物联网面试必过要点
要是能熟记以下知识点,再加上自身的项目经验,过个面试,问题不大。
指针定义
一个指向指针的的指针,它指向的指针是指向一个整型数 int **a; 一个有10个指针的数组,该指针是指向一个整型数的 int *a[10]; 一个指向有10个整型数数组的指针 int (*a)[10] 一个指向函数的指针,函数指针,该函数有一个整型参数并返回一个整型数 int (*a)( int ){} 一个返回指针类型的函数。 int* a(int){} 一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数 int (* a[10])( int ) //类似这种定义应该采用分解法来做。 先定义单个函数指针 int (*a)(int),然后再是有10个指针的数组 int (*a[10])(int)
关键字static的作用是什么?
1)在函数体内,一个被声明为静态的变量在这一函数被调用过程中维持其值不变(该变量存放在静态变量区)。
2) 在模块内(但在函数体外),一个被声明为静态的变量可以被模块内所用函数访问,但不能被模块外其它函数访问。它是一个本地的全局变量。
3) 在模块内,一个被声明为静态的函数只可被这一模块内的其它函数调用。那就是,这个函数被限制在声明它的模块的本地范围内使用
关键字const
const int a; 常量a int const a; 常量a const int *a; 指针指向的内容不可以被修改 但是指针指向的地址可以修改。 int * const a; 指针指向的地方不可以被改,但是指向的地址的内容可以修改。 int const * const a; 指针指向地址的内容和指针指向的地址都不可以修改。
第一个设置a的bit 3,第二个清除a 的bit 3
a |= 1 << 3 a &= ~(1 << 3) 或BIC a,a,#0x3
有符号数与无符号数,下面的代码输出是什么,为什么?
void foo(void) { unsigned int a = 6; int b = -20; (a+b > 6)?puts("> 6") : puts("<= 6"); }大于6. 有符号数转换为无符号数。
无符号数:不存在正负之分,所有位都用来表示数的本身。
有符号数:最高位用来表示数的正负,最高位为1则表示负数,最高位为0则表示正数。
1. 无符号数转换为有符号数:看无符号数的最高位是否为1,如果不为1(即为0),则有符号数就直接等于无符号数;
2.如果无符号数的最高位为1,则将无符号数取补码,得到的数就是有符号数。
3..有符号数转换为无符号数 :看有符号数的最高位是否为1,如果不为1(即为0),则无符号数就直接等于有符号数;
4.如果有符号数的最高位为1,则将有符号数取补码,得到的数就是无符号数
所以6 - 20 = -14,因为结果作为一个无符号数已经溢出了,所以又加了65536结果变成一个正数了,为65522
-5对应正数5(00000101)→所有位取反(11111010)→加1(11111011)
\0问题
void test1() { char string[10]; char* str1 = "0123456789"; strcpy( string, str1 ); } //溢出 还有\0 void test2() { char string[10], str1[10]; int i; for(i=0; i<10; i++) { str1[i] = 'a'; } strcpy( string, str1 ); } str1没有\0结束符,程序崩溃。 void test3(char* str1) { char string[10]; if( strlen( str1 ) <= 10 ) { strcpy( string, str1 ); } }改为strlen( str1 ) < 10 这种方式不会报错,但是会造成隐藏的严重bug, 会修改内存里面的数据。
请计算sizeof的值和strlen的值。
void func ( char *str ) { sizeof( str ) = ? } char str[10] = “hello”; strlen(str); 4和5
宏定义问题
#include "stdafx.h" #define SQR(X) X*X int main(int argc, char* argv[]) { int a = 10; int k = 2; int m = 1; a /= SQR(k+m)/SQR(k+m); printf("%d\n",a); return 0; } a =a/ (k+m*k+m/k+m*k+m) 宏定义A,B中取较大值 #define compare(a,b) ((a > b) ? (a) : (b))
用C写个程序,如何判断一个操作系统是16 位还是32 位的?不能用sizeof()函数。
int a = 32767; if( (a + 1) > 0 ) { cout<<"32 bit"<16位的int范围为-32768 ~ 32767
在不用第三方参数的情况下,交换两个参数的值.
