意要有GPU
运行代码
python run.py --gpu 0 --dataset MR --save_mode True

数据集链接中包含了上诉7个数据集,本实验只采用第一个数据集
3.数据预处理
3.1 读取数据集MR
def read_MR():
data = {}
x, y = [], []
with open("data/MR/rt-polarity.pos", "r", encoding="utf-8") as f:
for line in f: # 逐行添加
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(1) # 添加groudtruth
with open("data/MR/rt-polarity.neg", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(0) # 添加groudtruth
3.2划分训练集、验证集、测试集
x, y = shuffle(x, y) # shuffle是一种打乱操作,一定程度可以提高精确度,看不懂不重要
dev_idx = len(x) // 10 * 8
test_idx = len(x) // 10 * 9
data["train_x"], data["train_y"] = x[:dev_idx], y[:dev_idx] # 训练集
data["dev_x"], data["dev_y"] = x[dev_idx:test_idx], y[dev_idx:test_idx] # 验证集
data["test_x"], data["test_y"] = x[test_idx:], y[test_idx:] # 测试集
return data
4.训练模型
1.加载词向量和处理UNK 和 PAD
if params["MODEL"] != "rand":
# load word2vec
print("loading word2vec...")
word_vectors = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
wv_matrix = []
for i in range(len(data["vocab"])):
word = data["idx_to_word"][i]
if word in word_vectors.vocab:
wv_matrix.append(word_vectors.word_vec(word))
else:
wv_matrix.append(np.random.uniform(-0.01, 0.01, 300).astype("float32"))
# one for UNK and one for zero padding
wv_matrix.append(np.random.uniform(-0.01, 0.01, 300).astype("float32"))
wv_matrix.append(np.zeros(300).astype("float32"))
wv_matrix = np.array(wv_matrix)
params["WV_MATRIX"] = wv_matrix
2.初始化相关参数
class CNN(nn.Module):
def __init__(self, **kwargs):
super(CNN, self).__init__()
self.MODEL = kwargs["MODEL"] # 模型状态
self.BATCH_SIZE = kwargs["BATCH_SIZE"] # batch大小
self.MAX_SENT_LEN = kwargs["MAX_SENT_LEN"] # 最长句子长度
self.WORD_DIM = kwargs["WORD_DIM"] # 词向量维度
self.VOCAB_SIZE = kwargs["VOCAB_SIZE"] # 字典大小
self.CLASS_SIZE = kwargs["CLASS_SIZE"] # 类别总数
self.FILTERS = kwargs["FILTERS"] # 滤波器宽度(感受野)
self.FILTER_NUM = kwargs["FILTER_NUM"] # 滤波器个数
self.DROPOUT_PROB = kwargs["DROPOUT_PROB"] #dropout概率
self.IN_CHANNEL = 1 # 词向量类型数
3.初始化卷积层和全连接层
# one for UNK and one for zero padding
self.embedding = nn.Embedding(self.VOCAB_SIZE + 2, self.WORD_DIM, padding_idx=self.VOCAB_SIZE + 1)
if self.MODEL == "static" or self.MODEL == "non-static" or self.MODEL == "multichannel":
self.WV_MATRIX = kwargs["WV_MATRIX"]
self.embedding.weight.data.copy_(torch.from_numpy(self.WV_MATRIX))
if self.MODEL == "static":
self.embedding.weight.requires_grad = False
elif self.MODEL == "multichannel":
self.embedding2 = nn.Embedding(self.VOCAB_SIZE + 2, self.WORD_DIM, padding_idx=self.VOCAB_SIZE + 1)
self.embedding2.weight.data.copy_(torch.from_numpy(self.WV_MATRIX))
self.embedding2.weight.requires_grad = False
self.IN_CHANNEL = 2
for i in range(len(self.FILTERS)):
conv = nn.Conv1d(self.IN_CHANNEL, self.FILTER_NUM[i], self.WORD_DIM * self.FILTERS[i], stride=self.WORD_DIM)
setattr(self, f'conv_{i}', conv)
self.fc = nn.Linear(sum(self.FILTER_NUM), self.CLASS_SIZE)

4.输入层+卷积层+池化层+输出层
def get_conv(self, i):
return getattr(self, f'conv_{i}')
def forward(self, inp):
x = self.embedding(inp).view(-1, 1, self.WORD_DIM * self.MAX_SENT_LEN)
if self.MODEL == "multichannel":
