【5】强化学习之时序差分方法(Sarsa和Q-learning)
目录
- 1、时序差分预测
-
- 1)与动态规划方法的比较
- 2)与蒙特卡罗方法的比较
- 3)时序差分预测伪代码
- 2、Sarsa算法:在线策略的时序差分方法
- 3、Q-learning算法:离线策略的时序差分方法
- 4、Q-learning解决寻宝问题
-
- 1)环境编写
- 2)算法实施
蒙特卡罗方法可以在不知道环境特性的时候,通过与环境互动来估计状态(或状态-动作)的价值函数,但该方法也有一定的缺陷。首先,由于环境的动态特性,蒙特卡罗每次寻找的路径都可能不一样。其次,当状态空间比较大时,蒙特卡罗方法非常耗时,效率低,比如要走很多步才能到达终止状态。
在所有的强化学习思想中,时序差分(Temporal Difference, TD)学习是最核心、最新颖的方法,它结合了动态规划和蒙特卡罗方法的思想。类似于动态规划(自举思想),时序差分方法无需等待一轮回合的结束就能后继状态的估计值来更新当前状态的价值函数。而与蒙特卡罗保持一致的是时序差分也是直接与环境的互动来学习策略。
\\[20pt]
1、时序差分预测
本节依次比较时序差分方法和动态规划、蒙特卡罗方法,最后给出时序差分预测的伪代码。
1)与动态规划方法的比较
我们知道动态规划采用 v π v_\pi vπ的贝尔曼方程来迭代更新状态的价值函数,即:
v π ( s ) = ∑ a π ( a ∣ s ) ( ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] ) (1) v_\pi(s)=\sum_{a}\pi(a|s) \left (\sum_{s^\prime,r} p(s^\prime,r|s,a)[r+\gamma v_\pi(s^\prime)] \right) \tag{1} vπ(s)=a∑π(a∣s)⎝⎛s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]⎠⎞(1)
其中 π ( a ∣ s ) \pi(a|s) π(a∣s)表示在状态s处选择动作a的概率。
公式(1)表明,更新状态s的价值函数 v π ( s ) v_\pi(s) vπ(s)需要知道s处执行动作a的后继状态的价值函数 v π ( s ′ ) v_\pi(s^\prime) vπ(s′),当然后继状态有可能包含状态s本身,因此这种方法也称为自举法。TD也用到了这种自举的思想,其更新公式为:
V ( S t ) ← V ( S t ) + α [ R t + 1 + γ V ( S t + 1 ) − V ( S t ) ] (2) V(S_t)\leftarrow V(S_t)+\alpha[R_{t+1}+\gamma V(S_{t+1})-V(S_t)] \tag{2} V(St)←V(St)+α[Rt+1+γV(St+1)−V(St)](2)
从公式(2)看出, S t S_t St的价值函数更新用到了它的后继状态 S t + 1 S_{t+1} St+1的价值函数。
2)与蒙特卡罗方法的比较
TD和蒙特卡罗方法都利用经验来解决价值函数的评估问题,给定策略 π \pi π的一些经验,以及这些经验中的非终止状态 S t S_t St,该两种方法都会更新它们对 v π v_\pi vπ的估计V。蒙特卡罗方法的更新公式可表示为:
V ( S t ) ← V ( S t ) + α [ G t − V ( S t ) ] (3) V(S_t)\leftarrow V(S_t)+\alpha[G_{t}-V(S_t)] \tag{3} V(St)←V(St)+α[Gt−V(St)](3)
其中 G t G_t Gt是时刻 t t t的真实回报, α \alpha α为更新步长参数。蒙特卡罗方法需要一直等到一次回合的结束后通过回溯计算出回报 G t G_t Gt,再使用 G t G_t Gt作为 V ( S t ) V(S_t) V(St)的更新目标进行估计。
蒙特卡罗方法必须等到一次回合的结束才能确定 V ( S t ) V(S_t) V(St)的增量,因为这时候 G t G_t Gt才已知,而TD方法只需等到下一时刻即可。在t+1时刻,TD方法立刻就能构造出更新目标,并使用观察到的收益 R ( S t + 1 ) R(S_{t+1}) R(St+1)和估计值 V ( S t + 1 ) V(S_{t+1}) V(St+1)来进行一次更新。实际上蒙特卡罗的更新目录是 G t G_t Gt,而TD的更新目标是 R t + 1 + γ V ( S t + 1 ) R_{t+1}+\gamma V(S_{t+1}) Rt+1+γV(St+1)。
3)时序差分预测伪代码
给定一个待评估的策略 π \pi π,状态价值函数的评估伪代码如下:

\\[20pt]
2、Sarsa算法:在线策略的时序差分方法
Sarsa算法的“状态-动作”二元组的价值函数更新为:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ Q ( S t + 1 , A t + 1 ) − Q ( S t , A t ) ] (4) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)] \tag{4} Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)](4)
Sarsa算法为什么称为在线的呢,是因为行为策略和目标策略是同一个策略,即生成数据的策略和构造学习目标的策略是同一个策略。假定我们使用 ε \varepsilon ε-贪心策略(行为策略),在状态 S t S_t St处使用该策略选择动作 A t A_t At,观察到收益 R t + 1 R_{t+1} Rt+1和后继状态 S t + 1 S_{t+1} St+1(即生成数据)。然后使用同样的 ε \varepsilon ε-贪心策略(目标策略)在 S t + 1 S_{t+1} St+1选择动作 A t + 1 A_{t+1} At+1,获得 ( S t + 1 , A t + 1 ) (S_{t+1},A_{t+1}) (St+1,At+1)二元组的"状态-动作"二元组的价值函数 Q ( S t + 1 , A t + 1 ) Q(S_{t+1},A_{t+1}) Q(St+1,At+1),构造学习目标 R t + 1 + γ Q ( S t + 1 , A t + 1 ) R_{t+1}+\gamma Q(S_{t+1},A_{t+1}) Rt+1+γQ(St+1,At+1)。因此这里的行为策略和目标策略是同一个策略,下图进一步展示了这种关系。

Sarsa算法的伪代码如下所示:

\\[20pt]
3、Q-learning算法:离线策略的时序差分方法
Q-learning算法的“状态-动作”二元组的价值函数更新为:
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] (5) Q(S_t,A_t)\leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma \max_a Q(S_{t+1},a)-Q(S_t,A_t)] \tag{5} Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)](5)
Q-learning算法之所以是离线的是因为生成数据的策略(一般是 ε \varepsilon ε-贪心策略)和构造学习目标的策略(如贪婪策略)不是同一个策略,下图也给出了这种更新思想:
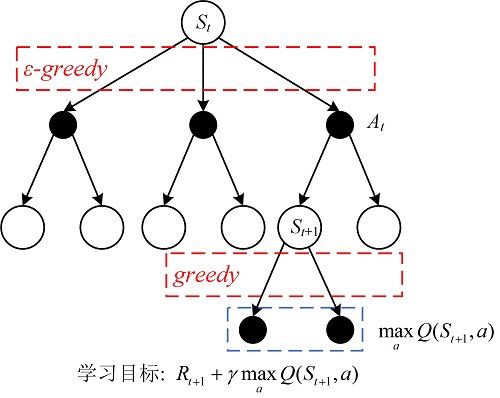
Q-learning算法的伪代码如下所示:

\\[30pt]
4、Q-learning解决寻宝问题
还是以寻宝问题作为例子来详细描述Q-learning的具体实施过程。以下为寻宝问题的网格展示,其中红色圆圈代表智能体,黑色方框代表陷阱,箱子为要寻找的宝藏,可以看出该环境有15个状态,其中有17个非终止状态和8个终止状态(包括7个陷阱和一个宝藏)。智能体在非终止状态能向左,向上,向右,向下移动,每个动作都能导致智能体移动一个网格,当智能体移除网格边缘时,保持原状态不变。我们将状态从左到右从上到下依次编号,如图中智能体的状态为0,宝藏的状态为14。
因此,状态空间 S = { 0 , 1 , 2 , . . . , 14 } \mathcal S=\{0,1,2,...,14\} S={0,1,2,...,14},对于任意的状态 s ∈ S s\in \mathcal S s∈S,有 A ( s ) = { 0 , 1 , 2 , 3 } \mathcal A(s)=\{0,1,2,3\} A(s)={0,1,2,3},其中0,1,2,3分别表示向左,向上,向右,向下移动。智能体坠入陷阱时收益为-1,找到宝藏时收益为1,其他的状态转移收益为0,折扣率 γ = 1 \gamma = 1 γ=1。

