基于YOLO的谱面识别与检索【Python环境实现】
文章目录
-
一.YOLO模型结构学习与介绍
-
1.模型结构下载
-
2.模型结构介绍
-
二.YOLO模型包训练输出结果调试
-
三.YOLO模型乐谱识图训练过程
-
1.训练集路径设置
2.修改配置文件
3.数据集标注与导入
4.硬件环境
5.修改train.py并开始训练
-
四.调用detect函数并编写匹配程序输出结果
-
1.修改配置参数
2.运行并得到图片输出
3.修改detect.py得到字符化谱面
a.音符的字符化保存
b.自动扫描检索库的乐谱
4.随机乐谱与库进行匹配
-
五.结果分析
-
六.算法分析
前言
随着个人微机硬件性能的不断发展,机器学习这门技术也越来越成熟。在图像检测模型中,YOLO是一个相对来说比较成熟的模块。本文重在讲解训练YOLO模型,以及调用YOLO模型的训练成果输出检测结果和库匹配的过程。
项目背景
在现代社会的日常生活中,由于乐器的普及和五线谱的规范化,使用五线谱的人数日益增加,而谱面由于其在艺术上的灵活性:可以修改和旋,升降调,即兴创作等,即使是同一首乐曲,可能经过多次创作以后,谱面的区别是非常明显的。传统的图像识别存在一定的困难。
设计方案
由于实现乐谱的匹配,首先在于图像的检索。即要识别谱面上音符的坐标,并返回音符的坐标,再对输入的乐谱和检索库乐谱集的音符坐标按照某种算法进行匹配。故本文按这一思路进行分析讲解。
#本文重在记录和展示课题设计的过程,有不足之处欢迎指出,算法上有待进一步的改进。
一.YOLO模型结构学习与介绍
1.模型结构下载
YOLOv5的代码是开源的,因此我们可以从github上克隆其源码。yolov1-v3版本都是由原作者本人维护代码和更新,后续版本由他人制作。yolov5发布才一年左右的时间,YOLOv5就已经更新了5个分支了,分别是yolov5.1-yolov5.5分支。本小组实验项目就是利用的yolov5.0分支来作为模型。
首先打开yolov5的github的官网,网址https://github.com/ultralytics/yolov5/tree/v5.0打开的官网界面如下,这个就是大神glenn-jocher开源的yolov5的项目。可以提供完整的项目文件夹下载:

2.模型结构介绍
yolov5-master
├── data:主要是存放一些超参数的配置文件(yaml文件)这些文件是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不放在这个路径下面,而是把数据集放到yolov5项目的同级目录下面,以保护原数据。
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用它导入相应版本的包。

二.YOLO模型包训练输出结果调试
YOLO下载完成后,原完成训练的模型可以直接输出,配置pt文件网址如下:
https://github.com/ultralytics/yolov5/releases
配置完成后运行detect.py函数,输出结果如下所示,为运行成功。

在根目录的\runs\detect\exp t(t为运行输出次数)目录下,保存输出结果
根据终端输出的文件路径,找到运行结果如下:


三.YOLO模型乐谱识图训练过程
1.训练集路径设置
为了不影响根目录下的文件选择单独建立一个文件夹,为其命名为node,当然改为其他名称也可以。但是其下的文件夹必须按照这样的结构来命名:其中images文件夹保存训练和输出的照片,分别对应文件夹train和test,而labels文件夹保存训练和输出的标注文件(YOLO只支持.txt文件格式的标注集)
而node_model.pt和node_model.yaml以及node_parameter.yaml都是训练数据集用的配置文件和pytorch模型文件。其来源为原YOLO模型的训练文件,只有node部分可以替换成任意名称,否则可能出现寻址失败,找不到文件等错误。

2.修改配置文件
a.将yolov5/data/coco128.yaml复制,粘贴至node目录下,改名为node_parameter.yaml,需要修改的参数是nc与names。nc是标签名个数,names就是标签的名字
且因为对乐谱而言,谱线和小节线都是标准的直线,可以使用霍夫直线检测来得到坐标,不需要训练。所以在此不标注。
其中path是在根目录绝对路径
train是在node文件夹下的相对路径
val是验证集,可以使用同一个路径
test可不填
而由于本文不深入讨论YOLO模型的结构和更深层次应用,故在此不讨论验证集的区别,详见如何正确使用机器学习中的训练集、验证集和测试集?_nkwshuyi的博客-CSDN博客

b.在yolov5/models/yolov5s.yaml(或yolo5x.yaml,yolo5l.yaml)复制,粘贴至node目录下,更名为node_model.yaml,只将如下的nc修改为训练集种类即可。由于在乐谱识别的例子中有不定量的标签,故设置音符数量的最大值如下:

一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载:
https://github.com/ultralytics/yolov5/releases
yolov5有4种配置,不同配置的特性如下,我这里选择yolov5x,效果较好,但是训练时间长,也比较吃显存


3.数据集标注与导入
训练集可以采用公开数据集:DeepScores
网址为 https://tuggeluk.github.io/deepscores/,其中包括各种乐谱符号的标注json文件

数据集下载网址如下所示,其中包括完整版和精简版两种下载包。一般选择精简版就可以获得比较好的训练效果。
DeepScoresV2 | ZenodoThe DeepScoresV2 Dataset for Music Object Detection contains digitally rendered images of written sheet music, together with the corresponding ground truth to fit various types of machine learning models. A total of 151 Million different instances of music symbols, belonging to 135 different classes are annotated. The total Dataset contains 255,385 Images. For most researches, the dense version, containing 1714 of the most diverse and interesting images, is a good starting point. The dataset contains ground in the form of: Non-oriented bounding boxes Oriented bounding boxes Semantic segmentation Instance segmentation The accompaning paper The DeepScoresV2 Dataset and Benchmark for Music Object Detection published at ICPR2020 can be found here: https://digitalcollection.zhaw.ch/handle/11475/20647 A toolkit for convenient loading and inspection of the data can be found here: https://github.com/yvan674/obb_anns Code to train baseline models can be found here: https://github.com/tuggeluk/mmdetection/tree/DSV2_Baseline_FasterRCNN https://github.com/tuggeluk/DeepWatershedDetection/tree/dwd_old https://zenodo.org/record/4012193
若只标注音符的位置,则需要利用数据集自己标注TXT文件:
一般100张左右单行谱面的图片训练可以达到比较好的效果,这是YOLO的识别原理和图像分割相关导致的。而DeepScores数据集都是完整的谱面,这里就涉及到批量裁剪图片:这里直接给出批量裁剪的python源程序:
from PIL import Image
import os
import os.path
import numpy as np
import cv2
# 指明被遍历的文件夹
rootdir = r'C:/Users/16934/Desktop/images'
for parent, dirnames, filenames in os.walk(rootdir): # 遍历每一张图片
filenames.sort()
for filename in filenames:
# print('parent is :' + parent)#parent is :/home/mmediting/data/4K/valid/gt/000
# print('filename is :' + filename)#filename is :00000084.png
currentPath = os.path.join(parent, filename)
print(
'the fulll name of the file is :' + currentPath) # the fulll name of the file is :/home/mmediting/data/4K/valid/gt/000/00000084.png
img = Image.open(currentPath)
# print (img.format, img.size, img.mode)#PNG (3840, 2160) RGB
# 设置左、上、右、下的像素
# gt
# box1 = (0, 0, 1920, 1080)
# box2 = (0, 1080, 1920, 2160)
# box3 = (1920, 0, 3840, 1080)
# box4 = (1920, 1080, 3840, 2160)
# lr
box1 = (0, 0, 960, 270)
box2 = (0, 270, 960, 540)
box3 = (120, 0, 1920, 270)
box4 = (120, 270, 1920, 540)
image1 = img.crop(box4) # 图像裁剪
##存储裁剪得到的图像
image1.save(r"C:/Users/16934/Desktop/train-ready" + '/' + filename)4.硬件环境
DELL G3 已升级到32G内存,2T机械硬盘,机带16G显存。在训练的时候内存占用率达到60%,16G的内存也可以胜任。


5.修改train.py并开始训练
在train.py中找到
def parse_opt(known=False):

训练模型文件,数据集参数文件
修改对应路径即可
parser.add_argument('--weights', type=str, default='yolov5x.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT/'node/node_model.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'node/node_parameter.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')训练轮数,决定了训练时间与训练效果。如果选择训练模型是yolov5x.yaml,那么大约200轮数值就稳定下来了(收敛)笔者设置了300轮训练。
parser.add_argument('--epochs', type=int, default=300, help='total training epochs')device驱动 代表GPU加速,填0是电脑默认的CUDA,前提是电脑已经安装了CUDA才能GPU加速训练
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')之后运行train.py即可开始训练:

如上即为训练正常。
在训练结束后,在根目录下的runs\train\exp t \weights内可以找到训练结果:
(t为训练轮数,训练结果会新建一个exp文件夹,笔者展示的结果是在\runs\train\exp16\weights)
其中best为最好的一次训练,last为最后一次训练的模型文件。
四.调用detect函数输出结果

1.修改配置参数
如上修改参数:
weights填刚刚训练好的权重文件路径,笔者使用的是best.pt
source待检测的文件,可以是图片、视频、摄像头。填0时为打开电脑默认摄像头
data为配置文件路径
conf-thres置信度,当检测出来的置信度大于该数值时才能显示出被检测到
2.运行并得到图片输出
在根目录的\runs\detect\exp t(t为运行输出次数)目录下,保存输出结果:


可以看到,训练结果不错。对YOLO的调试到此。接下来要修改detect.py,使他能够输出每个音符的坐标:
3.修改detect.py得到字符化谱面
由于检索的库有非常多的谱面数据,所以应该修改detect.py,使得其能循环检测某路径下的所有图片文件,并将扫描返回的坐标保存在与图片一一对应的TXT文件中
a.音符的字符化保存
在def run函数下的for *xyxy, conf, cls in reversed(det):循环下:
将if save_crop:
save_one_box两行注释,并补上如下代码,可以输出音符的y坐标:
由于YOLO模型以左上角为原点,向左为x轴,向下为y轴。故所有坐标都是正数,而y1,y2都是识别框的坐标,故利用长度平均:
![]()
可以得到一个音符的纵坐标
x1 = int(xyxy[0].item())
y1 = int(xyxy[1].item())
x2 = int(xyxy[2].item())
y2 = int(xyxy[3].item())
class_index = cls # 获取属性
object_name = names[int(cls)]
y=0.5*(y1+y2)
print('bounding box is', y)
但是得到的坐标值存在一定的误差,如果直接拿坐标进行匹配,在匹配时难以得到准确的匹配值。而两个音符点间最小的间隔是一个整音(由于笔者的训练模型未标记升降音符号,故最小间隔是一个整音 。故可知音符在谱面上的位置是离散的,故可以通过一些对应规则将音符差转化为对应的字符存储(也行还有其他更好的匹配算法,详见后续算法分析)

对YOLO而言,相邻坐标相差1,在图像上仅相差一个像素点,故可以考虑以50像素点为区间,将差值转化为字符,代码如上:这是一种简单直接的分割方法。但是很明显不够精准。(精准的方法是利用opencv的霍夫直线检测返回的行间距作为基准,详见后续算法分析。)再循环内补上输出打印字符的函数open(),要注意的是:每次循环只能确定一个y值,所以open()函数的参数'a'不可以省略,否则后续字符只会覆盖前一次循环的字符。再运行detect.py,此时可以获得一个乐谱转化的TXT文件。

b.自动扫描检索库的乐谱
如前述,这里涉及到对检索库的所有乐谱进行字符化保存。将detect.py复制一份,重命名为node-scan.py。这是为了方便后续对单独的输入谱进行分析:detect.py用于扫描检索库,修改固定的路径为含变量路径,node-scan.py用于扫描输入文件。
但是一般检索库的文件名称没有规律。这就涉及到对文件批量改名的程序段:直接给出代码如下
import os
#设定文件路径
path='C:\\Users\\16934\\Desktop\\jpgs'
i=1
#对目录下的文件进行遍历
for file in os.listdir(path):
#判断是否是文件
if os.path.isfile(os.path.join(path,file))==True:
#设置新文件名
new_name=file.replace(file,"%d.png"%i)
#重命名
os.rename(os.path.join(path,file),os.path.join(path,new_name))
i+=1
#结束
print ("End")转化结果如下:此时所有库中乐谱都是顺序命名的,只要修改detect.py中的两个路径,嵌入参数即可实现循环检测:应注意的是:修改路径名称的循环应该在整个detect.py的外层,这是由于一次扫描要整个程序才可以完成,不可以从中间拆断。(由于修改位置过于零散,故这里不粘贴代码,详见评论区下载地址)