a=a+b; b=a-b; a=a-b; 或者 a = a^b; b = a^b; a= a^b;
指针操作
unsigned short array[]={1,2,3,4,5,6,7}; int i = 3; *(array + i) = ? 结果是4。 main() { int a[5]={1,2,3,4,5}; int *ptr=(int *)(&a+1);// (&a+1)指向下一个一维数组 printf("%d,%d",*(a+1),*(ptr-1)); }解:
int *ptr=(int *)(&a+1);&a表示取得数组a存储区域的首地址,再加1表示数组a存储区域的后的地址,这就使得ptr指针指向数组的最后一个元素后面的那个存储单元的地址,
而ptr减1后,再进行数据访问,则访问的是ptr指针的前一个存储单元的值,所有最后的答案是2,5
(int *)(&a+1) 强制转化指针类型。
#include
和 #include “filename.h” 有什么区别?
<>会直接去系统遍历
""会首先在当前项目遍历头文件,如果不存在才去系统遍历。
<>的可以改成"",但是""一定不能改成<>
不能做switch()的参数类型是:
只有整数可以做参数
局部变量能否和全局变量重名。
可以重名。 局部变量名会覆盖全局变量名。 C++中可以使用作用域来区分。
全局变量可不可以定义在可被多个.C文件包含的头文件中?为什么?
不可以!但是可以声明。 这里涉及到强符号和弱符号的问题,具体的可以参考下面的blog。
在C语言中,函数和初始化的全局变量(包括初始化为0)是强符号,未初始化的全局变量是弱符号。
对于它们,下列三条规则使用:
① 同名的强符号只能有一个,否则编译器报"重复定义"错误。
② 允许一个强符号和多个弱符号,但定义会选择强符号的。
③ 当有多个弱符号相同时,链接器选择占用内存空间最大的那个。
一语句实现x是否为2的若干次幂的判断。
if ( x & ( x - 1 ) == 0 )
printf("是2的幂");
else printf("不是2的幂");
pow(x,y),计算x的y次幂
sqrt(x),求浮点数x的平方根
fabs(x),求浮点数x的绝对值
char* s="AAA"; printf("%s",s); s[0]='B'; printf("%s",s); 有什么错?常量区 不允许修改内容,结果不变。AAA
#define MAX 256 int main() { unsigned char A[MAX],i; for (i=0;ichar是一字节,八位,最大可以表示的整数是255,所以这里死循环了
struct name1 { char str; short x; int num; } struct name2 { char str; int num; short x; } typedef struct { int a; char b[3]; short d; int c; } node; sizeof(struct name1)=8 sizeof(struct name2)=12 sizeof(node) = 16 union test { int a; int b[5]; double c; } struct test1 { int a; test b; double c; } sizeof(test1) = 32;字节对齐
int main() { char a; char *str=&a; strcpy(str,"hello"); printf(str); return 0; }没有为a分配内存,并且a是一个字符变量。 内存越界。
地址和变量大小操作
unsigned char *p1; unsigned long *p2; p1=(unsigned char *)0x801000; p2=(unsigned long *)0x810000;请问p1+5= 0x801005; p2+5= 0x810014;
输出结果p1+5的值是801005,因为指针变量指向的值字符,加一表示指针向后移动一个字节,那么加5代表向后移动5个字节,所以输入801005
p5+5的值是801014,因为指针变量指向的长整形的,加一表示指针向后移动4个字节,那么加5代表向后移动20个字节,所以输入810014,(输出时十六进制)要是十进制就是810020了
有数组定义int a[2][2]={{1},{2,3}};则a[0][1]的值为0。 // 对