1)环境编写
这里只呈现环境的重置函数reset()和状态转移函数step()。【完整代码请单击此处】
- reset()函数的作用是重置环境为初始状态,注意我们在环境的实现中使用网格坐标来表示状态,在算法中状态0表示网格中的[0,0], 状态2表示[0,1],一直到状态14表示[4,4]。reset()函数将每个回合的初始状态重置为[0,0],即上图中红色圆圈的位置。
def reset(self):
self.current_state = [0, 0]
return self.current_state
- step()函数定义了状态的转移,智能体转移到宝藏状态时收益为1,此回合终止。智能体转移到陷阱时收益为-1,此回合终止。智能体转移到非终止状态时收益为0,此回合不终止。
def step(self, state, action):
next_state = (np.array(state) + self.ACTIONS[action]).tolist()
x, y = next_state
if next_state in self.treasure_space:
return next_state, 1, True
elif next_state in self.trap_space:
return next_state, -1, True
else:
if x < 0 or x >= self.GRID_SIZE or y < 0 or y >= self.GRID_SIZE:
next_state = state
return next_state, 0, False
2)算法实施
- 初始化“状态-动作”对的价值函数(Q表)
设置每个状态下的4个动作的价值为0。
def initialization(self):
self.Q_table= [[0.] * self.env.nA for _ in range(self.env.nS)]
- 选择动作
该函数采用 ε \varepsilon ε-贪婪策略( ε = 0.1 \varepsilon=0.1 ε=0.1)来选择动作。第1行表示,随机数大于 ε \varepsilon ε我们选择具有最大Q值的动作,注意当存在多个最大的Q值时,则随机选择一个即可。若随机数小于等于 ε \varepsilon ε,则我们随机选择一个动作。 ε \varepsilon ε-贪婪策略可以这样理解,我们绝大多数的时候选择最优动作,但保持一个小概率来随机去探索未知的状态空间。
def choose_action_e_greedy(self, state):
if np.random.random() > self.epsilon: # 选择最大Q值的动作
# 若有多个相同的最大Q值,则随机选择
action = np.random.choice(
[action_ for action_, value_ in enumerate(self.Q_table[state]) if value_ == np.max(self.Q_table[state])])
else: # 随机选择动作
action = np.random.randint(0, self.env.nA)
return action
- Q-learning学习
在learning函数中实现算法的具体学习过程,参数method用来表示当前是哪个算法,current_state表示当前状态,action为当前状态采取的动作,reward在当前状态执行动作后环境反馈的收益,next_state表示转移的下一个状态。我们关注Q-learing的学习,在第8行中根据公式 R t + 1 + γ max a Q ( S t + 1 , a ) R_{t+1}+\gamma \max_a Q(S_{t+1},a) Rt+1+γmaxaQ(St+1,a)来计算出学习目标q_target,若下一个状态为终止状态,则学习目标q_target=reward。第11行更新Q表。
def learn(self, method, current_state, action, reward, next_state):
q_predict = self.Q_table[current_state][action]
if next_state not in self.env.terminate_space:
if method == 'sarsa':
next_action = self.choose_action_e_greedy(next_state) # 目标策略也用ε-贪婪策略
q_target = reward + self.discount * self.Q_table[next_state][next_action]
else: # 'Q-learning'
q_target = reward + self.discount * np.max(self.Q_table[next_state])
else:
q_target = reward
self.Q_table[current_state][action] += self.learning_rate * (q_target - q_predict)
- Q-learning算法主体
第6行:回合开始。
第9行:将智能体寻宝宝藏的过程渲染出来。
第11行:将网格坐标转换成状态编号。
第12行:采用 ε \varepsilon ε-贪婪策略( ε = 0.1 \varepsilon=0.1 ε=0.1)来选择动作。
第13行:在当前状态state_grid采取动作action后会返回,下一个状态next_state,环境反馈的收益reward,是否到达终止状态done。
第17行:算法学习。
def Q_learning_run(self):
print('----------- Q-learning -----------')
running_reward = None
running_reward_list = []
self.initialization()
for episode in range(self.episode_number):
total_reward = 0
state_grid = self.env.reset()
self.env.render()
while True:
state_index = self.state_to_gridState.index(state_grid)
action = self.choose_action_e_greedy(state_index)
next_state, reward, done = self.env.step(state_grid, action)
total_reward += reward
next_state_index = self.state_to_gridState.index(next_state)
self.learn('Q-learning', state_index, action, reward, next_state_index)
state_grid = next_state
self.env.current_state = state_grid
self.env.render()
if done:
time.sleep(0.5)
break
