我们分析了5万多场英雄联盟比赛,教你如何轻松用Python预测胜负


作者:真达、Mika
数据:真达
后期:Mika
【导读】
今天教大家用Python预测英雄联盟比赛胜负。公众号后台,回复关键字“LOL”获取完整数据。
Show me data,用数据说话
今天我们聊一聊 Python预测LOL胜负
点击下方视频,先睹为快:
目前,英雄联盟S10全球总决赛正在火热进行中,最终决赛将于10月31日在浦东足球场举行。作为当下最火热的电竞赛事,这点燃了全球无数玩家的关注,相信没有哪个英雄联盟玩家会错过这场受众超广、影响力超大的国际电竞赛事。LPL究竟能否在家门口拿下第三座世界赛奖杯也成了许多玩家关注的话题。

对于每场比赛,大家最关注的莫过于最后的胜负了,那么比赛的胜负能否可以预测呢?
今天,我们就分析了5万多场英雄联盟的排名比赛,教你如何用Python预测比赛胜负。
01
项目介绍
英雄联盟(LOL)是美国游戏开发商Riot Games(2011年由腾讯收购)开发和发行的一款多人在线战斗竞技游戏。
在游戏中,玩家扮演一个"召唤师"角色,每个召唤师控制一个拥有独特技能的"英雄",并与一组其他玩家或电脑控制的英雄战斗。游戏的目标是摧毁对方的防御塔和基地。
召唤者峡谷是英雄联盟中最受欢迎的地图,在这种地图类型中,两队五名玩家竞争摧毁一个被称为基地的敌人建筑,这个建筑由敌人的队伍和一些防御塔护卫。每个队伍都希望保卫自己的建筑,同时摧毁对方的建筑。这些主要包括:
Towers(防御塔):每支队伍总共有11座防御塔
Inhibitor(水晶):每条道有一个水晶
Elemental Drakes/Elder Dragon(大龙/远古龙)
Rift Herald(峡谷先锋)
Baron Nasho(纳什男爵)
Nexus(基地)
英雄联盟最具争议的元素之一,就是其严重的滚雪球效应。许多职业选手接受赛后采访时都提到其输赢都因为“滚雪球”,我们研究各方面各指标的数据,来看这些因素的发展是否真的影响了比赛的成败。
在这个项目中,我们分析了5万多场英雄联盟的排名比赛,并尝试使用决策树算法来根据已有输入属性预测比赛胜负。
02
数据集概述
数据集收集了超过50000个从游戏英雄联盟排位游戏的数据,字段主要包含以下数据:
Game ID:游戏ID
Creation Time:创建时间
Game Duration (in seconds):游戏持续时间(秒)
Season ID:赛季ID
Winner (1=team1, 2=team2):获胜队伍
First Baron, dragon, tower, blood, inhibitor and Rift Herald (1 = team1, 2 = team2, 0 = none):第一条纳什男爵,大龙,塔,一血,水晶,峡谷先锋
Champions and summoner spells for each team (Stored as Riot's champion and summoner spell IDs):每只队伍选择的英雄和召唤术
The number of tower, inhibitor, Baron, dragon and Rift Herald kills each team has:塔,水晶,男爵,大龙和峡谷先锋击杀数
The 5 bans of each team (Again, champion IDs are used):每个队伍的禁用英雄
03
数据读入和预览
首先导入所需包和读入数据集。
# 数据整理
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
import plotly as py
import plotly.graph_objs as go
# 建模
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, classification_report
# 读入数据
df = pd.read_csv('./archive/games.csv')
df.head()
df.shape
(51490, 61)
04
数据可视化
我们将分别对影响比赛的相关因素进行如下探索:
1. 目标变量分布
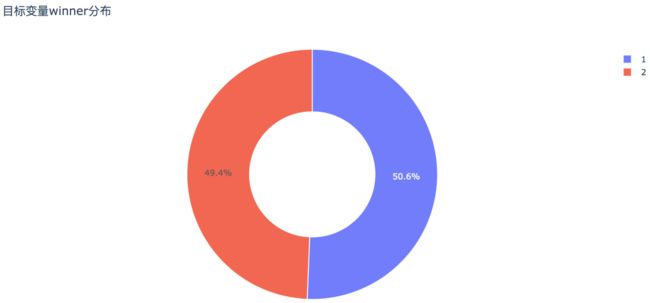
数据集一共有51490条记录,其中1队获胜的次数为26077次,占比50.6%,2队获胜的次数为25413次,占比49.4%。不存在样本不平衡的情况。
代码
# 饼图
trace0 = go.Pie(labels=df['winner'].value_counts().index,
values=df['winner'].value_counts().values,
hole=0.5,
opacity=0.9,
marker=dict(line=dict(color='white', width=1.3))
)
layout = go.Layout(title='目标变量winner分布')
data = [trace0]
fig = go.Figure(data, layout)
py.offline.plot(fig, filename='./html/整体获胜情况分布.html')
2. 游戏时长分布

