【深度学习】打破ViT SOTA垄断!SegNeXt:卷积注意力机制重夺语义分割的胜利高地(NeurIPS 22)...
作者丨happy 编辑丨极市平台
导读
本文对已有成功分割方案进行了重审视并发现了几个有助于性能提升的关键成分,作者们设计了一种新型的卷积注意力架构方案SegNeXt。在多个主流语义分割数据集上,SegNeXt大幅改善了其性能。在Pascal VOC2012测试集上,SegNeXt凭借仅需EfficientNet-L2+NAS-FPN的十分之一参数量取得了90.6%mIoU指标。

NeurIPS2022:https://github.com/Visual-Attention-Network/SegNeXt/blob/main/resources/paper.pdf
code:https://github.com/Visual-Attention-Network/SegNeXt
arxiv:https://arxiv.org/abs/2209.08575
Vision Transformer的"降维打击"导致多个CV领域SOTA方案均被ViT方案主导,语义分割同样不例外。本文对已有成功分割方案进行了重审视并发现了几个有助于性能提升的关键成分,进而促使我们设计了一种新型的卷积注意力架构方案SegNeXt。在多个主流语义分割数据集上,SegNeXt大幅改善了其性能。比如,在Pascal VOC2012测试集上,SegNeXt凭借仅需EfficientNet-L2+NAS-FPN的十分之一参数量取得了90.6%mIoU指标。平均来讲,在ADE20K数据集上,SegNeXt比其他SOTA方案平均提高2.0%mIoU,且计算量相当或更少。
本文出发点

本文对语义分割领域代表性方案(DeepLabV3+, HRNet, SETR, SegFormer)进行重审视,总结出成功的语义分割方案应具有的几点关键属性(可参考上表):
采用强骨干网络作为编码器;
多尺度信息交互;
空域注意力;
低计算复杂度。
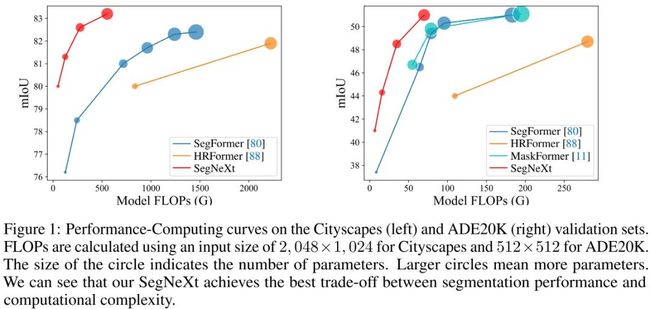
基于上述考量,本文对卷积注意力设计进行了重思考并提出了一种简单而有效的编码器-解码器架构SegNeXt。不同于已有Transformer方案,SegNeXt对Transformer-Convolution Encoder-Decoder架构进行了逆转,即对编码器模块采用传统卷积模块设计但引入了多尺度卷积注意力,对解码器模块采用了Hamberger(自注意力的一种替代方案)进一步提取全局上下文信息。因此,SegNeXt能够从局部到全局提取多尺度上下文信息,能在空域与通道维度达成自适应性,能从底层到高层进行信息聚合。上图给出了Cityscape与ADE20K数据集上所提方案与标杆方案的计算量与性能对比。
本文方案
接下来,我们将对SegNeXt所用到的定制化骨干网络(其实就是扩展版VAN)与Decoder部分进行介绍。
Convolutional Encoder
延续已有方案,本文在Encoder部分同样采用了金字塔架构,每个构成模块采用了类似ViT的结构,但不同之处在于:本文并未使用自注意力,而是设计一种多尺度卷积注意力模块MSCA(见下图,其实就是一种多尺度版VAN)。

如上图所示,MSCA由三部分构成:
depth-wise 卷积:用于聚合局部信息
多分支depth-wise卷积:用于捕获多尺度上下文信息
卷积:用于在通道维度进行相关性建模
其中,卷积的输出将作为注意力权值对MSCA的输入进行重加权。MSCA可以描述为如下公式:
在实现方面,多分支depth-wise方面,作者采用两个depth-wise strip卷积近似标准depth-wise卷积。这样做有两个好处:
strip卷积更轻量,可以进一步降低计算量;
对于类strip目标(如行人、电线杆),strip卷积可以作为标准卷积的互补提取类strip卷积。