# 每一次迭代获得的总收益total_reward,会以0.01的份额加入到running_reward。(原代码这里total_reward用了r,个人认为是total_reward更合适)
running_reward = total_reward if running_reward is None else running_reward * 0.99 + total_reward * 0.01
running_reward_list.append(running_reward)
print('Episode [{}/{}] | Total reward: {} | Running reward: {:5f}'.
format(episode, self.episode_number, total_reward, running_reward))
return running_reward_list
- 算法执行
我们再main中执行Q-learning算法:
if __name__ == '__main__':
env = Maze_Env.MazeEnv()
fl = MazeGame(env)
# sarsa = fl.sarsa_run()
Qlearning = fl.Q_learning_run()
# plt.plot(sarsa, label='Sarsa')
plt.plot(Qlearning, label='Q-learning')
plt.xlabel('Episodes')
plt.ylabel('Running reward')
plt.legend()
plt.savefig('Sarsa_Qlearning_maze_game.png')
plt.close()
- 实验结果
下面为输出的实验结果,可看出在17回合后,智能体已经找到了宝藏的位置,因为17回合后的total reward总是为1。但在第21回合的时候,突然变成了-1,这是因为我们采取了 ε \varepsilon ε-贪婪策略( ε = 0.1 \varepsilon=0.1 ε=0.1)来选择动作,智能体还是有一定的概率随机选择动作。另外,从画出的Running reward也可看出,算法的这种收敛趋势。
----------- Q-learning -----------
Episode [0/100] | Total reward: -1 | Running reward: -1.000000
Episode [1/100] | Total reward: -1 | Running reward: -1.000000
Episode [2/100] | Total reward: -1 | Running reward: -1.000000
Episode [3/100] | Total reward: -1 | Running reward: -1.000000
Episode [4/100] | Total reward: -1 | Running reward: -1.000000
Episode [5/100] | Total reward: -1 | Running reward: -1.000000
Episode [6/100] | Total reward: -1 | Running reward: -1.000000
Episode [7/100] | Total reward: -1 | Running reward: -1.000000
Episode [8/100] | Total reward: -1 | Running reward: -1.000000
Episode [9/100] | Total reward: -1 | Running reward: -1.000000
Episode [10/100] | Total reward: -1 | Running reward: -1.000000
Episode [11/100] | Total reward: 1 | Running reward: -0.980000
Episode [12/100] | Total reward: -1 | Running reward: -0.980200
Episode [13/100] | Total reward: -1 | Running reward: -0.980398
Episode [14/100] | Total reward: -1 | Running reward: -0.980594
Episode [15/100] | Total reward: -1 | Running reward: -0.980788
Episode [16/100] | Total reward: -1 | Running reward: -0.980980
Episode [17/100] | Total reward: 1 | Running reward: -0.961170
Episode [18/100] | Total reward: 1 | Running reward: -0.941559
Episode [19/100] | Total reward: 1 | Running reward: -0.922143
Episode [20/100] | Total reward: 1 | Running reward: -0.902922
Episode [21/100] | Total reward: -1 | Running reward: -0.903892
Episode [22/100] | Total reward: 1 | Running reward: -0.884854
Episode [23/100] | Total reward: 1 | Running reward: -0.866005
Episode [24/100] | Total reward: 1 | Running reward: -0.847345
Episode [25/100] | Total reward: 1 | Running reward: -0.828871
Episode [26/100] | Total reward: 1 | Running reward: -0.810583
Episode [27/100] | Total reward: 1 | Running reward: -0.792477
Episode [28/100] | Total reward: 1 | Running reward: -0.774552
Episode [29/100] | Total reward: 1 | Running reward: -0.756807
Episode [30/100] | Total reward: 1 | Running reward: -0.739239
Episode [31/100] | Total reward: 1 | Running reward: -0.721846
Process finished with exit code -1

下面是渲染出智能体的寻找过程:

\\[30pt]
参考资料:
(1)Richard S. Sutton and Andrew G. Barto著, 俞凯译《强化学习》第二版
(2)张斯俊. 欢迎大家入坑Reinforcment Learning【知乎】
(3)郭宪, 方勇纯. 《深入浅出强化学习:原理入门》