机器学习:PM2.5预测问题 (基于Sklearn Pandas)
问题描述
背景:
虽然细颗粒物只是地球大气成分中含量很少的组分,但它对空气质量和能见度等有重要的影响。与较粗的大气颗粒物相比,细颗粒物粒径小,富含大量的有毒、有害物质且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大。研究表明,颗粒越小对人体健康的危害越大。细颗粒物能飘到较远的地方,因此影响范围较大。
细颗粒物对人体健康的危害要更大,因为直径越小,进入呼吸道的部位越深。10μm直径的颗粒物通常沉积在上呼吸道,2μm以下的可深入到细支气管和肺泡。细颗粒物进入人体到肺泡后,直接影响肺的通气功能,使机体容易处在缺氧状态。
已经有大量流行病学证据表明,PM2.5有急性与慢性健康效应。急性健康效应体现在高PM2.5暴露增加患急性呼吸道疾病与心脑血管疾病的风险,慢性毒性体现在PM2.5可能诱发肺癌、COPD(慢性阻塞型肺炎)、心脑血管疾病等慢性疾病,也有研究表明对细颗粒物的暴露会影响人的免疫系统、神经系统等。
问题:
PM2.5粒径小,富含大量的有毒、有害物质且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大。所以如果能做到对PM2.5实时且准确的预测,那么就可以为人们的日常出行提供一些注意事项,该不该出门?出门应该准备什么?
有关数据
收集数据及数据来源
在机器学习平台Kaggle上下载中国2010-2015年五大城市的PM2.5数据集
样本名称
成都市草堂寺2010年1月1日至2015年12月31日的PM2.5的记录值
确定样本属性,所有属性名称以及每个属性取值范围
-
样本属性有:
- PM2.5平均值标准值:对于数据表中的PM_Caotangsi
- 季节:对于数据表中的season
- 露点(摄氏温度):对于数据表中的DEWP
- 温度(摄氏温度):对于数据表中的TEMP
- 湿度(%):对于数据表中的HUMI
- 压力(hPa):对于数据表中的PRES
- 组合风向:对于数据表中的cbwd
- 累积风速(m / s):对于数据表中的Iws
-
对于PM2.5的值有如下:
空气质量等级 24小时PM2.5平均值标准值 值转换 优 0~35 1 良 35~75 2 轻度污染 75~115 3 中度污染 115~150 4 重度污染 150~250 5 严重污染 大于250及以上 6 -
对于组合风向的值有如下:
风向 值转换 cv 1 NE 2 NW 3 SE 4 SW 5 -
对于季节:
取值范围1,2,3,4
-
对于露点:
取值范围[-16,28]
-
对于温度(摄氏温度):
取值范围[-2,38]
-
对于湿度(%):
取值范围[12.78,100]
-
对于压力(hPa):
取值范围[991,1041]
-
对于累积风速(m / s):
取值范围[0,93]
样本数量
原始样本数量52583个,经处理去掉无效值共有21074 个
样本标记名称以及取值范围;
样本标记为PM2.5的值所代表的的等级对应转换的值,如下表:
| 空气质量等级 | 24小时PM2.5平均值标准值 | 值转换 |
|---|---|---|
| 优 | 0~35 | 1 |
| 良 | 35~75 | 2 |
| 轻度污染 | 75~115 | 3 |
| 中度污染 | 115~150 | 4 |
| 重度污染 | 150~250 | 5 |
| 严重污染 | 大于250及以上 | 6 |
数据处理
-
对原始数据进行处理
在csv表格中将PM2.5及组合风向的值进行转换
-
获取数据进行处理
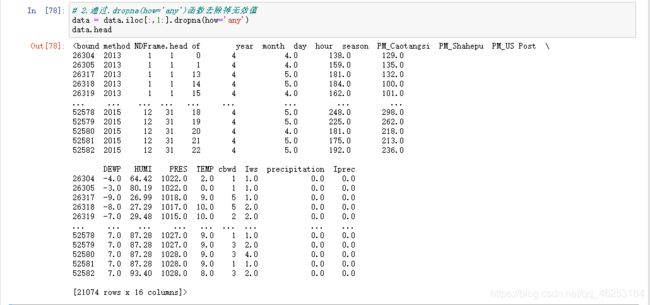
# 1.从ChengduPM20100101_20151231.csv中读取训练数据 data = pd.read_csv('./ChengduPM20100101_20151231.csv') # 2.通过.dropna(how='any')函数去除掉无效值 data = data.iloc[:,1:].dropna(how='any') # 3.获取样本属性值 并转换为NumPy数组 season = data['season'] data1 = data.iloc[:,8:14] data1['season'] = season data1 = data1.to_numpy() # 4.获取样本标记值 并转换为NumPy数组 PM_Caotangsi = data['PM_Caotangsi'] PM_Caotangsi = PM_Caotangsi.to_numpy() # 5.通过train_test_split()划分训练集测试集 X_train, X_test, y_train, y_test = train_test_split(data1, PM_Caotangsi, test_size=0.12, random_state=12)
设计模型,训练模型
第一个决策树分类
最初模型
# 导入必要的模块
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 数据处理
# 1.从ChengduPM20100101_20151231.csv中读取训练数据
data = pd.read_csv('./ChengduPM20100101_20151231.csv')
# 2.通过.dropna(how='any')函数去除掉无效值
data = data.iloc[:,1:].dropna(how='any')
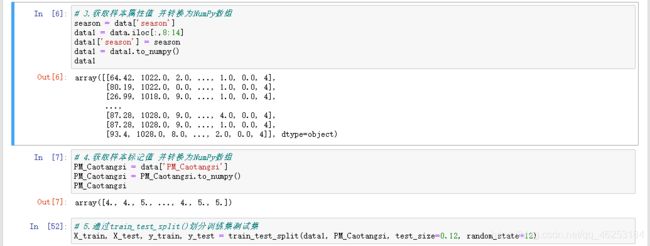
# 3.获取样本属性值 并转换为NumPy数组
season = data['season']
data1 = data.iloc[:,8:14]
data1['season'] = season
data1 = data1.to_numpy()
# 4.获取样本标记值 并转换为NumPy数组
PM_Caotangsi = data['PM_Caotangsi']
PM_Caotangsi = PM_Caotangsi.to_numpy()
# 5.通过train_test_split()划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(data1, PM_Caotangsi, test_size=0.12, random_state=12)
# 建立模型
clf = DecisionTreeClassifier(criterion='entropy')
# 训练模型
clf.fit(X_train,y_train)
# 评分
clf.score(X_test,y_test)
Out[50]: 0.4638196915776987
修改模型
# 获取原始模型决策树深度
d=clf.get_depth()
# 建立新模型 最大深度和原始深度d一样 最小叶节点为d-14
model= DecisionTreeClassifier(criterion='entropy',max_depth=d,min_samples_leaf=d-14)
# 训练模型
model.fit(X_train,y_train)
# 评分
model.score(X_test,y_test)
Out[56]: 0.4693554764729142
第二个集成方法-极限随机树
关于集成方法
集成方法 的目标是把多个使用给定学习算法构建的基估计器的预测结果结合起来,从而获得比单个估计器更好的泛化能力/鲁棒性。
集成方法通常分为两种:
- 平均方法,该方法的原理是构建多个独立的估计器,然后取它们的预测结果的平均。一般来说组合之后的估计器是会比单个估计器要好的,因为它的方差减小了。
- 相比之下,在 boosting 方法 中,基估计器是依次构建的,并且每一个基估计器都尝试去减少组合估计器的偏差。这种方法主要目的是为了结合多个弱模型,使集成的模型更加强大。
关于极限随机树
在极限随机树中, 计算分割点方法中的随机性进一步增强。 在随机森林中,使用的特征是候选特征的随机子集;不同于寻找最具有区分度的阈值, 这里的阈值是针对每个候选特征随机生成的,并且选择这些随机生成的阈值中的最佳者作为分割规则。 这种做法通常能够减少一点模型的方差,代价则是略微地增大偏差。
实验代码
# 导入必要的模块
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesClassifier
# 数据处理
# 1.从ChengduPM20100101_20151231.csv中读取训练数据
data = pd.read_csv('./ChengduPM20100101_20151231.csv')
# 2.通过.dropna(how='any')函数去除掉无效值
data = data.iloc[:,1:].dropna(how='any')
# 3.获取样本属性值 并转换为NumPy数组
season = data['season']
data1 = data.iloc[:,8:14]
data1['season'] = season
data1 = data1.to_numpy()
# 4.获取样本标记值 并转换为NumPy数组
PM_Caotangsi = data['PM_Caotangsi']
PM_Caotangsi = PM_Caotangsi.to_numpy()
# 5.通过train_test_split()划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(data1, PM_Caotangsi, test_size=0.12, random_state=12)
# 建立模型
etc = ExtraTreesClassifier(n_estimators=10, max_depth=None,min_samples_split=25, random_state=10)
# 训练模型
etc.fit(X_train,y_train)
# 评分
etc.score(X_test,y_test)
Out[58]: 0.5120601028074337
实验结果
结果截图
数据处理
实验结果
决策树

