yolov1 论文精读 - You Only Look Once
YOLOv1
Introduction
作者将目标检测进行重构并看作为单一的回归问题,直接从图像到边界框坐标和类别概率。使用我们的系统,您只需要在图像上看一次(you only look once, YOLO),以预测出现的目标和位置。
系统将输入图像分成 S×S 的网格。如果一个目标的中心落入一个网格单元中,该网格单元负责检测该目标。每个网格单元预测这些box的 B 个边界框,每个边界框包含 5 个预测:x、y、w、h 和置信度(一般用交并比)。
每个网格单元还预测 C 个条件类别概率,不管边界框的的数量 B 是多少,每个网格单元只预测的一组类别概率。
在测试时,我们乘以条件类概率和单个盒子的置信度预测值
![]()
这些分数表示该类出现在框中的概率以及预测框拟合目标的程度。
Network Design
为了在 VOC 上评估 YOLO,使用 S=7,B=2。VOC 有 20 个标注类,所以 C=20。所以最终的预测是 7×7×30(30=2*5+20) 的张量。
使用卷积层从图像中提取特征,全连接层预测输出概率和坐标。
检测网络受GoogleNet影响,有 24 个卷积层,其次是 2 个全连接层
先将ImageNet图像分辨率转为224x224,输入网络进行预训练,然后转换模型进行检测任务。
yolov1在训练时输入的图像分辨率为224×224,在预测时使用的图像为 448×448。
最后一层预测类别概率和边界框坐标。通过图像的宽高来归一化边界框的宽度和高度及x,y,使它们落在 0 和 1 之间。
我们对最后一层使用线性激活函数,所有其它层使用下面的leaky ReLU 激活函数
我们使用平方和误差是因为它很容易进行优化,但是它并不完全符合最大化平均精度的目标。
分类误差与定位误差的权重是一样的,这可能并不理想。
另外,在每张图像中,许多网格单元不包含任何对象。这将导致这些单元格的“置信度”为零,这可能导致模型不稳定。为了改善这一点,我们增加了边界框坐标预测的损失,并减少了不包含目标边界框的置信度预测的损失 。
平方和误差也可以在大box和小box中同样加权误差。我们的误差指标应该反映出,大box中 小偏差的重要性不如小box中小偏差的重要性。为了部分解决这个问题,我们直接预测边界框宽度和高度的平方根,而不是宽度和高度。
YOLO 每个网格单元预测多个边界框。在训练时,每个目标我们只需要一个边界框预测器来负责。我们根据哪个预测器的预测值与真实值之间具有当前最高的 IOU 来指定哪个预测器“负责”预测该目标。
这导致边界框预测器之间的专一化。每个预测器可以更好地预测特定大小、长宽比或目标的类别,从而改善整体召回率。
如果目标存在于该网格单元中(前面讨论的条件类别概率),则损失函数仅惩罚分类误差。如果预测器“负责”真实边界框(即该网格单元中具有最高 IOU 的预测器),则它也仅惩罚边界框坐标误差
为了避免过度拟合,我们使用 dropout 和大量的数据增强。
Inference
与训练时一样,预测测试图像的检测只需要一次网络评估。在VOC 上,每张图像上网络预测 98 个边界框(图像被划分成 7*7 的格子,每个格子预测两个边界框,总共 98 个边界框)和每个框的类别概率。YOLO 在测试时非常快,因为它只需要运行一次网络评估.
网格强化了边界框预测中的空间多样性。然而,一些大的目标或靠近多个网格单元边界的目标可以被多个网格单元很好地定位。非极大值抑制(NMS)可以用来修正这些多重检测。
在得到推理结果后,如何获取我们真正想要的信息呢?
yolo后处理就是模型的输出进行处理,得到我们想要的坐标框的 x y w h xywh xywh以及 c o n f i d e n c e confidence confidence

学习笔记
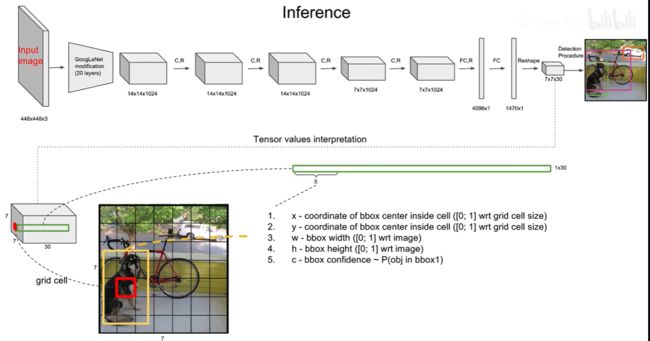
这是yolov1的模型,他将图像划分成了7x7个网格,每个网格负责预测两个边界框,每个边界框都有5个信息$x、y、w、h、confidence $ ,(这个confidence是该区域有目标框的概率),共预测20个类,每个类都有一个置信度信息(这个confidence是这个框是猫是狗的概率),所以最终输出为 7 ∗ 7 ∗ 30 7*7*30 7∗7∗30
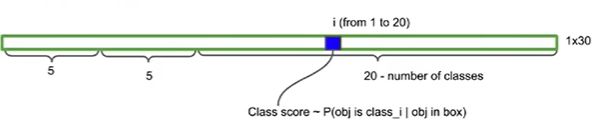
然后每个边界框的confidence 乘以所有类别的confidence就是边界框的全概率
这样每个grid cell都能有两个20维向量,一共49个grid cell,所以共有98个向量
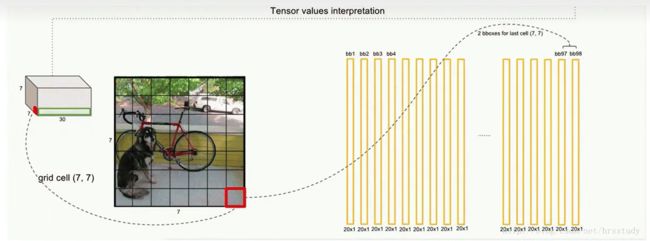
这些向量就组成如下的很多边界框