x2 = self.embedding2(inp).view(-1, 1, self.WORD_DIM * self.MAX_SENT_LEN)
x = torch.cat((x, x2), 1)
conv_results = [
F.max_pool1d(F.relu(self.get_conv(i)(x)), self.MAX_SENT_LEN - self.FILTERS[i] + 1)
.view(-1, self.FILTER_NUM[i])
for i in range(len(self.FILTERS))]
x = torch.cat(conv_results, 1)
x = F.dropout(x, p=self.DROPOUT_PROB, training=self.training)
x = self.fc(x)
return x
5.训练部分:
model = CNN(**params).cuda(params["GPU"])
parameters = filter(lambda p: p.requires_grad, model.parameters())
optimizer = optim.Adadelta(parameters, params["LEARNING_RATE"])
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
pre_dev_acc = 0
max_dev_acc = 0
max_test_acc = 0
for e in range(params["EPOCH"]):
data["train_x"], data["train_y"] = shuffle(data["train_x"], data["train_y"])
for i in range(0, len(data["train_x"]), params["BATCH_SIZE"]):
batch_range = min(params["BATCH_SIZE"], len(data["train_x"]) - i)
# 数据读取
batch_x = [[data["word_to_idx"][w] for w in sent] +
[params["VOCAB_SIZE"] + 1] * (params["MAX_SENT_LEN"] - len(sent))
for sent in data["train_x"][i:i + batch_range]]
batch_y = [data["classes"].index(c) for c in data["train_y"][i:i + batch_range]]
batch_x = Variable(torch.LongTensor(batch_x)).cuda(params["GPU"])
batch_y = Variable(torch.LongTensor(batch_y)).cuda(params["GPU"])
optimizer.zero_grad()
model.train()
pred = model(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
nn.utils.clip_grad_norm(parameters, max_norm=params["NORM_LIMIT"]) # 计算损失并回传
optimizer.step()
dev_acc = test(data, model, params, mode="dev")
test_acc = test(data, model, params)
print("epoch:", e + 1, "/ dev_acc:", dev_acc, "/ test_acc:", test_acc)
if params["EARLY_STOPPING"] and dev_acc <= pre_dev_acc:
print("early stopping by dev_acc!")
break
else:
pre_dev_acc = dev_acc
if dev_acc > max_dev_acc: # 根据验证集来选择模型
max_dev_acc = dev_acc
max_test_acc = test_acc
best_model = copy.deepcopy(model)
print("max dev acc:", max_dev_acc, "test acc:", max_test_acc)
6.模型测试:词转为ID 、模型测试、 统计结果
def test(data, model, params, mode="test"):
model.eval()
if mode == "dev":
x, y = data["dev_x"], data["dev_y"]
elif mode == "test":
x, y = data["test_x"], data["test_y"]
x = [[data["word_to_idx"][w] if w in data["vocab"] else params["VOCAB_SIZE"] for w in sent] +
[params["VOCAB_SIZE"] + 1] * (params["MAX_SENT_LEN"] - len(sent))
for sent in x]
x = Variable(torch.LongTensor(x)).cuda(params["GPU"])
y = [data["classes"].index(c) for c in y]
pred = np.argmax(model(x).cpu().data.numpy(), axis=1)
acc = sum([1 if p == y else 0 for p, y in zip(pred, y)]) / len(pred)
return acc
5.测试模型
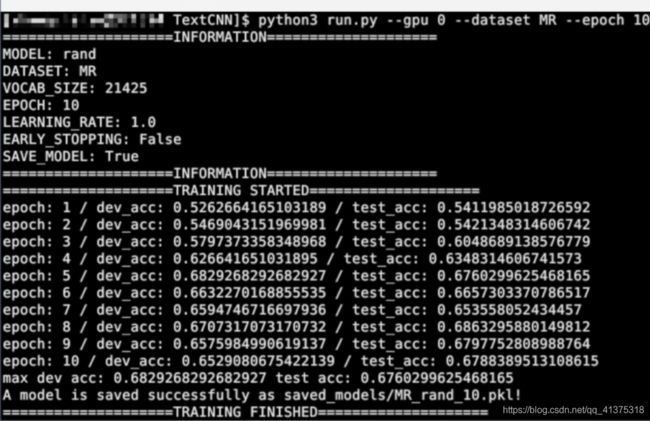

5.讨论和总结

四 问题思索
五 代码详解
model.py
'''
模型文件
'''
'''
代码讲解前期准备:
1.一维卷积操作
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilation(int or tuple, `optional``) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
2.Python setattr() 函数:用于设置属性值
描述
setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的。
语法
setattr() 语法:
setattr(object, name, value)
参数
object -- 对象。
name -- 字符串,对象属性。
value -- 属性值。
返回值
无。
实例
以下实例展示了 setattr() 函数的使用方法:
对已存在的属性进行赋值:
>>>class A(object):
... bar = 1
...