修改后决策树

极限随机树

根据实验结果
同过比较决策树的最大评估结果0.4693554764729142和极限随机树最大评估结果0.5120601028074337
可以得知极限随机树的评估效果较决策树要好一些
根据文献记载
随机森林算法
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。是一个包含多个决策树的分类器,并且其输出类别是由个别树输出的类别的众数决定的。随机森林的每一颗决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一颗决策树分别进行判断,看看这个样本属于哪一类,然后看看哪一类被选择最多,则预测这个样本为那一类。一般来说,随机森林的判决性能优于决策树。
综合结果
根据实验结果和文献记载,使用随机森林(极限随机树)算法作为解决方案的效果要优于决策树算法作为解决方案,因此使用极限随机树算法作为解决方案。
总结
利用决策树和极限随机树去解决通过季节,露点,温度,湿度,压力,组合风向,累积风速来预测PM2.5标准值进而获得空气等级来判定如何出行的问题,通过实验,极限随机树较决策树评估效果要好一些,但是最高评估效果仅有51.2%,还是不能达到准确的评估PM2.5的标准值。在算法方面或许可以换其他的方法来提高评估值,数据方面可以用个更多的数据来训练或者对数据的值进行一些处理来提高评估值。
参考文献
- 关于PM2.5的十个问题 . 北京大学环境科学与工程学院 . [2017-1-3]
- 环境空气质量标准(GB 3095—2012).中华人民共和国环境生态部.[2016-01-01]
- 集成方法.Scikit-Learn (Sklearn) 官方文档中文版
- 决策树和随机森林算法.CSDN-TravisZeng的文章
- 十分钟入门Pandas.Pandas中文网