int (*ptr) (),则ptr 是一维数组的名字。 // 函数指针
指针在任何情况下都可进行>, <,>=, <=,==运算。 //不明所以
switch(c) 语句中c 可以是int ,long,char ,float ,unsigned int 类型。 //错。 只能是整数,float排除。
不使用库函数,编写函数int strcmp(char *source, char *dest) 相等返回0,不等返回-1;
写一函数int fun(char *p)判断一字符串是否为回文,是返回1,不是返回0,出错返回-1
静态变量操作
#includeint sum(int a) { int c=0; static int b = 3;//静态 c+=1; b+=2; return(a+b+c); } int main() { int I; int a=2; for(I=0;I <5;I++) { printf("%d,", sum(a)); } return 0; } 8,10,12,14,16,
一定能打印出”hello”的是134,有错误的是2
char *GetHellostr(void); int main(void) { char *ps; ps= GetHellostr( ); if(ps != NULL) { printf(ps); } return 0; } (1) char *GetHellostr(void) { char *ps=“hello”; return ps; } (2) char *GetHellostr(void) { char a[]=“hello”; return (char *)a; 内存已经被释放了 } (3) char *GetHellostr(void) { static char a[]=“hello”; return (char *)a; } (4) char *GetHellostr(void) { char *ps; ps = malloc(10); if(NULL ==ps) return NULL; strcpy(ps,”hello”); return ps; }
字符串函数
char* strcpy(char* strDest,const char* strSrc) { assert(strDest!=NULL && strSrc!=NULL); char* strTmp = strDest; while(*strSrc!='\0') { *strDest++ = *strSrc++; } strDest = '\0'; return strTmp; } int strlen(const char*strSrc) { assert(strSrc!= NULL); int len = 0; while((*strSrc++) != '\0') ++len; return len; } char* strcat(char* strDest,const char* strSrc) { assert((strDest != NULL) && (strSrc != NULL)); char* strTmp = strDest; while(*strDest != '\0') ++strDest; while(*strDest++ = *strSrc++); *strDest++ = '\0'; return strDest; }
二级指针和指针的引用
void foo(char **p)//双指针 { *p = "after"; } int main() { int *p = "befor"; foo(&p); cout << p << endl;//输出的为after return 0; } void foo(char *&p)//指针的引用 { p = "after"; } int main() { int *p = "befor"; foo(p); cout << p << endl;//输出的为after return 0; }
使用汇编语言的原因:
第一:汇编语言执行速率要高于c语言。
第二:启动代码,编写bootloader和内核使用时,主要对cpu和内存进行初始化时使用。因为这个时候还能没有c语言编写的环境(堆栈还没建立),所以不能用c语言。
#ifndef X
#define X
...
#endif
防止头文件被重复包含和编译。
指针与数组的区别。
第1个存储方式的不同数组是存储的成员内容的本身。而指针存储的是首地址。
