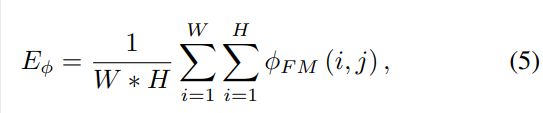<000>RGB-D Salient Object Detection: A Survey
RGB-D SOD综述
- 1. 基于RGB-D SOD的模型。
-
- 1.1 传统模型与深度模型
- 1.2 融合模型
- 1.3 单流与多流模型
- 1.4 注意模型
- 2. RGB-D SOD数据集
- 3. 评价指标
1. 基于RGB-D SOD的模型。
1.1 传统模型与深度模型
从特征提取的角度看:
(1)传统模型:手工特征。中心环绕差异、对比度、背景包围、中心/边界优先、紧凑性或各种显著性度量的组合。模型都严重依赖于启发式手工功能,导致在复杂场景中的通用性有限。
(2)深度模型:深层特征。使用深度神经网络(DNN)来融合RGB-D数据,学习高级表示,以探索RGB图像和深度线索之间的复杂相关性,从而提高SOD性能。
DF:第一个基于CNN的RGB-D SOD任务模型。将不同的低水平显著性线索集成到分层特征中,以有效定位RGB-D图像中的显著区域。
PCF:提出了一个互补感知融合模块,用于集成跨模态和跨层特征表示。它可以通过明确使用跨模态/层连接和模态/层监督来有效利用互补信息,以减少融合模糊度。
CTMF:采用计算模型,利用CNN学习RGB图像和深度线索的高级表示,同时利用互补关系和联合表示。此外,该模型从源域传输模型结构(即RGB图像)适用于目标域(即深度贴图)。
UC-Net:通过条件变分自动编码器(VAEs)提出了一种基于概率RGB-D的SOD网络为人类注释不确定性建模。它通过在学习的潜在空间中采样,为每个输入图像生成多个显著性映射。这是第一个研究基于RGB-D的SOD中的不确定性的工作,受数据标记过程的启发。该方法利用不同的显著性映射来提高最终SOD性能。
1.2 融合模型
(1)早期融合
(a)输入融合:RGB图像和深度图直接集成,形成四通道输入;
(b)早期特征融合:RGB和深度图分别被送入每个独立的网络,它们的低级表示被组合为联合表示,然后被送入后续网络以进行进一步的显著性图预测。
早期融合使用简单的串联来进行输入融合。可能很难捕捉RGB和深度视图之间的互补交互,因为这
两种类型的信息在第一阶段就混合了,但监控信号最终远离混合输入。学习过程容易出现局部最优,
仅学习RGB或深度特征,因此可能无法保证视图融合后的改进。此外,单独对RGB和深度视图进行深
度监控是不可行的。这使得学习正确的方向变得困难。
(2)晚期融合
(a)后期特征融合:采用两个并行网络流分别学习RGB和深度数据的高级特征,将其串联,然后用于生成最终显著性预测。
(b)后期结果融合:使用两个并行网络流来获得RGB图像和深度线索的独立显著性图,然后将两个显著性图串联以获得最终预测图。
晚期融合使用两个并行网络显式提取RGB和深度特征。这确保了RGB和深度视图都有助于最终决
策。此外,在该方案中应用特定于个人视图的监控非常简单。然而,该方案的缺点是无法挖掘两个视
图之间复杂的内在关联,即高度非线性的互补规则。
(3)多尺度融合:
(a)学习跨模态交互,然后将其融合到特征学习网络中。
(b)融合不同层的RGB图像和深度图的特征,然后将它们集成到解码器网络(例如,跳过连接)中,以生成最终的显著性检测映射。
中期融合是早期融合和晚期融合的补充,因为特征提取和后续融合都由相对较深的CNN处理。因
此,可以从两种模式中学习高层概念,并挖掘复杂的集成规则。同时,为RGB和深度数据添加额外的
个人深度监控非常简单。