>>> a = A()
>>> getattr(a, 'bar') # 获取属性 bar 值
1
>>> setattr(a, 'bar', 5) # 设置属性 bar 值
>>> a.bar
5
如果属性不存在会创建一个新的对象属性,并对属性赋值:
>>>class A():
... name = "runoob"
...
>>> a = A()
>>> setattr(a, "age", 28)
>>> print(a.age)
28
>>>
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
# 初始定义该模型的超参数等模型参数
# 这些参数的具体设计在run.py中
def __init__(self, **kwargs):
super(CNN, self).__init__()
self.MODEL = kwargs["MODEL"] # 模型状态
self.BATCH_SIZE = kwargs["BATCH_SIZE"] # batch大小
self.MAX_SENT_LEN = kwargs["MAX_SENT_LEN"] # 最长句子长度
self.WORD_DIM = kwargs["WORD_DIM"] # 词向量维度
self.VOCAB_SIZE = kwargs["VOCAB_SIZE"] # 字典大小
self.CLASS_SIZE = kwargs["CLASS_SIZE"] # 类别总数
self.FILTERS = kwargs["FILTERS"] # 滤波器宽度(感受野)
self.FILTER_NUM = kwargs["FILTER_NUM"] # 滤波器个数
self.DROPOUT_PROB = kwargs["DROPOUT_PROB"] # dropout概率
self.IN_CHANNEL = 1 # 词向量类型数
# 首先这行代码不重要,为什么会有这个断言,很简单,因为每种滤波器都要有滤波器
assert (len(self.FILTERS) == len(self.FILTER_NUM))
# one for UNK and one for zero padding
# 词嵌入
self.embedding = nn.Embedding(self.VOCAB_SIZE + 2, self.WORD_DIM, padding_idx=self.VOCAB_SIZE + 1)
# MODEl代表的是词向量的三种初始化方案,static代表的是词向量为预训练固定;non-static为预训练微调;multichannel折中,这种适合小规模数据集
if self.MODEL == "static" or self.MODEL == "non-static" or self.MODEL == "multichannel":
self.WV_MATRIX = kwargs["WV_MATRIX"]
self.embedding.weight.data.copy_(torch.from_numpy(self.WV_MATRIX))
if self.MODEL == "static":
self.embedding.weight.requires_grad = False
elif self.MODEL == "multichannel":
self.embedding2 = nn.Embedding(self.VOCAB_SIZE + 2, self.WORD_DIM, padding_idx=self.VOCAB_SIZE + 1)
self.embedding2.weight.data.copy_(torch.from_numpy(self.WV_MATRIX))
self.embedding2.weight.requires_grad = False
self.IN_CHANNEL = 2
for i in range(len(self.FILTERS)):
# nn.Conv1d为一维卷积操作,所以conv就是卷积之后的值,即特征图,setattr即是赋值操作
conv = nn.Conv1d(self.IN_CHANNEL, self.FILTER_NUM[i], self.WORD_DIM * self.FILTERS[i], stride=self.WORD_DIM)
setattr(self, f'conv_{i}', conv)
# fc是全连接操作,FILTER_NUM是滤波器个数对应着句向量的维度,CLASS_SIZE是类别数
self.fc = nn.Linear(sum(self.FILTER_NUM), self.CLASS_SIZE)
# 得到卷积特征图
def get_conv(self, i):
return getattr(self, f'conv_{i}')
# 前向传播,最后得到类别数x
def forward(self, inp):
x = self.embedding(inp).view(-1, 1, self.WORD_DIM * self.MAX_SENT_LEN)
if self.MODEL == "multichannel":
x2 = self.embedding2(inp).view(-1, 1, self.WORD_DIM * self.MAX_SENT_LEN)
x = torch.cat((x, x2), 1)
conv_results = [
F.max_pool1d(F.relu(self.get_conv(i)(x)), self.MAX_SENT_LEN - self.FILTERS[i] + 1)
.view(-1, self.FILTER_NUM[i])
for i in range(len(self.FILTERS))]
x = torch.cat(conv_results, 1)
x = F.dropout(x, p=self.DROPOUT_PROB, training=self.training)
x = self.fc(x)
return x
run.py
from model import CNN
import utils
from torch.autograd import Variable
import torch
import torch.optim as optim
import torch.nn as nn
from sklearn.utils import shuffle
from gensim.models.keyedvectors import KeyedVectors
import numpy as np
import argparse
import copy
def train(data, params):
if params["MODEL"] != "rand":
# load word2vec
print("loading word2vec...")