第2个是运算方式的不同。数组名是一个常量不能进行自增自减的运算,而指针是一个变量,可以进行自增自减的运算。
第3个是赋值运算的操作。数组可以进行初始化操作,但不能通过赋值语句进行整体的赋值,而指针能指向另一条语句。链表和数组的区别:
数组静态分配内存,链表动态分配内存。
数组在内存中是连续的,链表是不连续的。
数组利用下标定位,查找的时间复杂度是O(1),链表通过遍历定位元素,查找的时间复杂度是O(N)。
数组插入和删除需要移动其他元素,时间复杂度是O(N),链表的插入或删除不需要移动其他元素,时间复杂度是O(1)。
strcpy 为什么要返回char*
strcpy函数返回的值可以作另一个函数的实参,实现链式操作。
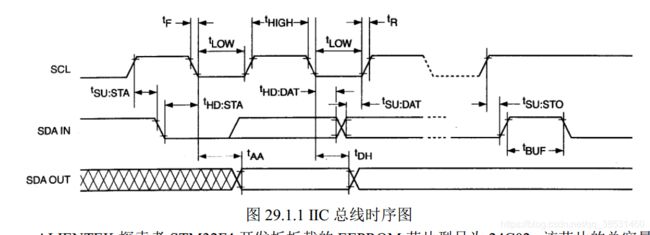
IIC介绍:
开始信号: SCL 为高电平时, SDA 由高电平向低电平跳变,开始传送数据。
结束信号: SCL 为高电平时, SDA 由低电平向高电平跳变,结束传送数据。
应答信号:接收数据的 IC 在接收到 8bit 数据后,向发送数据的 IC 发出特定的低电平脉冲,
表示已收到数据。 CPU 向受控单元发出一个信号后,等待受控单元发出一个应答信号, CPU 接
收到应答信号后,根据实际情况作出是否继续传递信号的判断。若未收到应答信号,由判断为
受控单元出现故障。//IIC 发送一个字节 //返回从机有无应答 //1,有应答 //0,无应答 void IIC_Send_Byte(u8 txd) { u8 t; SDA_OUT(); IIC_SCL=0;//拉低时钟开始数据传输 for(t=0;t<8;t++) { IIC_SDA=(txd&0x80)>>7; txd<<=1; delay_us(2); //对 TEA5767 这三个延时都是必须的 IIC_SCL=1;delay_us(2); IIC_SCL=0; delay_us(2); } } //读 1 个字节, ack=1 时,发送 ACK, ack=0,发送 nACK u8 IIC_Read_Byte(unsigned char ack) { unsigned char i,receive=0; SDA_IN();//SDA 设置为输入 for(i=0;i<8;i++ ) { IIC_SCL=0; delay_us(2); IIC_SCL=1; receive<<=1; if(READ_SDA)receive++; delay_us(1); } if (!ack) IIC_NAck();//发送 nACK else IIC_Ack(); //发送 ACK return receive; }
AES加密:
AES加密过程中最后16字节的处理,128位加密:
当原文大小不是16字节的整数倍时,AES加密会进行填补,缺几个,填几个
当原文大小刚好是16的倍数的时候为了区别明文和密文,AES会在明文的后面补充16字节的16。
当密文解密到最后的16字节的数据的时候发现最后一个字节的数据为16,则舍弃这一串16字节的数据,若小于16则表示进行了填充,舍弃填充的部分。
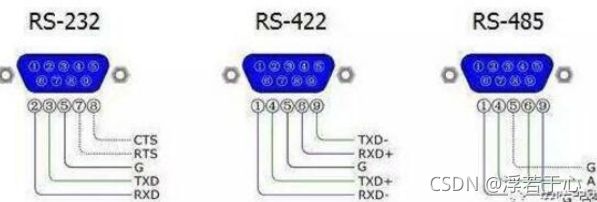
RS232和RS485h和RS422的特性和区别:
RS232特点:
(1)接口的信号电平值较高, 易损坏接口电路的芯片。RS232电压为负逻辑关系。即:逻辑"1"为-3~-15V;逻辑"0':+3~+15V,噪声容限为2V。即要求接收器能识别高于+3V的信号作为逻辑“0”,低于-3V的信号作为逻辑"1”,TTL电平为5V为逻辑正,0为逻辑负。与TTL电平不兼容故需使用电平转换电路方能与TTL电路连接。
(2)传输速率较低,在异步传输时,比特率为20Kbps;
(3)接口使用一根信号线和一根信号返回线而构成共地的传输形式,这种共地传输容易产生共模干扰,所以抗噪声干扰性弱。
(4)传输距离有限,最大传输距离标准值为15米
RS485特点:
(1)RS-485的电气特性:逻辑“1”以两线间的电压差+2V~+6V表示,逻辑“0"以两线间的电压差-6V~-2V表示。接口信号电平比RS-232-C降低了, 就不容易损坏接口电路芯片, 且该电平与TTL电平兼容, 刻方便与TTL电路连接。
(2) 数据最高传输速率为:10Mbps
(3)RS-485接口采用平衡驱动器和差分接收器的组合,抗共模干扰能力强,即抗噪声性能好。
(4)RS-485接口的最大传输距离实际上可达3000米。