从直方图可以看出,游戏时长大致服从正态分布,其中最短的游戏时长为3分钟,3分钟是游戏重开的时间点,最长的游戏时长是79分钟。中间50%的时长在26~36分钟之间。
代码
df['game_duration'] = round(df['gameDuration'] / 60)
# 选择数据
x1 = df[df['winner'] == 1]['game_duration']
x2 = df[df['winner'] == 2]['game_duration']
# 直方图
trace0 = go.Histogram(x=x1, bingroup=25, name='team1', opacity=0.9)
trace1 = go.Histogram(x=x2, bingroup=25, name='team2', opacity=0.9)
layout = go.Layout(title='比赛游戏时长分布')
data = [trace0, trace1]
fig = go.Figure(data, layout)
py.offline.plot(fig, filename='./html/游戏时长分布.html')
3. 一血对获胜的影响
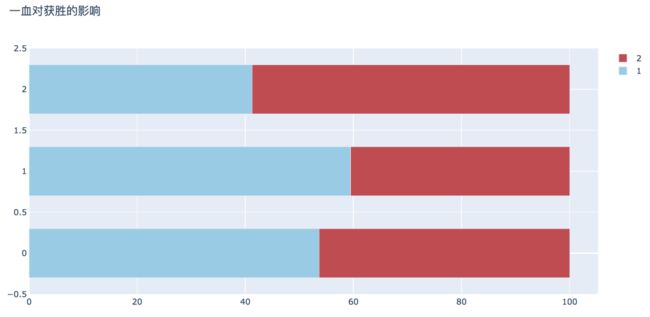
获得一血的队伍胜率相对较高,在第一队的比赛中,首先获得一血时的胜率为59.48%,相较未获得一血的比赛高18%。在第二队的比赛中,获得一血时的胜率为58.72%,相较未获得一血的比赛高18%。
代码
plot_bar_horizontal(input_col='firstBlood', target_col='winner', title_name='一血对获胜的影响')
4. 一塔对获胜的影响

从数据来看,第一个防御塔看起来是比较有说服力的指标。在第一队的比赛中,首先摧毁一塔时队伍的胜率高达70.84%,相较未获得一塔的比赛高41.64%。在第二队的比赛中,有相近的数据表现。
代码
plot_bar_horizontal(input_col='firstTower', target_col='winner', title_name='一塔对获胜的影响')
5. 摧毁第一个水晶对获胜的影响