word_vectors = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
wv_matrix = []
for i in range(len(data["vocab"])):
word = data["idx_to_word"][i]
if word in word_vectors.vocab:
wv_matrix.append(word_vectors.word_vec(word))
else:
wv_matrix.append(np.random.uniform(-0.01, 0.01, 300).astype("float32"))
# one for UNK and one for zero padding
wv_matrix.append(np.random.uniform(-0.01, 0.01, 300).astype("float32"))
wv_matrix.append(np.zeros(300).astype("float32"))
wv_matrix = np.array(wv_matrix)
params["WV_MATRIX"] = wv_matrix
model = CNN(**params).cuda(params["GPU"])
parameters = filter(lambda p: p.requires_grad, model.parameters())
optimizer = optim.Adadelta(parameters, params["LEARNING_RATE"])
criterion = nn.CrossEntropyLoss()
pre_dev_acc = 0
max_dev_acc = 0
max_test_acc = 0
for e in range(params["EPOCH"]):
data["train_x"], data["train_y"] = shuffle(data["train_x"], data["train_y"])
for i in range(0, len(data["train_x"]), params["BATCH_SIZE"]):
batch_range = min(params["BATCH_SIZE"], len(data["train_x"]) - i)
batch_x = [[data["word_to_idx"][w] for w in sent] +
[params["VOCAB_SIZE"] + 1] * (params["MAX_SENT_LEN"] - len(sent))
for sent in data["train_x"][i:i + batch_range]]
batch_y = [data["classes"].index(c) for c in data["train_y"][i:i + batch_range]]
batch_x = Variable(torch.LongTensor(batch_x)).cuda(params["GPU"])
batch_y = Variable(torch.LongTensor(batch_y)).cuda(params["GPU"])
optimizer.zero_grad()
model.train()
pred = model(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
nn.utils.clip_grad_norm_(parameters, max_norm=params["NORM_LIMIT"])
optimizer.step()
dev_acc = test(data, model, params, mode="dev")
test_acc = test(data, model, params)
print("epoch:", e + 1, "/ dev_acc:", dev_acc, "/ test_acc:", test_acc)
if params["EARLY_STOPPING"] and dev_acc <= pre_dev_acc:
print("early stopping by dev_acc!")
break
else:
pre_dev_acc = dev_acc
if dev_acc > max_dev_acc:
max_dev_acc = dev_acc
max_test_acc = test_acc
best_model = copy.deepcopy(model)
print("max dev acc:", max_dev_acc, "test acc:", max_test_acc)
return best_model
def test(data, model, params, mode="test"):
model.eval()
if mode == "dev":
x, y = data["dev_x"], data["dev_y"]
elif mode == "test":
x, y = data["test_x"], data["test_y"]
x = [[data["word_to_idx"][w] if w in data["vocab"] else params["VOCAB_SIZE"] for w in sent] +
[params["VOCAB_SIZE"] + 1] * (params["MAX_SENT_LEN"] - len(sent))
for sent in x]
x = Variable(torch.LongTensor(x)).cuda(params["GPU"])
y = [data["classes"].index(c) for c in y]
pred = np.argmax(model(x).cpu().data.numpy(), axis=1)
acc = sum([1 if p == y else 0 for p, y in zip(pred, y)]) / len(pred)
return acc
def main():
parser = argparse.ArgumentParser(description="-----[CNN-classifier]-----")
parser.add_argument("--mode", default="train", help="train: train (with test) a model / test: test saved models")
parser.add_argument("--model", default="rand", help="available models: rand, static, non-static, multichannel")
parser.add_argument("--dataset", default="TREC", help="available datasets: MR, TREC")
parser.add_argument("--save_model", default=False, action='store_true', help="whether saving model or not")
# parser.add_argument("--early_stopping", default=False, action='store_true', help="whether to apply early stopping")
parser.add_argument('--early_stopping', dest='early_stopping', action='store_true', help='whether to apply early stopping')
parser.add_argument('--no-early_stopping', dest='early_stopping', action='store_false')
parser.set_defaults(early_stopping=False)