(5)RS-232-C接口在总线上只允许连接一个收发器,即单站能力;而RS-485接口在总线上只允许连接多达128个收发器,即具有多站能力,这样用户可以利用单一的RS-485接口方便地建立设备网络。
RS-422和RS-485电路原理基本相同,都是以差动方式发送和接受
RS-422通过两对双绞线可以全双工工作收发互不影响,而RS485只能半双工工作,发收不能同时进行,但它只需要一对双绞线。RS 422和RS 485在19kpbs下能传输1200米。用新型收发器线路上可连接台设备。RS-422的电气性能与RS-485完全一样。主要的区别在于:RS-422有4根信号线:两根发送(Y、Z)、两根接收(A、B)。由于RS-422的收与发是分开的所以可以同时收和发(全双工);RS-485有2根信号线:发送和接收。
RS232是全双工的,RS485是半双工的,RS422是全双工的。
232一对一通信,485允许连接128个收发器
232单端传送方式,485差分信号
编译器编译:
编译器的执行过程:编译、汇编、链接
编译分为6个阶段:
词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成,后面的4,5可以不需要。
内存区域划分:
全局变量-》静态区,局部变量-》栈,动态生成-》堆
栈和堆的主要区别:
空间的申请和释放,堆需要人为的进行,栈是自动的
堆的空间是不连续的,栈的空间是连续的
堆的空间比较大,但申请和应用导致使用起来比较慢
栈区空间是向下增长,堆区是向上增长

快速排序:
时间复杂度为nlgn
void fast(int *data, int begin, int end) { int base = 0, i = 0, j = 0; if(begin < end) { base = data[begin]; i = begin; j = end; while(i < j) { while(i < j && base < data[j]) { j--; } data[i] = data[j]; while(i < j && base >= data[i]) { i++; } data[j] = data[i]; } data[i] = base; fast(data,begin,i - 1); fast(data,i + 1,end); } else { return; } }
二分查找法:
int search(int *data, int key, int begin, int end) { int middle = (end - begin) / 2 + begin; if(begin > end) { return -1; } if(data[middle] == key) { return middle + 1; } else if(data[middle] > key) { end = middle - 1; return search(data,key,begin,end); } else if(data[middle] < key) { begin = middle + 1; return search(data,key,begin,end); } }
大小端:
大端格式:
高字节放在低地址位:
0x1234 0x12->0x4000,0x34->0x4001
小端格式:
低字节放在低地址位:
0x1234 0x12->0x4001,0x34->0x4000
Extern:
extern 是声明,不是定义,也不分配空间
extern double pi = 3.14,是声明也是分配空间,也定义
sizeof空间:
C语言中,sizeof是运算符(操作符),不是函数,而且是唯一一个以单词形式出现的运算符,它用来计算存放某一个量需要占用多少字节,它的结合性是从右到左。
Sizeof:共同体取最大变量的为空间大小,结构体字节对齐,枚举大小取其中常数的大小一般为4。
__attribute__((packed)),告诉编译器在编译过程中取消优化对齐
__attribute__((aligned(8)),设定一个指定对齐的大小
__attribute__((at(0x80000000))),设定存储地址
Short A[10]; short *q,*p; q = p = A; p++;
Sizeof((char*)p - (char*)q) = 2;
网络编程基本知识:
访问网址的过程:
1,域名解析为IP地址,DNS
2,与目的主机进行TCP连接(三次握手)
3,发送与收取数据(http)
4,与目标主机断开TCP连接(四次挥手)
域名:baidu.com(通过DNS)《--》主机IP(通过APR)--》(通过RAPR)物理地址
域名+www:网址 + HTTP :URL--》协议,主机,端口号,路径
局域网(LAN),广域网(WAN)
LAN:分为:物理层,MAC层,LLC层
APR:地址解析协议,根据IP地址获取物理地址的一个TCP/IP协议
RAPR:逆地址解析协议,将MAC地址转为IP地址
DNS:域名系统,将一个域名转为一个IP地址
IP地址:用于唯一标识互联网计算机的逻辑地址
域名:IP地址的基础上进行一个符号化的方案
帧中继网:是一种广域网。
一个简单的计算机网络的3个部分为:一个通信子网,一系列通信协议,若干主机。
集线器所有端口是一个冲突域,交换机是一个端口一个冲突域。
在无连接系统UDP中,发送数据不需要联系目的设备。
Internet起源于美国国防部,www万维网起源于英国物理粒子实验室
一般监视套接字的描述符取最大的加1
IP地址长度为32为,分4段,每段8位,范围为1~254,由两部分组成:网络地址+主机地址。
IP地址类型:A类:1~127,B类:128~191,C类:192~223,D类:224~239,E类:240~255
端口号:范围在0~65536,每个协议对应特定的端口号
使用TCP/IP的网络在传输信息时,出现了错误信息,采用的是ICMP协议。
IP地址:非网络号:主机号不能为0,非广播号,主机号不能为255。
网络传递中时延最小的是电路交换
路由器在网络层,网卡在数据链路层。
数据链路层处理设备到设备之间的通信。
传输层处理端节点间的通信
两端用户传输文件在应用层。
数据链路层数据单位为帧,物理层为位,网络层为包
广域网和局域网的中间设备为路由器和交换机
DNS,TFTP,SNMP,因为一次传输数据较少建立在UDP之上。
HTTP,FTP,TELNET,EMAIL,SMTP建立在TCP之上
SMTP是一组用于源地址到目的地址传递邮件的规则
FTP用于Internet上控制文件的双向传输,默认端口号为21
Telnet用于Internet远程登陆服务的标准协议,默认端口号23
POP3允许用户从服务器上把邮件存储到本地主机,同时删除保存在邮件服务器上的邮件。
OSI开发系统互联
404:请求资源不存在,403:表示禁止访问,301:资源永久被转移,302:临时转移,503:服务器暂时无法处理请求
MQTT与Http的区别:
1,MQTT以数据为中心,Http以文档为中心。
2,Http是以请求-响应为模型,Mqtt以订阅-发布为模型,这样是独立存在,当一个客户端出现故障时,不影响整个系统。
3,Mqtt提供3中服务质量,且传输速率比Http块。
系统编程基本知识:
进程和线程区别:
根本区别:进程是操作系统资源分配的基本单位,线程是处理器任务调度和执行的基本单位。
内存分配:在同一进程内的线程是可以共享该进程的地址空间和资源,每个进程的地址空间和资源是相互独立的。
进程之间的通信方式:FIFO,管道,信号,信号量,队列,共享内存,套接字
僵尸进程:
子进程退出,父进程运行,父进程未调用Wait或waitpia,导致子进程变为僵尸进程
危害:占进程表位置,多了就导致进程创建失败
孤儿进程:
子进程运行,父进程退出,子进程由Init进程收养,子进程变为孤儿
无危害
进程在退出时不会销毁自己打开的共享内存
“信号量用在多线程多任务同步的,一个线程完成了某一个动作就通过信号量告诉别的线程,别的线程再进行某些动作(大家都在semtake的时候,就阻塞在 哪里)。而互斥锁是用在多线程多任务互斥的,一个线程占用了某一个资源,那么别的线程就无法访问,直到这个线程unlock,其他的线程才开始可以利用这 个资源。比如对全局变量的访问,有时要加锁,操作完了,在解锁。有的时候锁和信号量会同时使用的
用户栈和内核栈是两个独立的区域,内核栈保存的是内核态运行程序时候的相关寄存器的信息,用户栈保存用户进程的子进程之间相互调用的参数,返回值以及局部变量等。
中断相应过程:CPU接收中断-》保存中断中上下文跳转到中断处理的历程-》执行中断顶半部-》执行中断低半部-》恢复被中断的上下文
顶半部一般用于执行比较紧急的任务,比如清中断,读取寄存器,底半部用于不太紧急的。可以节省中断处理时间
Sftp,scp在Linux中用于传输文件。
