月度总结 | 福利面经 | 机器学习 共20题(附答案)

【机器学习炼丹术】主要是个人学习笔记的整理与分享。作者的文风诙谐幽默,通俗易懂的讲解机器学习领域与图像处理领域中的各种模型、算法、竞赛top方案与知识点。作者是清华大学出版社的签约作家,擅长于以通俗语言讲解算法,并且保留数学推导内容,读者易于理解,且能理解内部数学原理。
最近在更新的内容主要是找工作面试时经常会用到的基础知识,非常适合下面两类人:
刚接触AI的初学者,通俗易懂的文章易于基础薄弱的朋友理解;
准备校招的应届生,反复阅读文章加深印象,防止在面试的时候出现记忆不清的困境。
关注公众号回复【下载】,获取有免费的杂七杂八的机器学习相关的PDF学习资料,持续更新哦!回复【白嫖】有吴恩达、李宏毅等专家的全系列入门视频教程。

<<下面正文开始>>
公众号自动创建以来已经过了满打满算的1个月了(6.23号注册的),这一个月来感谢各位朋友的支持,现在关注已经突破700了(其实只有698,希望这个文章发了就会突破700了吧大概)。这一个月也是我开始找工作的一个月,不断地面试,然后不断地记录在面试中遇到的各种问题。记录文章的目的之一就是方便自己复习,防止自己再次被同一个问题绊倒。不过分享文章的时候,也或多或少能够帮助到一些人,也认识了新朋友,这个过程也是非常令人欣喜的。
这里做一个6月到7月的总结,大家可以当成一个小小的测试。如果大家觉得这些内容有用的话,也欢迎大家去分享这边文章给同走在AI求学路上的朋友,大家搭个伴,生活会增加一抹色彩的吧。
完成20道题后,文章末尾有福利(其实就是一些学习资料和一些非常经典的视频教程,吴恩达老师的啊、李宏毅老师的啊等等)
【关于文章结构】
本文主要有20道题,每道题后面我会写上自己个人的回答思路,这个会比较概括。再这之后会放上详细的关于知识点的相关文章可供学习。
本文建议收藏,下面小测试开始咯~
1. 项目介绍
这部分就介绍了自己参与大数据竞赛和Deepfake Detection Challenge的经历和代码,还有创新点。这个因人而异吧,我主要是没有实习经历,所以在简历关特别吃亏。研究生务必要重视暑期实习!大数据竞赛中,要讲一下时间序列的特征工程,还有填补缺失值的方法,自己用的LGB模型所以也会提一下(提到LGB模型的话,面试官很可能会问你更多的关于这个模型的原理算法,不过这次的面试没有问LGB就是了)。
<<参考答案>>
项目总结 | 对 "时间" 构建的特征工程?
项目总结 | 八种缺失值处理方法总有一种适合你
AI面试扩展之LightGBM = GOSS + histogram + EFB
2. python中的数据类型
Python基本数据类型一般分为:数字、字符串、列表、元组、字典、集合这六种基本数据类型。
3. GBDT
GBDT是基于boosting的思想,串行地构造多棵决策树来进行数据的预测,它是在损失函数所在的函数空间中做梯度下降,即把待求的决策树模型当作参数,每轮迭代都去拟合损失函数在当前模型下的负梯度,从而使得参数朝着最小化损失函数的方向更新。
<<参考答案>>
AI面试题之GBDT梯度提升树
4. XGBoost的原理
XGBoost相对与GBDT优化了目标函数。目标函数增加了一个表示树复杂度的参数,相当于一个正则项。并且XGBoost在优化损失的时候,不仅仅使用了一阶导数,还是用了二阶导数信息,加快了收敛。
<<参考答案>>
AI面试题之XGBoost与手推二阶导
5. 怎么调参的,了解并行优化吗?