上表给出了通过堆叠MSCA而得到的不同MSCAN骨干信息以及SegNeXt架构信息。此外,主要注意的是:MSCAN的每个模块采用的是BN,而非LN。关于MSCA的实现code参考如下。
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * uDecoder
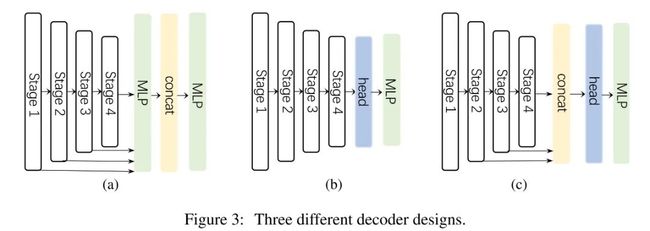
常规语义分割模型的骨干往往在ImageNet上预训练得到,为捕获高级语义信息,通常需要一个Decoder模块。本文则对上述三种简单Decoder架构进行了探索:
Figure3-a,源自SegFormer的解码器,它是一种纯MLP架构;
Figure3-b,常被CNN方案使用,如ASPP、PSP、DANet等;
Figure3-c,本文采用的解码器,它采用轻量型Hamberger模块对后三个阶段的特性进行聚合以进行全局上下文建模。
需要注意的是,SegFormer的解码器对Stage1到Stage4的特征进行聚合,而本文方案则仅对Stage2-Stage4的特征进行聚合。这是因为:
SegNeXt的Encoder采用了卷积架构,使得Stage1部分特征包含过多底层信息,进而导致其会影响语义分割性能。
对Stage1部分特征进行处理会带来过多的计算负载。
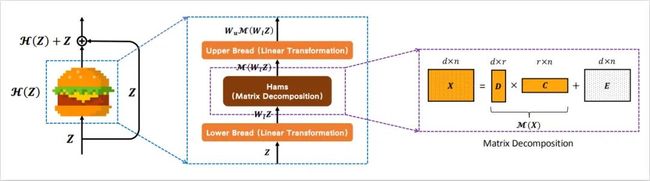
上图为Hamberger的架构示意图,它采用矩阵分解方式进行全局空域信息建模。关于Hamberger的介绍,作者在文中并未进行描述,该部分内容源自作者被ICLR2021接收的文章《Is Attention Better Than Matrix Decomposition》,关于该部分的介绍查阅作者的详细解读:
Enjoy Hamburger:注意力机制比矩阵分解更好吗?(I),知乎链接:https://zhuanlan.zhihu.com/p/369769485
Enjoy Hamburger:注意力机制比矩阵分解更好吗?(II),知乎链接:https://zhuanlan.zhihu.com/p/369855045
Enjoy Hamburger:注意力机制比矩阵分解更好吗?(III),知乎链接:https://zhuanlan.zhihu.com/p/370410446
话说作者的理论功底是真的强!强烈建议各位同学跟随作者的思路去领略一下Hamberger背后的故事。从github上的介绍来看该文在3月份就已初步完成,不过当时是采用的是VAN+Hamberger组合,而本文则是MSCAN+Hamberger的组合。当然,MSCAN是VAN的多尺度版。
本文实验
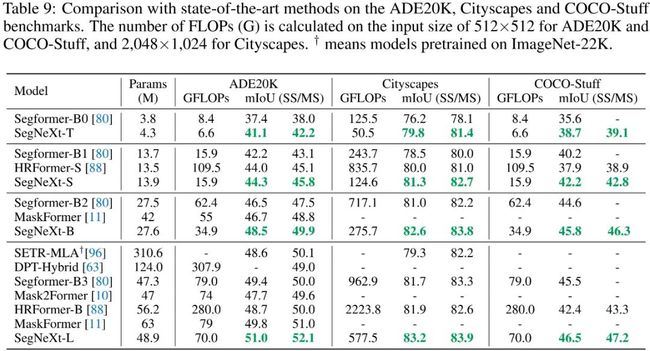

上述图表给出了不同数据集上不同语义分割方案的性能对比,从中可以看到:
在ADE20K数据集上,相比Mask2Former+Swin-T,SegNeXt-L以3.3mIoU指标胜出,且参数量与计算量相当;相比SegFormer-B2,SegNeXt-B以2.0mIoU指标胜出,且仅需56%计算量。
在Cityscape数据集上,相比SegFormer-B2,SegNeXt-B以1.6mIoU指标胜出,且仅需40%参数量。
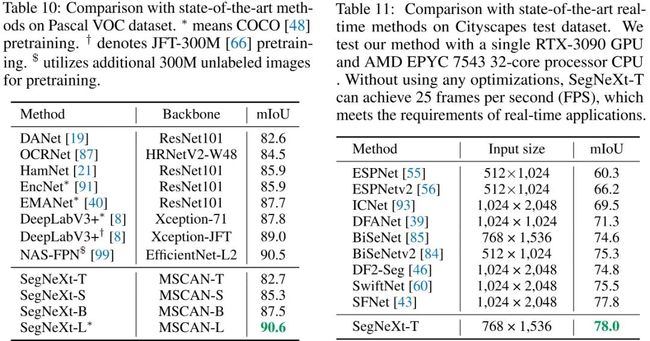
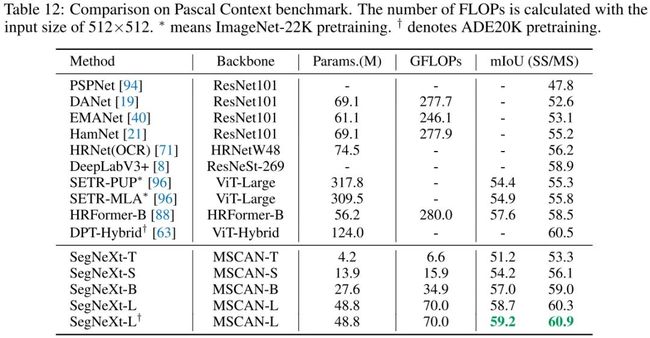
更多实验结果可参考如上三个表,总而言之,SegNeXt在语义分割任务上取得了新的SOTA结果。值得一提的是,在Cityscape测试集+实时分割方面,所提方案达成了新的SOTA指标78.0mIoU@25fps(3090 RTX GPU)。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码