Chomd更改的是拥有者(user),所属组群(group),其他用户(other)
一个任务呗唤醒就处于就绪状态
FreeRTOS通过任务优先级来实现任务调度,中断优先级最高。
FreeRTOS里的任务之间通讯可以通过队列、二进制信号量、计数信号量、互斥等几种手段
操作系统一般是用户与计算机的接口
短路求值:
a = 1,b = 0,c = 3;
K = (a < b)&&(c++);
K = 0,c = 3;
Printf:
printf入栈的顺序是从右到左:
Printf(“%d”,a,b);a = 1,b = 2;
最后输出1,先进后出
printf输出字符串遇到’\0’停止输出。
指针与数组的区别。
第1个存储方式的不同数组是存储的成员内容的本身。而指针存储的是首地址。
第2个是运算方式的不同。数组名是一个常量不能进行自增自减的运算,而指针是一个变量,可以进行自增自减的运算。
第3个是赋值运算的操作。数组可以进行初始化操作,但不能通过赋值语句进行整体的赋值,而指针能指向另一条语句。
链表和数组的区别:
数组静态分配内存,链表动态分配内存。
数组在内存中是连续的,链表是不连续的。
数组利用下标定位,查找的时间复杂度是O(1),链表通过遍历定位元素,查找的时间复杂度是O(N)。
数组插入和删除需要移动其他元素,时间复杂度是O(N),链表的插入或删除不需要移动其他元素,时间复杂度是O(1)。
各种基础知识:
Int *p; p = p + 2;这是不合法的,未申请空间,也没有指向空间地址,这样操作属于野指针。
两个指针可以相减,相加得到的地址没有什么意义。
USB采用的是异步通信。
‘\101’转义字符,对应8进制,十进制对应65-》A
Union定义的时候不能初始化
指针在32位机占4字节,在64位机占8字节
16位int范围为-32768~32767
嵌入式常用的数据传递方式为中断。
数组名为指针常量,其值不可改。
函数重载,必定是形参的类型或者个数不同
在C中数组的下标为负数是合理的,指向的只是a[0]前面的一个数,在C#和Java中会报错
ARM处理器的特点为低功耗。
ARM处理器在ARM是32位指令,在Thumb是16位指令,不能同时支持。
在ARM处理器中,Reset的中断优先级最高。
存储器速度由快到慢是:寄存器,缓存,内存,flash
CPU的主要组成部分:运算器,控制器
CPU上的三条总线:数据总线,控制总线,地址总线
完整计算机系统包括:运算器,控制器,存储器,输入设备,输出设备。
双绞线的传输距离无法超过100米。
静态变量的生命周期到程序结束
Typedef和define区别:
#define是C语言中定义的语法,是预处理指令,在预处理时进行简单而机械的字符串替换,不作正确性检查,只有在编译已被展开的源程序时才会发现可能的错误并报错。
typedef是关键字,在编译时处理,有类型检查功能。它在自己的作用域内给一个已经存在的类型一个别名,但不能在一个函数定义里面使用typedef
#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用,而typedef有自己的作用域
#define INTPTR1 int*
typedef int* INTPTR2;
INTPTR1 p1, p2;
INTPTR2 p3, p4;
含义分别为,
声明一个指针变量p1和一个整型变量p2
声明两个指针变量p3、p4
补码转原码:
符号位不变,取反加1。
10011011,以1开头,为负数
取反,符号位不变:11100100 + 1 = 111 00 101
C++基础知识:
Private数据只有基类和友元可访问
Protected数据只有基类,友元,派生可以访问
友元函数不能通过this指针访问对象
在C语言中,只要是非零的数就表示真,不需要一定为整数
标识符由字母数字下划线构成,数字不能在第一位
编译器在提取符号时,总是尽可能多地将后面的符号纳入到前面的表达式,除非纳入之后会让一个有效的表达式变成无效,例如:
a+++b
编译器认为它和下面的式子等价:
(a++)+b

int main()
{
int a[] = {2,4,5,6};
int *p = a;
int **q = &p;
printf("%d",*(p++));
printf("%d",**q);
return 0;
}
值为2,4
*P++可看成*(P++),即先执行p++,后执行*p,但由于这里的“++”号是后加加号
所以会在整条语句执行完后再对P自加一