下一步就是筛选出真正的边界框
第一步:这张图片上并不是有20个类的,所以先有个阈值将大于这个阈值的类别筛选出来,比如筛选出了dog、bicycle、car
然后分别对这三个类处理,比如先对dog,从dog类的所有96个置信度进行从大到小排个序,设置一个阈值,confidence小于这个阈值的就被舍去了。
但确实还有真正包含某个物体的多个框,比如下面四个bbox的置信度都比较大,那怎么从这多个框中选择最合适的呢?
下面就是非极大抑制NMS
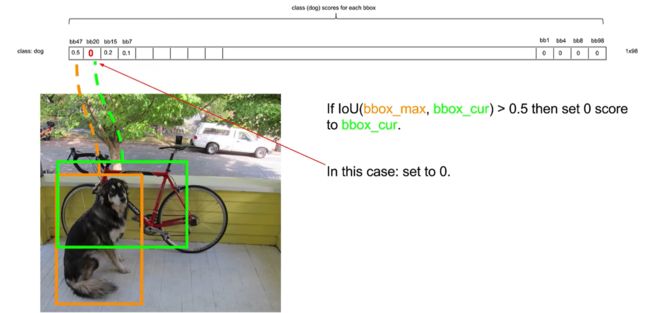
应该先将置信度最大的拿出来,然后后面的每一个都与第一个最大的作比较,如果IOU大于某个阈值,则认为两个识别了同一个物体,则把低置信度的那个抑制掉。比如bbox20和bbox47重合度较大,所以认为两个是同一物体。
如果IOU小于这个阈值,就说明两个框不是识别的同一个物体,保留。bb15和bb7与bb47的重合度较小,所以认为两个box不是同一个物体。

然后选取剩下的第二大置信度作为基box,其他框再与这个框比较,比如bb7和bb15重合度较大,认为这两个box内是同一个物体。
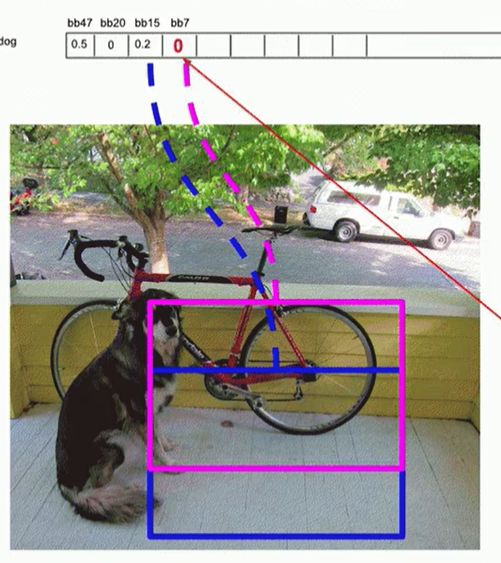
合适的阈值下可能只留下一个框,当然某些阈值下可能会保留更多的框,阈值的设置应该是根据目标任务设置的,越高的阈值(越不容易置零,即越宽容)会检测出越多的目标。
对其他类别也是同样操作,就得到了所有的目标框。
当然注意,在训练阶段是不需要剔除框的,所有框对我们反向传播参数更新都是有用的,只是在推理阶段需要这样做。
how to train
每个grid cell 预测两个bbox,但只负责预测一个物体,也就是整张图片最多预测49个物体,这也就是为什么yolov1对密集小目标检测效果不好的原因。

LOSS


yolov1的损失函数分为三部分
- 第一部分是负责检测物体的bbox中心点定位误差以及宽高误差
- 第二部分是负责检测物体的bbox的confidence误差和不负责检测物体的bbox的confidence误差
- 第三部分是负责检测物体grid cell分类误差
Limitations
-
YOLO 对边界框预测强加空间约束,因为每个网格单元只预测两个框,只能有一个类别。这样就限制了模型可预测的邻近目标的数量。因此对物体较为密集的场景预测效果较差。
-
模型学习从数据中预测边界框,因此它很难泛化到新的、不常见的长宽比或配置中的目标。
后面是模型比较,yolov1和其他模型比有什么优缺点就不说了