ICNet:提出了一个信息转换模块,以交互方式转换高级特征。在该模型中,引入了跨模态深度加权组合(CDC)块,以在不同层次上使用深度特征增强RGB特征。
DPANet:]使用门控多模式注意(GMA)GMA模块利用空间注意机制提取最具辨别力的特征。此外,该模型使用门函数控制跨模态信息的融合率,从而减少不可靠深度线索带来的一些影响。
BiANet:采用多尺度双边注意模块(MBAM)在多个层面捕捉更好的全局信息。
JL-DCF:将深度图像视为彩色图像的特例,并使用共享CNN进行RGB和深度特征提取。它还提出了一种紧密协作的融合策略,以有效地结合不同模式的学习特征。
BBS-Net:使用分支主干策略(BBS)将多级特征表示拆分为教师和学生特征,并开发深度增强模块(DEM),从空间和通道视图探索深度地图中的信息部分。
1.3 单流与多流模型
(1)单流模型:通常在输入通道或特征学习部分融合RGB图像和深度信息。
MDSF:采用多尺度区分显著性融合框架作为SOD模型,其中计算三个级别的四种类型的特征,然后进行融合以获得最终显著性图。
BED:利用CNN体系结构集成SOD的自下而上和自上而下信息,还集成了多种功能,包括背景封闭分布(BED)和低层深度图(例如深度直方图距离和深度对比度),以提高SOD性能。
PDNet:使用辅助网络提取基于深度的特征,该网络充分利用深度信息来辅助主流网络。
(2)多流模型:双流模型由分别处理RGB图像和深度线索的两个独立分支组成,并且通常生成不同的高级特征或显著性图,然后将它们合并在两个流的中间阶段或结束。
1.4 注意模型
引入注意机制来衡量不同区域或领域的重要性。
ASIF-Net:使用交织融合从RGB图像和深度线索中捕获补充信息,并通过深度监督注意机制对显著性区域进行加权。
AttNet:引入了注意图,用于区分显著物体和背景区域,以减少一些低质量深度线索的负面影响。
TANet:利用自下而上和自上而下视图中的RGB图像和深度图,制定了一个多模式融合框架。然后,它引入了一个通道式注意模块来有效地融合来自不同模式和层次的补充信息。
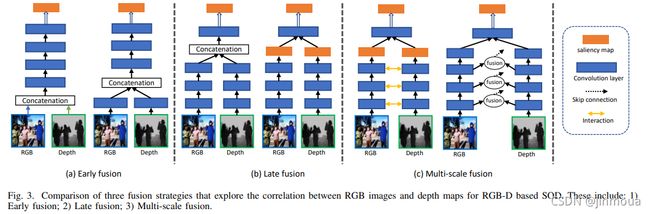
2. RGB-D SOD数据集
(1)STERE:首先从Flickr、NVIDIA 3D Vision Live和Stereoscopic Image Gallery中收集了1250张立体图像,每个图像中最显著的对象由三个用户注释。然后根据重叠的显著区域对所有带注释的图像进行排序,并选择前1000幅图像构建最终数据集。该领域的第一组立体图像。
(2)GIT:由80幅彩色和深度图像组成,这些图像是在现实家庭环境中使用移动机械手采集的。此外,基于对象的像素级分割对每个图像进行注释。
(3)DES:由135幅室内RGB-D图像组成,由Kinect以640×640的分辨率拍摄。收集该数据集,要求三名用户在每幅图像中标记显著对象,然后将标记对象的重叠区域视为基本真实值。
(4)NLPR:由1000个RGB图像及其相应的深度图组成,这些图像由标准的Microsoft Kinect获得。此数据集包括一系列室外和室内位置,例如办公室、超市、校园、街道等。第一个大规模RGB-D基准数据集。
(5)LFSD:包括使用Lytro光场摄像机采集的100个光场,包括60个室内和40个室外场景。为了标记该数据集,要求三个人手动分割显著区域,然后当三个结果的重叠超过90%时,分割结果被视为基本真实。
(6)NJUD:由1985对立体图像组成,这些图像是从互联网、3D电影和FujiW3立体相机拍摄的照片中收集的。
(7)SSD:使用三部立体声电影构建,包括室内和室外场景。该数据集包含80个样本,每个图像的大小为960×1080。
(8)DUT-RGBD:由800个室内和400个室外场景和相应的深度图组成。该数据集包括几个具有挑战性的因素,即多个或透明对象、复杂背景、类似的前景和背景以及低强度环境。
(9)SIP:由929张带注释的高分辨率图像组成,每张图像中有多个突出人物。在这个数据集中,深度图是使用真正的智能手机(即华为Mate10)捕获的。此外,值得注意的是,该数据集涵盖了各种场景和各种挑战性因素,并使用像素级的真值进行了注释。
3. 评价指标
(1)PR(precision-recall):给定一个显著性图S,我们可以将其转换为二进制掩码(mask),然后通过与地面真实值进行比较来计算精度和召回率。
M :显著性图S转化为二进制掩码; G :真值图; |·| :图内掩码的总面积。

一种流行的策略:使用一组阈值(即,它从0变为255)对显著性图进行分区。对于每个阈值,我们首先计算一对召回率和准确度分数,然后将它们结合起来,得到描述模型在不同阈值下性能的PR曲线。
(2)F-measure:为了综合考虑精度和召回率,通过计算加权调和平均值,提出了F-measure。
β是precision和recall之间的权重,设置β^2=0.3以强调精度。我们使用不同的固定[0,255]阈值来计算F-measure度量。这产生了一组度量值,我们报告了它们的最大值或平均值Fβ。

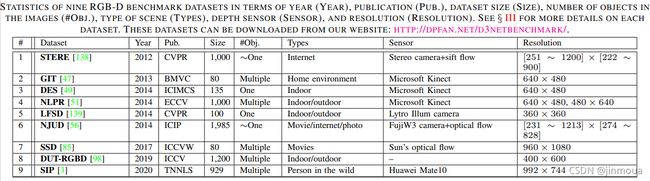
(3)MAE(mean absolute error):衡量预测的显著性图S和真值图G之间所有像素的平均像素级绝对误差。
W、H:分别表示地图的宽度和高度。MAE值标准化为[0,1]。
(4)S-measure:评估区域感知(Sr)和对象感知(So)之间的结构相似性,捕获图像中结构信息的重要性。
α∈ [0,1]是一个协调参数。默认设置α=0.5。

(5)E-measure:基于认知视觉研究提出,用于捕获图像级统计信息及其局部像素匹配信息。
фFM:增强对准矩阵。