在比赛中拿到第一座水晶塔的队伍91%的情况下可以获胜,这一点在某种程度上是可以预见的,因为首先摧毁水晶塔代表队伍已经积累的足够的优势,而且水晶塔力量很强大,并且更具有价值。
代码
plot_bar_horizontal(input_col='firstInhibitor', target_col='winner', title_name='摧毁第一个水晶对获胜的影响')
6. 击杀第一条男爵对获胜影响
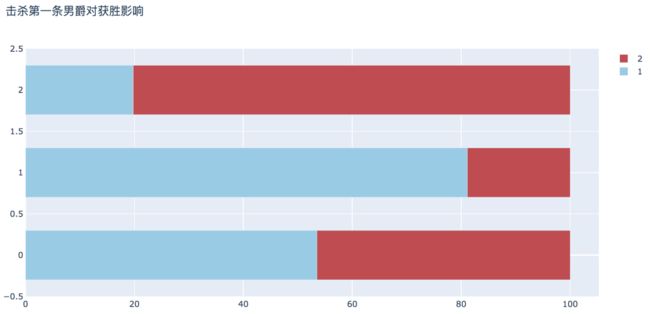
统计数据显示,在比赛中击杀第一条男爵有80%的胜率。
plot_bar_horizontal(input_col='firstBaron', target_col='winner', title_name='击杀第一条男爵对获胜影响')
7. 击杀第一条大龙对获胜的影响
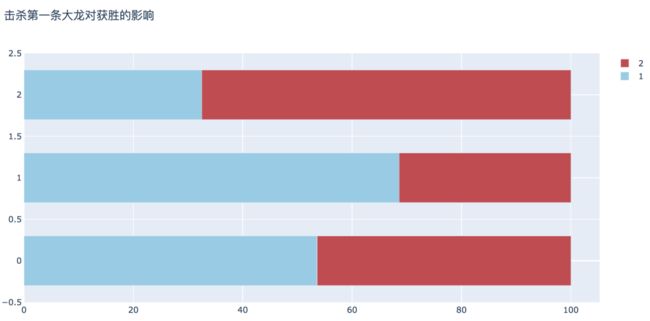
在第一个队伍中,首先击杀第一条大龙的队伍胜率在68.6%,相较未取得优先的比赛胜率高36%。
plot_bar_horizontal(input_col='firstDragon', target_col='winner', title_name='击杀第一条大龙对获胜的影响')
8. 击杀第一条峡谷先锋对获胜的影响
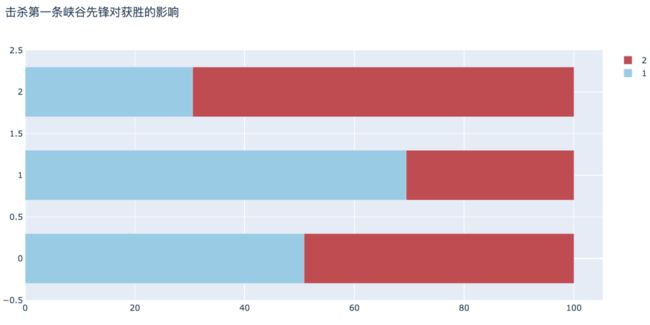
在第一个队伍中,首先击杀第一条峡谷先锋的队伍胜率在69.45%,相较未取得优先的比赛胜率高38.92%。
plot_bar_horizontal(input_col='firstRiftHerald', target_col='winner',
title_name='击杀第一条峡谷先锋对获胜的影响')
9. 摧毁防御塔数对获胜影响
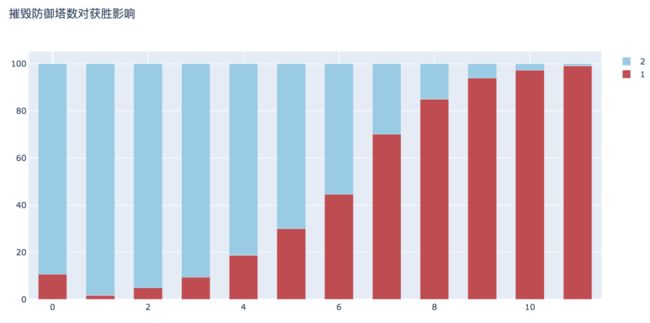
选择第一个队伍的摧毁防御塔数作为影响因素,可以看出,摧毁的防御塔数量越多,获胜的概率越大。当数量大于8个时,胜率大于85%。11个防御塔全部摧毁时的胜率为99.16%,当然也有8.4‰的翻盘概率。
plot_bar_vertical(input_col='t1_towerKills', target_col='winner', title_name='摧毁防御塔数对获胜影响')
10. 摧毁水晶数对获胜影响
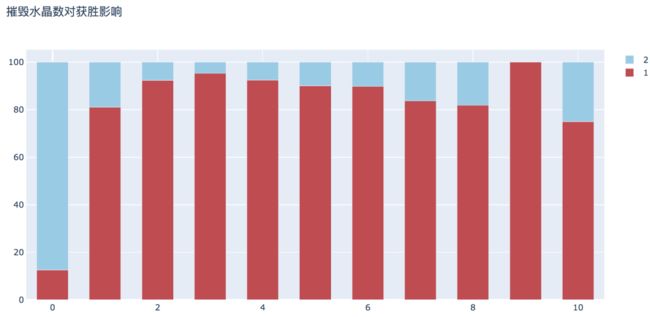
摧毁水晶的数目越多,获胜的概率越大。没有摧毁水晶的获胜概率为12.55%,摧毁一个的获胜概率为81.11%,两个为92.38%。
plot_bar_vertical(input_col='t1_inhibitorKills', target_col='winner', title_name='摧毁水晶数对获胜影响')
11. 击杀男爵数对获胜影响