运行修改后的detect程序,可以看到检索库中所有的乐谱都已经字符化了。

4.随机乐谱与库进行匹配
总的来说,不分小节的字符串匹配可以直接使用类似模式匹配的方法实现:即输入的随机乐谱可能不全,即只是某个库中乐谱的一部分。由于时间关系,笔者直接使用difflib库的文本相似度匹配SequenceMatcher类:库的详细介绍参考下述链接:
文本相似度-python之difflib库SequenceMatcher类_minosisterry的博客-CSDN博客
利用库函数,将匹配部分最长的乐谱名称从数组中筛选出来:由于之前命名是按顺序命名,故直接打印循环计数器的数值,即为乐谱名。代码如下:
count_search=1
p=1
with open("nodetxt/node.txt", "r") as f: # 打开文件
data1 = f.read() # 读取文件
res={}
for count_search in range(1,152):
path = "run/test" + str(count_search) + ".txt"
with open(path, "r") as f: # 打开文件
data2 = f.read() # 读取文件
s = difflib.SequenceMatcher(None, data1, data2)
m=s.find_longest_match(1, None, 1, None)
count_search+=1
p+=1
print(m)
print(count_search)
res[count_search]=m#将每次循环的数据写入
res=sorted(res.items(),key=lambda item:item[1].size,reverse=True)
for i in range(10):
print(res[i])五.结果分析
笔者选择的最直接的将音符转化为字符串模式匹配的运行效果可以大概检测乐谱,若搜索原图,可以搜索出准确的结果:如下所示:

size=319的即为匹配结果
检索结果如下图所示:

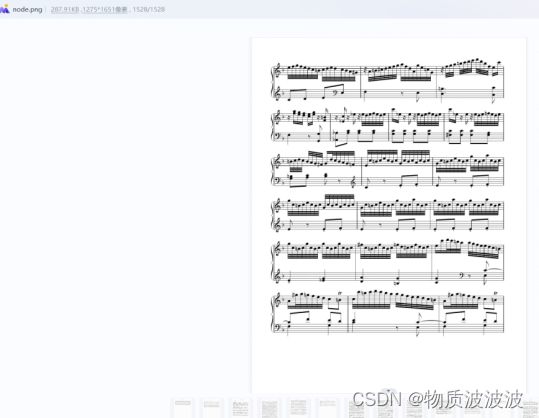
分析可知:当输入的随机谱面越大,音符越多,第一长的匹配块会比后续的大很多很多,故识别是非常准确的。
但是如果图片被裁剪,效果并不太好,因为库中某文件的音1234可能和输入文件的2345非常相似。从而导致识别率低。
六.算法分析
精准的方法是利用opencv的霍夫直线检测返回的行间距作为基准,用相邻音符纵坐标差值除以五线谱行间距,从而得到准确的音符位置。
即设行间距为
则可以用![]() 确定音符的对应字符:
确定音符的对应字符:

霍夫直线检测代码实现如下:关于其原理,不在本文的讨论范围之内。且由于直线检测的准确度高,故没有必要用深度学习进行标注训练。而笔者由于时间关系暂时没有实现霍夫直线检测部分和主函数的拼接。
import cv2
import numpy as np
img = cv2.imread('node/datasets/images/test/node.png')
img1 = img.copy()
img2 = img.copy()
img = cv2.GaussianBlur(img, (3, 3), 0)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
lines = cv2.HoughLines(edges, 1, np.pi / 180, 110)
for line in lines:
rho = line[0][0]
theta = line[0][1]
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b))
y1 = int(y0 + 1000 * (a))
x2 = int(x0 - 1000 * (-b))
y2 = int(y0 - 1000 * (a))
cv2.line(img1, (x1, y1), (x2, y2), (0, 0, 255), 2)
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 30, 500, 30)
for line in lines:
x1 = line[0][0]
y1 = line[0][1]
x2 = line[0][2]
y2 = line[0][3]
cv2.line(img2, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.imshow('houghlines3', img1)
cv2.imshow('edges', img2)
cv2.waitKey(0)
print(lines)
yline0=line[0][0]更准确的方法也有待讨论:欢迎在评论区留下您的看法。程序的核心在于算法的构思,而不在于语言和语法。有思想碰撞才能集思广益,创造出新的数学化模型,新的匹配算法。