parser.add_argument("--epoch", default=100, type=int, help="number of max epoch")
parser.add_argument("--learning_rate", default=1.0, type=float, help="learning rate")
parser.add_argument("--gpu", default=-1, type=int, help="the number of gpu to be used")
options = parser.parse_args()
data = getattr(utils, f"read_{options.dataset}")()
data["vocab"] = sorted(list(set([w for sent in data["train_x"] + data["dev_x"] + data["test_x"] for w in sent])))
data["classes"] = sorted(list(set(data["train_y"])))
data["word_to_idx"] = {w: i for i, w in enumerate(data["vocab"])}
data["idx_to_word"] = {i: w for i, w in enumerate(data["vocab"])}
params = {
"MODEL": options.model,
"DATASET": options.dataset,
"SAVE_MODEL": options.save_model,
"EARLY_STOPPING": options.early_stopping,
"EPOCH": options.epoch,
"LEARNING_RATE": options.learning_rate,
"MAX_SENT_LEN": max([len(sent) for sent in data["train_x"] + data["dev_x"] + data["test_x"]]),
"BATCH_SIZE": 50,
"WORD_DIM": 300,
"VOCAB_SIZE": len(data["vocab"]),
"CLASS_SIZE": len(data["classes"]),
"FILTERS": [3, 4, 5],
"FILTER_NUM": [100, 100, 100],
"DROPOUT_PROB": 0.5,
"NORM_LIMIT": 3,
"GPU": options.gpu
}
print("=" * 20 + "INFORMATION" + "=" * 20)
print("MODEL:", params["MODEL"])
print("DATASET:", params["DATASET"])
print("VOCAB_SIZE:", params["VOCAB_SIZE"])
print("EPOCH:", params["EPOCH"])
print("LEARNING_RATE:", params["LEARNING_RATE"])
print("EARLY_STOPPING:", params["EARLY_STOPPING"])
print("SAVE_MODEL:", params["SAVE_MODEL"])
print("=" * 20 + "INFORMATION" + "=" * 20)
if options.mode == "train":
print("=" * 20 + "TRAINING STARTED" + "=" * 20)
model = train(data, params)
if params["SAVE_MODEL"]:
utils.save_model(model, params)
print("=" * 20 + "TRAINING FINISHED" + "=" * 20)
else:
model = utils.load_model(params).cuda(params["GPU"])
test_acc = test(data, model, params)
print("test acc:", test_acc)
if __name__ == "__main__":
main()
utils.py
'''
工具文件:数据的预处理,存储和加载数据
'''
from sklearn.utils import shuffle
import pickle
# 读取数据TREC
def read_TREC():
data = {}
def read(mode):
x, y = [], []
with open("data/TREC/TREC_" + mode + ".txt", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
y.append(line.split()[0].split(":")[0])
x.append(line.split()[1:])
x, y = shuffle(x, y)
if mode == "train":
dev_idx = len(x) // 10
data["dev_x"], data["dev_y"] = x[:dev_idx], y[:dev_idx]
data["train_x"], data["train_y"] = x[dev_idx:], y[dev_idx:]
else:
data["test_x"], data["test_y"] = x, y
read("train")
read("test")
return data
# 读取数据MR
def read_MR():
data = {}
x, y = [], []
with open("data/MR/rt-polarity.pos", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(1)
with open("data/MR/rt-polarity.neg", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(0)
x, y = shuffle(x, y)
dev_idx = len(x) // 10 * 8
test_idx = len(x) // 10 * 9
data["train_x"], data["train_y"] = x[:dev_idx], y[:dev_idx]
data["dev_x"], data["dev_y"] = x[dev_idx:test_idx], y[dev_idx:test_idx]
data["test_x"], data["test_y"] = x[test_idx:], y[test_idx:]
return data
# 保存模型
def save_model(model, params):
path = f"saved_models/{params['DATASET']}_{params['MODEL']}_{params['EPOCH']}.pkl"
pickle.dump(model, open(path, "wb"))
print(f"A model is saved successfully as {path}!")
# 加载模型
def load_model(params):
path = f"saved_models/{params['DATASET']}_{params['MODEL']}_{params['EPOCH']}.pkl"
try:
model = pickle.load(open(path, "rb"))
print(f"Model in {path} loaded successfully!")
return model
except:
print(f"No available model such as {path}.")
exit()