第3章 卷积GAN和条件式GAN:3.1 卷积GAN2
3.1.7 CelebA CNN
接下来,让我们将卷积层应用于GAN。
CelebA数据集中的图像是217像素× 178像素的长方形。为了简化卷积过程,我们将使用128像素× 128像素的正方形图像。这意味着我们需要先对训练图像进行裁剪。
以下代码是一个辅助函数,可以从一个numpy图像中裁剪任意大小的图像。裁剪的区域位于输入图像的正中央。

要从一个较大的图像img中心截取一个128像素× 128像素的正方形区域,我们使用crop_centre(img, 128, 128)。
在笔记本中,我们需要将该辅助函数移到Dataset类的上方,因为我们会在Dataset类的定义中使用crop_centre()。下面的代码分别更新了__getitem__()方法和plot_image() 方法。从HDF5数据集中读取一个图像后,先将它裁剪成一个128像素× 128像素的正方形图像。
getitem()需要返回一个张量,并且是一个四维张量的形式(批次大小,通道,高度,宽度)。numpy数组是形式为(高度,宽度,3)的三维张量,permute(2,0,1)将numpy数组重新排序为(3,高度,宽度)。view(1,3,128,128)为批量大小增加了一个额外的维度,设置为1。
让我们看一下Dataset类是否能正确地裁剪图像。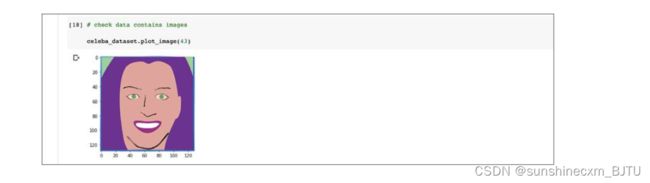
可以看到,图像被裁剪成了一个较小的128像素× 128像素的正方形图像。
不同于完全连接层,卷积层输出的大小并不是很直观。在设计卷积网络时,纸和笔会很有帮助。有些人喜欢通过画出输入张量、卷积核和步长的草图来帮助理解,就像我们在前两章做的那样;有些人喜欢只在代码上做实验,用错误信息来引导自己调整卷积核和步长;也有些人会使用像附录C中的公式或PyTorch参考页上的nn.Conv2d()的公式,直接计算输出的大小。
我们的网络应该有多少层呢?网络的中间层应该有多少个卷积核呢?正如我们在《Python神经网络编程》中所讨论的,这个问题没有简单的答案。我们应该尽量构建最小的网络,这样训练起来比较容易,但也不能小到失去学习能力。我们还应该注意区分,网络像分类器一样缩减数据,还是像生成器一样扩展数据,这对设计网络会有帮助。
下图中的网络有3个卷积层和1个最后的全连接层。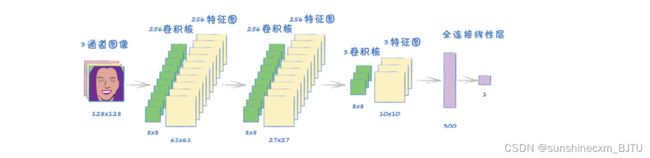
第一个卷积层取3通道彩色图像,应用256个卷积核,输出256个特征图。由于卷积核大小为8×8,步长为2,所以特征图的大小为61像素× 61像素,小于128像素× 128像素的输入图。