击杀男爵数越多,获胜的概率越大,击杀5条男爵的数据仅有一条,后续需要删除。
plot_bar_vertical(input_col='t1_baronKills', target_col='winner', title_name='击杀男爵数对获胜影响')
12. 击杀大龙数对获胜影响
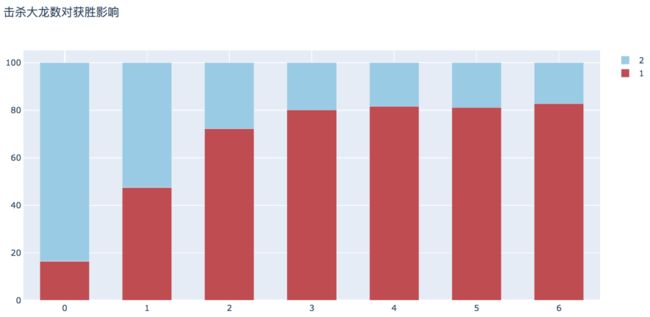
击杀大龙数数越多,获胜的概率越大
plot_bar_vertical(input_col='t1_dragonKills', target_col='winner', title_name='击杀大龙数对获胜影响')
05
数据建模
首先进行初步的清洗,并筛选建模所需变量。
# 删除时间少于15分钟和分类数较少的记录
df = df[(df['gameDuration'] >= 900) & (df['t1_baronKills'] != 5)]
print(df.shape)
(50180, 62)
# 筛选建模变量
df_model = df[['winner', 'firstBlood', 'firstTower', 'firstInhibitor', 'firstBaron',
'firstDragon', 'firstRiftHerald', 't1_towerKills', 't1_inhibitorKills','t1_baronKills',
't1_dragonKills', 't2_towerKills', 't2_inhibitorKills', 't2_baronKills', 't2_dragonKills'
]]
df_model.head()