关于调参我个人有一套流程,毕竟我是调参侠嘛。boost模型,先调估计器数量,然后是树的深度,然后是限制叶子节点最小样本,然后是选择样本降采样,再然后L1L2正则化,然后降低学习率。
至于并行优化,我没有实践中使用过,因为只有一台小小的笔记本让我来糟蹋。听说过两种并行,一个是feature parallel,一个是data parallel。
<<参考答案>>
工程能力UP!| LightGBM的调参与并行
6. SVM使用核函数的问题
这一部分我回答的不太好,对SVM的核函数理解的不够深刻。一般常用的核函数是两个:线性核和高斯核。高斯核Gaussian Kernel 也就是Radial Basis Function (RBF)。
linear: 。如果Feature的数量很大,跟样本数量差不多,这时候选用逻辑回归或者是Linear Kernel的SVM。
高斯核:。如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel。
需要注意的是需要对数据归一化处理,很多使用者忘了这个小细节,然后一般情况下RBF效果是不会差于Linear,但是时间上RBF会耗费更多。
7. SVM的数学公式以及推导过程
这个其实就是推导公式,从一开始的求取最大间隔的约束问题,通过拉格朗日乘子法变成无约束的最小化优化问题。然后再加上KKT条件就是当时回答的整个过程了。
<<参考答案>>
AI面试题之SVM推导
8. SVM拉格朗日乘子的原理
把有约束优化问题转换为无约束的优化问题的关键,在于满足约束与优化问题图像相切的时刻,两者的梯度方向在同一条直线上,因此可以通过梯度相等这个条件,来将约束优化问题,转化为一个增加了约束项的非约束优化问题。如果这个约束是一个不等式,而不是一个等值约束,那么还要考虑KKT条件。
<<参考答案>>
通俗易懂 | SVM之拉格朗日乘子法
9. KKT条件内容和原理
主要是因为不等值约束会有两种情况,一种是约束不起效果,一种是其效果的情况。KKT条件就综合体现了这两种情况。
<<参考答案>>
通俗易懂 | SVM之拉格朗日乘子法
10. SVM的软间隔
软间隔这个没有回答上来当时。后来查了一下,是因为避免SVM对数据中的噪音过于敏感,使用了软间隔。之前硬间隔的SVM中:
最后推导得到的
软间隔就是 然后在优化函数中加入一个限制 的项: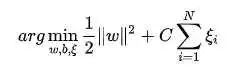 最后用相同的推导方式可以得到 。
最后用相同的推导方式可以得到 。
11. SVM的hingeloss
很简单,就是下面这个。如果线性SVM使用交叉熵损失函数的那,那就是Logistic Regression逻辑回归了。所以SVM与其他模型区分的关键就是Hinge Loss损失函数。所以有的时候,对于一个多层感知机,使用了Hinge Loss的话,也会被成为深度SVM模型。
【我个人感觉svm一种是按照之前几道题那样,用拉格朗日乘子法推导非约束优化问题的解,是传统的SVM;也可以用hinge loss来用梯度下降的方法来估计参数】
<<参考答案>>
通俗易懂 | SVM的HingeLoss
12. 批正则化BN的原理和作用,在训练和测试时有什么不同
这个问题并不难,原理就是通过两个学习的参数,来把数据的分布固定到均值为 ,方差为 。加快模型的收敛速度,解决ICS问题。测试的时候因为无法得到数据的均值和方差,所以使用了训练集的所有batch记录下来的均值方差做一个平均。
<<参考答案>>
干货 | BatchNormalization详解与比较
13. dropout的原理和作用,在训练和测试时有什么不同
这个dropout随机让神经元失活,然后再测试的时候所有神经元都起效果,然后把模型的结果乘上一个缩小系数。比如训练阶段随机让20%的神经元失活,然后再测试阶段所有神经元都参与预测,这样理论上模型输出的结果会比正常大一些,因为之前都是用80%的神经元进行预测的,所以最后的结果再乘上0.8即可。
14. 什么是梯度消失,什么情况导致梯度消失,处理梯度消失的方法
梯度消失梯度抱着都是因为链式法则引起的,梯度消失一个是因为sigmoid激活函数的导数最大值是0.25,所以当使用越多sigmoid激活函数的时候,梯度就消失了,后来使用relu激活函数来避免这个问题。当然,当网络层数过多的时候,梯度也会消失,通过残差链接来解决这个问题。
<<参考答案>>