下一个卷积层也一样,有256个大小为8×8的卷积核,步长为2。从这一层中,我们仍然得到256个特征图,不过特征图大小进一步缩小到27×27。当接近网络的末端时,我们需要考虑减少数据。
下一个卷积层只有3个卷积核,但同样是8×8的大小和步长2,这就给了我们3个大小为10×10的特征图。我们需要将这300个值缩减到一个鉴别器的输出值。我们也可以使用更多的卷积层来缩减数据。不过,为了汇总图像的关键特征,300个值已经足够小了。我们可以使用一个简单的全连接线性层来将它们映射到输出。
以下代码实现了鉴别器的网络设计。
代码中并没有什么新的东西要讨论,所有的元素我们都已经见过。值得注意的是,我们使用View()将最后一个大小为(1,3,10,10)的特征图重塑为一个简单的一维张量。张量的大小为300,可以直接传递给线性层。
读者可能会注意到,这段代码中出现了31010,而不是300。这是为了帮助阅读代码的人理解这个数字的来源——这是一个很好的编程习惯。
为了测试鉴别器对随机像素图像的判别能力,我们需要修改代码,使enerate_random_image()创建大小为(1, 3, 128, 128)的四维张量。这个改变非常简单,因为我们在编写随机值辅助函数的时候,就考虑到了这一需求,并把张量的形状作为参数。
运行训练循环需要大约10分钟。下图显示了训练过程中的损失值变化。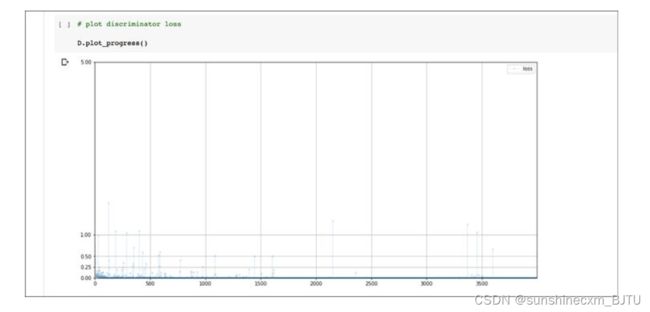
从上图中可见,损失值很快降至0附近。值得注意的是,图中噪声非常少。之前测试网络时常见的高低值跳跃现象,在这里非常少见。
让我们手动测试一下鉴别器区分真实图像和随机生成样本的得分。记得修改随机图像生成函数来输出大小为(1,3,128,128)的张量。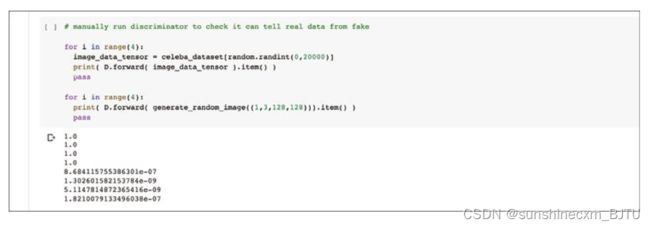
从分数来看,置信度的确非常高。这说明我们的鉴别器网络是非常有效的。
接着,让我们来思考一下生成器网络,这意味着我们的笔和纸又要派上用场了。我们将遵循一个原则,即生成器应该是鉴别器的镜像。这样一来,它们谁也不比谁强,谁也不比谁弱。
在开始画设计图时,我们可能会问,什么是卷积计算的反义词?卷积将较大的张量缩减成较小的张量,而反卷积则需要将较小的张量扩展成较大的张量。
PyTorch将这种反向卷积称为转置卷积(transposed convolution),需要调用的模块是nn.ConvTranspose2d。
下图说明了转置卷积的工作原理。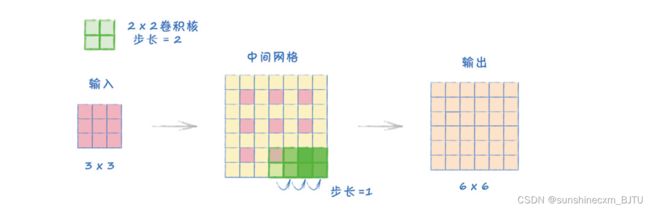
在上图中,输入张量的大小是3×3,卷积核的大小是2×2,步长是2。
转置卷积的工作原理是,卷积核在中间网格上移动,跨度为1,而不是2。这个中间网格是由输入张量扩展得到的。首先,我们在输入的每两个方格中间添加0值方格。这样一来,原输入值之间的距离就等于步长,也就是2。接着,我们在网格的四周全部添加0值方格。这么做的目的是,保证卷积核至少可以覆盖一个原输入值。图中的输出张量大小为6×6。
