机器学习——评估和改进学习算法
0. 引言
当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么?
- 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
- 尝试减少特征的数量
- 尝试获得更多的特征
- 尝试增加多项式特征
- 尝试减少正则化程度 λ \lambda λ
- 尝试增加正则化程度 λ \lambda λ
我们不应该随机选择上面的某种方法来改进我们的算法,而是运用一些机器学习诊断法来帮助我们知道上面哪些方法对我们的算法是有效的。
1. 评估一个假设
当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化,但是仅仅是因为这个假设具有很小的训练误差,并不能说明它就一定是一个好的假设函数。我们学习了过拟合假设函数的例子,这种过拟合的假设函数推广到新的训练集上是不适用的。

那么,该如何判断一个假设函数是过拟合的呢?对于一个简单的例子,我们可以对假设函数 h ( x ) h(x) h(x)进行画图,然后观察图形趋势,但对于特征变量不止一个的这种一般情况,还有像有很多特征变量的问题,想要通过画出假设函数来进行观察,就会变得很难甚至是不可能实现。
因此,我们需要另一种方法来评估我们的假设函数过拟合检验。
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。

测试集评估在通过训练集让我们的模型学习得出其参数后,对测试集运用该模型,我们有两种方式计算误差:
-
计算代价函数
对于线性回归模型,我们利用测试集数据计算代价函数 J J J
对于逻辑回归模型,我们除了可以利用测试数据集来计算代价函数外:
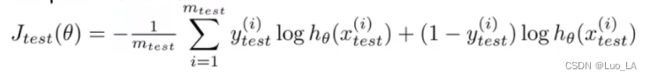
-
使用0/1错误分类度量来定义测试误差
计算错误分类误差:
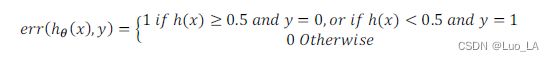
然后对计算结果求平均值,得到测试误差。
2. 模型选择和交叉验证机
假设我们要在10个不同次数的二项式模型之间进行选择:

显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。我们需要使用交叉验证集来帮助选择模型。
即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集
模型选择的方法为:
- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
- 选取代价函数值最小的模型
- 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
Train/validation/test error
Training error:
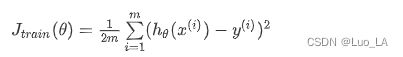
Cross Validation error:
![]()
Test error:

3. 诊断偏差和方差
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。高偏差和高方差的问题基本上来说是欠拟合和过拟合的问题。
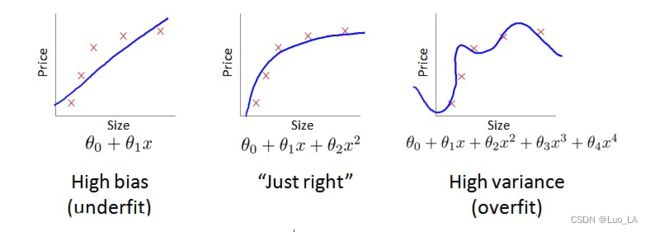
我们将训练集和交叉验证集的代价函数误差 e r r o r error error 与多项式的次数 d d d 绘制在同一张图表上来帮助分析:
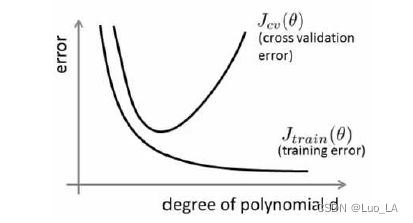
对于训练集,当 d d d 较小时,模型拟合程度更低,误差较大;随着 d d d 的增长,拟合程度提高,误差减小。
对于交叉验证集,当 d d d 较小时,模型拟合程度低,误差较大;但是随着 d d d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
根据上面的图表,我们知道:
• 训练集误差和交叉验证集误差近似时:偏差/欠拟合
• 交叉验证集误差远大于训练集误差时:方差/过拟合:
4. 正则化和偏差/方差
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能会正则化的程度太高或太小了,即我们在选择λ的值时也需要思考与刚才选择多项式模型次数类似的问题。
我们选择一系列的想要测试的 λ \lambda λ 值,通常是 0-10之间的呈现2倍关系的值(如: 0 , 0.01 , 0.02 , 0.04 , 0.08 , 0.15 , 0.32 , 0.64 , 1.28 , 2.56 , 5.12 , 10 0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10共12个)。 我们同样把数据分为训练集、交叉验证集和测试集。

选择 λ \lambda λ的方法为:
- 使用训练集训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
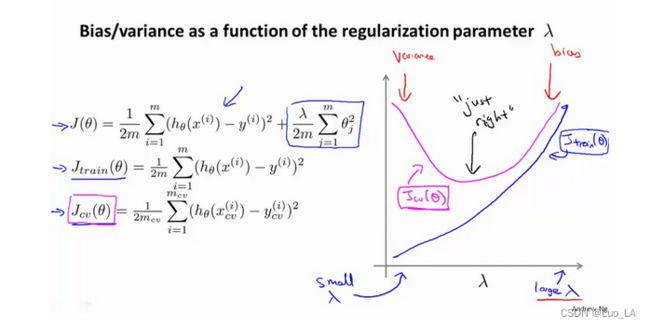
• 当 λ \lambda λ 较小时,训练集误差较小(过拟合)而交叉验证集误差较大
• 随着 λ \lambda λ 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
5. 神经网络的方差和偏差
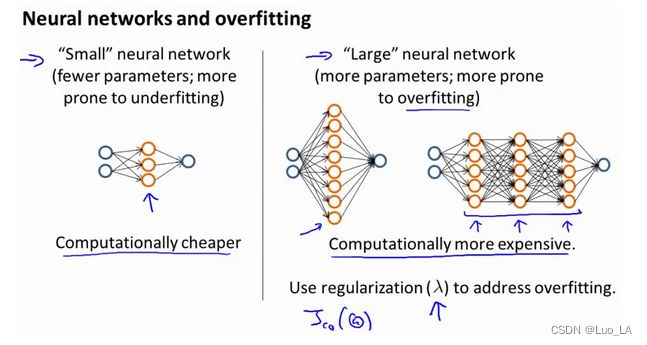
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,然后选择交叉验证集代价最小的神经网络。