然后划分训练集和测试集,采用分层抽样方法划分80%数据为训练集,20%数据为测试集。
# 划分训练集和测试集
x = df_model.drop('winner', axis=1)
y = df_model['winner']
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y, random_state=0)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(40144, 14) (10036, 14) (40144,) (10036,)
使用决策树算法建模,使用GridSearchCV进行参数调优。
# 参数
parameters = {
'splitter': ('best', 'random'),
'criterion':('gini', 'entropy'),
'max_depth':[*range(1, 20, 2)],
}
# 建立模型
clf = DecisionTreeClassifier(random_state=0)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train, y_train)
GridSearchCV(cv=10, estimator=DecisionTreeClassifier(random_state=0),
param_grid={'criterion': ('gini', 'entropy'),
'max_depth': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19],
'splitter': ('best', 'random')})
# 输出最佳得分
print("best score: ", GS.best_score_)
print("best param: ", GS.best_params_)
best score: 0.9770077890521407
best param: {'criterion': 'gini', 'max_depth': 7, 'splitter': 'best'}
# 最佳模型
best_clf = DecisionTreeClassifier(criterion="gini", max_depth=7, splitter="best")
best_clf.fit(X_train,y_train)
print("score:", best_clf.score(X_test,y_test))
score: 0.9799721004384216
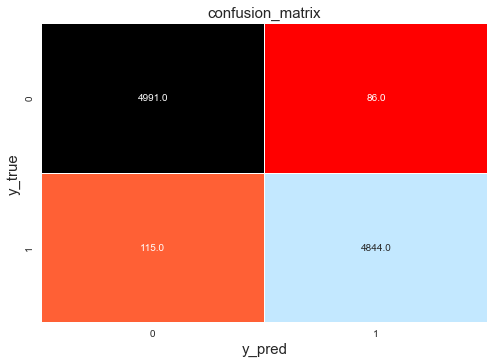
使用最优的模型重新评估测试数据集效果:
# 输出分类报告
y_pred = best_clf.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
cr = classification_report(y_test, y_pred)
print('Classification report : \n', cr)
Classification report :
precision recall f1-score support
1 0.98 0.98 0.98 5077
2 0.98 0.98 0.98 4959
accuracy 0.98 10036
macro avg 0.98 0.98 0.98 10036
weighted avg 0.98 0.98 0.98 10036
# 热力图
g1 = sns.heatmap(cm, annot=True, fmt=".1f", cmap="flag", linewidths=0.2, cbar=False)
g1.set_ylabel('y_true', fontdict={'fontsize': 15})
g1.set_xlabel('y_pred', fontdict={'fontsize': 15})
g1.set_title('confusion_matrix', fontdict={'fontsize': 15})
Text(0.5, 1, 'confusion_matrix')
# 输出属性重要性
imp = pd.DataFrame(list(zip(X_train.columns, best_clf.feature_importances_)))
imp.columns = ['columns', 'importances']
imp = imp.sort_values('importances', ascending=False)
imp

在属性的重要性排序中,击杀防御塔数量的重要性最高,其次是水晶摧毁数量、一塔、击杀龙的数量。
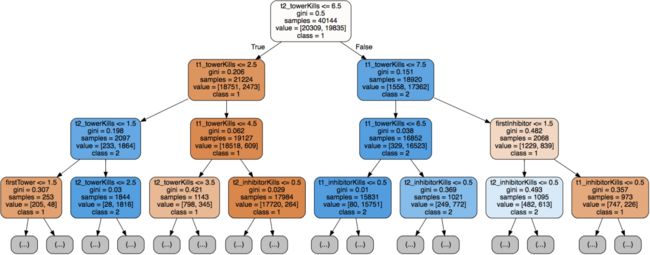
以下代码用于输出这颗树:
# 可视化
import graphviz
from sklearn import tree
dot_data = tree.export_graphviz(decision_tree=best_clf, max_depth=3,
out_file=None,
feature_names=X_train.columns,
class_names=['1', '2'],
filled=True,
rounded=True
)
graph = graphviz.Source(dot_data)
graph
06
模型预测
我们假设:
第一队拿了第一血,第一塔,第一男爵,第一条大龙和第一峡谷先锋,而第二队只拿了第一个水晶。
第一队的塔,水晶,男爵和龙杀死的数量分别是10,2,1,4和塔,水晶,男爵和龙的数量分别是7,2,1,1。
# 新数据
new_data = [[1, 1, 2, 1, 1, 1, 10, 2, 1, 4, 7, 2, 1, 1]]
c = best_clf.predict_proba(new_data).reshape(-1, 1)
print("winner is :" , best_clf.predict(x1))
print("First team win probability is % ", list(c[0] * 100),
"\nSecond team win probability is %:",list(c[1] * 100))
winner is : [1]
First team win probability is % [89.87341772151899]
Second team win probability is %: [10.126582278481013]
根据模型预测结果,第一队将会获胜,获胜的概率为89.87%。
本文出品:CDA数据分析师(ID: cdacdacda)

近期开班情况
课程详情请扫码咨询