这种扩展张量的方法看起来可能过于复杂。但它的主要好处在于,它可以抵消同等配置的卷积效果。例如,如果我们把输出的6×6张量,用2×2的卷积核和步长2进行卷积,我们又会得到一个3×3张量。在一些特殊情况下,反转并不精确,需要额外的填充。
读者可以在附录C中找到更详细的步骤和案例。
下图是一个卷积网络架构,它以一个大小为100的种子为输入,最终产生一个形状为(1,3,128,128)的张量。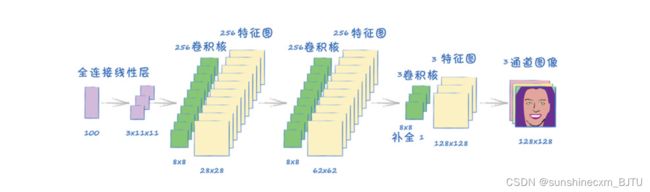
要设计一个神经网络,用于将张量扩展到合适大小,需要经过几个步骤。这个网络看起来非常像是鉴别器的镜像,这很好。
- 起始端有一个全连接层,它将100个种子值映射到3×11×11的张量。
- 接着,它被转换成转置卷积层所需要的四维(1,3,11,11)张量。
- 最后一步,转置卷积层需要一个额外的设置,即补全padding=1,作用是从中间网格中去掉外围的方格。如果没有补全,要想让输出的大小为(1,3,128,128),则需要增加网络本身的参数。
在卷积生成器网络的末端增加一个全连接层,看起来是一个更直接的解决方案。不过,我们应该避免这样做,因为我们希望用局部特征生成最终的图像。
下面的代码定义了生成器神经网络。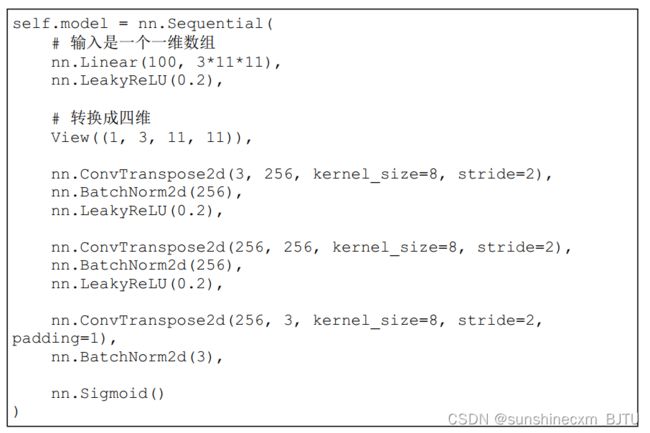
这段代码实现了我们的设计思路。首先,它用一个全连接层将 100 100 100个种子值映射到 3 ∗ 11 ∗ 11 3*11*11 3∗11∗11的张量,再转换成 P y T o r c h PyTorch PyTorch的卷积模块所需要的四维 ( 1 , 3 , 11 , 11 ) (1,3,11,11) (1,3,11,11)张量。转置卷积模块有3个,每个卷积核大小为8,步长为2。前两个转置卷积模块有256个卷积核,最后一个转置卷积模块减少到3个卷积核。因为输出张量需要有3个通道,红、绿、蓝像素值各占一个通道。最后一个卷积有额外的补全设置 p a d d i n g = 1 padding=1 padding=1。
让我们检查一下,未经训练的生成器是否可以生成一个包含随机像素值的图像,并且形状是正确的。我们需要使用permute(0,2,3,1)和view(128,128,3),对生成器中的四维张量重新排序,以便绘制图像。
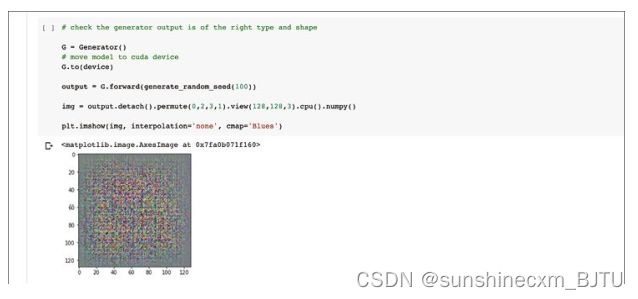
未经训练的生成器确实能生成一个符合大小的图像。它的像素值看起来像是随机的,但如果我们仔细观察,似乎可以看出一个棋盘的图案。同时,图像的边缘也有一个颜色较暗的区域。是不是我们的代码出错了?