AI面试题之梯度消失(爆炸)及其解决方法
15. 什么是梯度爆炸,梯度爆炸的处理方法
梯度爆炸出现的情况较少,主要是因为模型的参数过大导致的,使用L2正则化,可以有效解决这个问题。
<<参考答案>>
AI面试题之梯度消失(爆炸)及其解决方法
16,**kwargs, *args
两个是python函数的可变参数。args应该是arguments的缩写,然后kwargs是keyword arguments的缩写。
args是tuple,然后kwards就是带着keyword的参数,也就是字典dict的形式。
下面一个例子就明白了:
def foo(*args,**kwargs):
print 'args=',args
print 'kwargs=',kwargs
print '**********************'
if __name__=='__main__':
foo(1,2,3)
foo(a=1,b=2,c=3)
foo(1,2,3,a=1,b=2,c=3)
foo(1,'b','c',a=1,b='b',c='c')
运行结果就是:
args= (1, 2, 3)
kwargs= {}
**********************
args= ()
kwargs= {'a': 1, 'c': 3, 'b': 2}
**********************
args= (1, 2, 3)
kwargs= {'a': 1, 'c': 3, 'b': 2}
**********************
args= (1, 'b', 'c')
kwargs= {'a': 1, 'c': 'c', 'b': 'b'}
**********************
非常好理解。
17. pytorch模型训练过程中net.train()和net.eval()的区别,造成区别的原因(这个问题是因为我在项目中用到了pytorch)
官方的解释是:在验证或者测试的时候,模型中的某些层不应该起作用,比如说dropout层,也有一些层在训练和测试的时候的处理逻辑不同,比如说BN层,所以就需要设置net.eval()来告诉模型,现在要测试了,不是训练阶段了,大家做好准备。
18. vgg和resnet的区别
VGG就是堆叠的思想,想看是不是网络层数越深,效果越好,但是发现层数太多的话,会出现梯度消失的问题。resnet使用残差结构,环节了梯度消失的问题。
<<参考答案 相关答案>>
大汇总 | 一文学会八篇经典CNN论文
19. 给一个特征图,已知步长,卷积核大小和padding,求输出特征图大小
很简单,就是特征图尺寸+2*padding-卷积核大小,结果除以步长stride再加1即可。
<<参考答案>>
AI面试题之(反)卷积输出尺寸计算
20. 逻辑回归损失函数怎么得来的,极大似然估计的形式
就是根据极大似然估计的方法,推导出来交叉熵损失的。非常好推导。
<<参考答案>>
AI面试题之线性回归与逻辑回归(似然参数估计)
恭喜你,完成了本次考试,祝您前程似锦,福报来到。
<<通俗讲AI系列的其他文章>>
AI面试之Adaboost及手推算法案例
AI面试题之防止过拟合的所有方法
AI面试题之 判别模型&生成模型
【kalman filter】卡尔曼滤波器与python实现
机器学习不得不知道的提升技巧:SWA与pseudo-label
Adam优化器为什么被人吐槽?
五分钟理解:BCELoss 和 BCEWithLogitsLoss的区别
决策树(一)基尼系数与信息增益、
一分钟速学 | NMS, IOU 与 SoftMax
图像增强 | CLAHE 限制对比度自适应直方图均衡化
AI面试题之深入浅出卷积网络的平移不变性
五分钟了解:端侧神经网络GhostNet(2019)
最快最好用的图像处理库:albumentations库的简单了解和使用
五分钟学会:焦点损失函数 FocalLoss 与 GHM

强烈推荐 | “深度学习零基础视频教程”,“机器学习零基础视频教程”,"python零基础入门基础视频教程"等,公众号回复【视频教程】或者【白嫖】免费获取~
关注公众号,回复【下载】有免费的杂七杂八的机器学习相关的PDF学习资料,持续更新哦!
为了方便用户体验,所有的下载资源都是不限速!不用登陆!
回复【入群】,加入校招微信群,和大佬一起交流面试心得(其实还没找到大佬,只是一群菜逼在互相安慰)。
公众号经常会有福利送书活动哦~