其实代码并没有出错。当我们通过一系列的转置卷积构造图像时,特征图的重叠,特别是当步长不是卷积核大小的倍数时,就会导致棋盘图案的出现。边界较暗的原因是,图像边缘的重叠较少,贡献值也较少。当我们训练生成器时,它将学习到正确的权重。
在做完所有准备工作后,我们终于可以训练GAN了。我们不需要对训练循环代码进行任何修改,先试着训练一个周期。训练一个周期大约需要15分钟。下图是训练过程中鉴别器损失值的变化。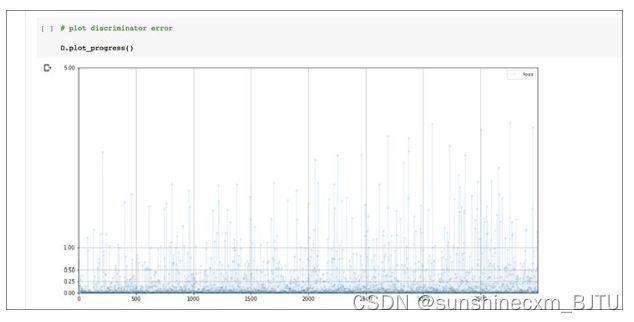
损失值非常迅速地降至0,并保持在低位。这比混乱的、不稳定的损失图要好。但是,如果能接近理想的损失值0.693就更好了。在训练快要结束时,损失值好像有了开始上升的迹象。
让我们看一下生成器损失值的变化。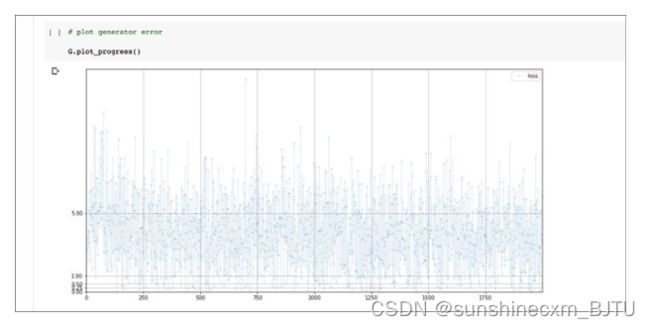
损失值看起来还不错,没有很混乱。但即便损失值高于理想值,它仍在缓慢下降。可能需要训练更久一些。
再让我们看一下训练一个周期后,生成器生成的图像效果。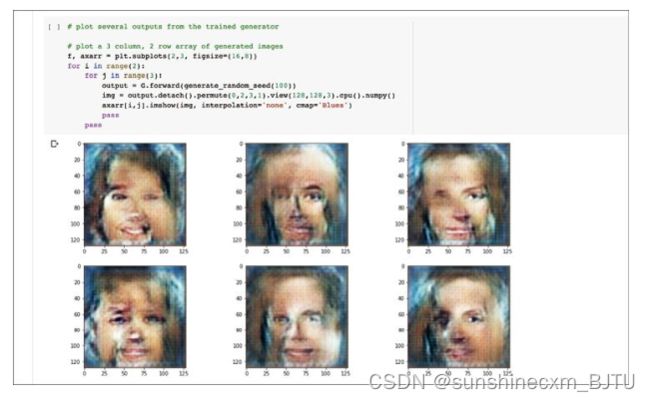
太好了!我们的卷积GAN可以生成具有基本人脸特征的图像了。其中多数有两只眼睛、一个鼻子和一个嘴巴,很多时候还有头发。虽然图像质量不是很高,但我们取得的成绩还是值得肯定的。
这些图像由卷积神经网络学到的高、中、低层次的局部特征,按层次结构组合而成。当然,这些特征并不是从训练数据中复制过来的。它们的排列方式,比如眼睛在鼻子上方、鼻子在嘴巴上方等,都是通过欺骗辨别器学会的。这真是太酷了!
同时,我们也应该感到非常幸运。因为我们似乎避免了模式崩溃,因为生成的图像是多样的。
与此同时,让我们检查一下卷积GAN的内存消耗情况,看看它是否比我们之前创建的全连接GAN的内存消耗要低。
在整个笔记本运行完成后,分配给所有张量的内存仍然只有0.14GB。这主要是因为鉴别器对象和生成器对象仍然存在。之前的全连接GAN的内存是0.70GB。所以,我们的卷积GAN只有全连接GAN消耗的内存的20%左右。这是一个了不起的改良。
再看看张量的内存消耗峰值,现在是0.20GB。相比之前的1.1GB,同样只有20%左右。
我们来看看更长时间的训练是否能改善图像质量。下图是在训练1、2、3、4、6和8个周期后生成的图像。我们把它们一起显示,方便比较图像质量。
刚开始,图像质量不是很好。随着训练的进行,生成人脸的质量开始变好。有些脸孔具有更真实、更细腻的皮肤。同时,我们也成功地避免了模式崩溃,可以生成多样化的人脸和姿势角度。但即便如此,并不是每幅图像都是好的。我们尚不清楚更长时间的训练是否能解决这个问题。也可能我们这个相对简单的网络架构有着固有的局限性。
再看看这些图像,它们看起来像是由一组碎片补丁拼凑成的。比如说,有的图像中,一只眼睛和另一只眼睛可能有很大的差别。又比如,在一些图像中,发型的一半与另一半是不一样的。在全连接GAN中,我们没有遇到过类似的情况。这是因为,卷积网络中每一个特征的生成,都是在缺乏上层图像的完整视角的情况下进行的。卷积网络有意地先缩小焦点再生成图像,这样做既有利也有弊。
3.1.8 自己动手试验
读者可以通过尝试自己的想法来改良GAN。
比如,我们可以尝试不同类型的损失函数、不同大小的神经网络,甚至可以改变基本的GAN训练循环。或许,我们可以尝试在损失函数中增加一个指标来衡量输出的多样性,从而避免模式崩溃。
如果有信心,读者也可以尝试实现自己的优化器,做一个更适合GAN的对抗性的优化器。
下面,我用一个名为GELU的激活函数做了一个简单试验。这个函数类似于ReLU,但拐角更柔和。不少人认为,GELU是目前最优的激活函数,因为它提供了很好的梯度,而且在原点周围没有尖锐的不连续性。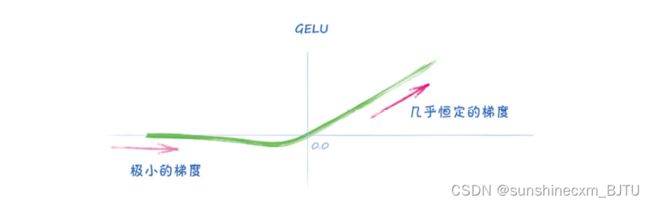
我们用nn.GELU()取代原来代码中的nn.LeakyReLU(0.2)。模型经过训练后生成以下图像。
虽然没有进行科学的测试,但是仅通过观察比较就可以发现,使用GELU激活函数后的图像质量的确略有提高。
下图是训练10个和12个周期后生成的图像。
其中,一些图像的真实度着实令人印象深刻。进一步的训练可能会进一步提高图像质量,但实际上,许多简单的GAN架构最终会崩溃,图像质量会退步并发生模式崩溃。
在附录D中,我们从理论上讨论为什么使用梯度下降法训练GAN可能存在根本性缺陷。
3.1.9 学习要点
- 最先进的图像分类神经网络利用有意义的局部化特征。可识别的对象是由具有层次结构的特征构成的。低层次细节特征组成中层次特征,中层次特征本身又组成高层次对象。
- 卷积神经网络通过卷积核从一幅输入图像中生成特征图。指定的卷积核可以识别出图像中的特定图案。
- 神经网络中的卷积层可以针对具体任务学习合适的卷积核,也就是说,网络不需要我们直接设计特征,即可学到图像中最有用的特征。使用卷积层的神经网络在图像分类任务上的表现,优于同等大小的全连接网络。
- 卷积模块缩减数据,同样配置的转置卷积模块可以抵消这种缩减。因此,转置卷积是生成网络的理想选 择。
- 基于卷积网络的GAN,通过将低层次特征组成中层次特征,再由中层次特征组成高层次特征来构建图像。实验表明,由卷积GAN生成的图像质量高于同等大小的全连接GAN。
- 与全连接GAN相比,卷积GAN占用的内存更少。在GPU内存受到限制时,这是处理较大大小的图像文件时需要考虑的一个因素。我们看到卷积GAN的内存使用只有全连接GAN的20%左右。
- 卷积生成器的一个缺点是,它可能生成由相互不匹配的元素组成的图像。例如,包含不同眼睛的人脸。这是因为卷积网络处理的信息是局部化的,而全局关系并没有被学习到。