BilSTM 实体识别_NLP-入门实体命名识别(NER)+Bilstm-CRF模型原理Pytorch代码详解——最全攻略
最近在系统地接触学习NER,但是发现这方面的小帖子还比较零散。所以我把学习的记录放出来给大家作参考,其中汇聚了很多其他博主的知识,在本文中也放出了他们的原链。希望能够以这篇文章为载体,帮助其他跟我一样的学习者梳理、串起NER的各个小知识点,最后上手NER的主流模型(Bilstm+CRF)(文中讲的是pytorch,但是懂了pytorch去看keras十分容易相信我哈)
全文结构:
一、NER资料(主要介绍NER)
二、主流模型Bilstm-CRF实现详解(Pytorch篇)
三、实现代码的拓展(在第二点的基础上进行拓展)
代码运行环境
- 电脑:联想小新Air 13 pro
- CPU:i5 ,4G运行内存
- 显卡:NVIDIA GeForce 940MX,2G显存
- 系统:windows10 64位系统
- 软件:Anaconda 5.3.0 python 3.6.6 Pytorch1.0
一、NER资料
参考:NLP之CRF应用篇(序列标注任务)(CRF++的详细解析、Bi-LSTM+CRF中CRF层的详细解析、Bi-LSTM后加CRF的原因、CRF和Bi-LSTM+CRF优化目标的区别)
CRF++完成的是学习和解码的过程:训练即为学习的过程,预测即为解码的过程。
参考:Bilstm+crf中的crf详解(这份资料对后面代码的理解是有帮助的)


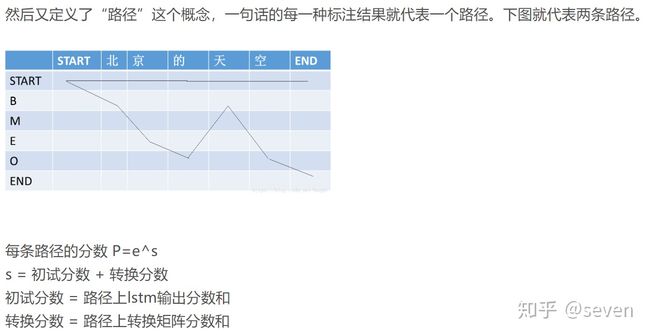

参考:BiLSTM-CRF中CRF层解析-2
在上一篇的参考中提到,会在每一句话的开始加上“START”,在句尾加上“END”,这点我们可能会有疑惑。
这篇参考给予了解答:
这是为了使转移得分矩阵的鲁棒性更好,才额外加两个标签:START和END,START表示一句话的开始,注意这不是指该句话的第一个单词,START后才是第一个单词,同样的,END代表着这句话的结束。
下表就是一个转移得分矩阵的示例,该示例包含了START和END标签。

每一个格里的值表示的意思是:这个格的行值转成列值的概率大小。打个比方:上图中红框(B-Person,I-person)的值为0.9,表示的意思就是B-person转移至I-person的概率为0.9,这是合乎BIO标注的规定的(B是实体的开始,I是实体的内部)。类推一下,蓝框的意思代表的就是B-Organization转移至I-Organization的概率为0.8。
参考:BiLSTM-CRF中CRF层解析-3(看完前面的参考来看这份,简直不要太良心了,易懂很多)
但是前面很多概念有提到,就不赘述了,只是加深一下印象,顺带推一下这个博主对CRF的一系类解析

其中 Pi,yi 为第 i 个位置 softmax 输出为 yi 的概率, Ayi,yi+1 为从 yi 到 yi+1 的转移概率,当tag(B-person,B-location......)个数为n的时候,转移概率矩阵为(n+2)*(n+2),因为额外增加了一个开始位置和结束位置。这个得分函数S就很好地弥补了传统BiLSTM的不足,因为我们当一个预测序列得分很高时,并不是各个位置都是softmax输出最大概率值对应的label,还要考虑前面转移概率相加最大,即还要符合输出规则(B后面不能再跟B),比如假设BiLSTM输出的最有可能序列为BBIBIOOO,那么因为我们的转移概率矩阵中B->B的概率很小甚至为负,那么根据s得分,这种序列不会得到最高的分数,即就不是我们想要的序列。
整个过程中需要训练的参数为:
- BiLSTM中的参数
- 转移概率矩阵A
BiLSTM+CRF的预测:

参考:BiLSTM+crf的一些理解(也是很有帮助的资料,记录如下)
model中由于CRF中有转移特征,即它会考虑输出label之间的顺序性,所以考虑用CRF去做BiLSTM的输出层。
二、NER主流模型——Bilstm-CRF代码详解部分(pytorch篇)
参考1:ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF(PyTorch关于BILSTM+CRF的tutorial)
从参考1中 找到 pytorch 关于 Bilstm-CRF 模型的tutorial,然后运行它,我这里讲一下几个主体部分的作用(我是用jupyter notebook跑的,大家最好也跑完带着疑惑往下看):





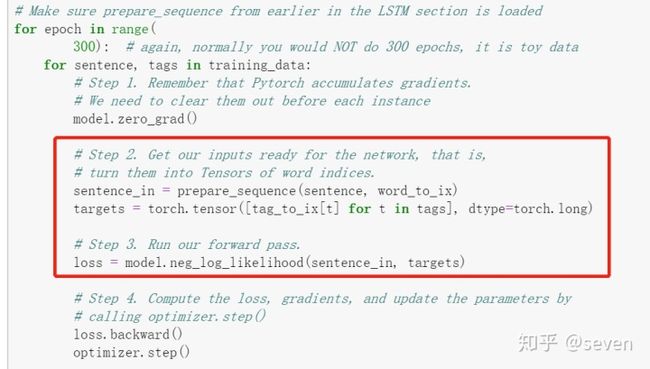
现在的很多NLP的网红模型,无非是将文字到数字的映射建立的更合理。是可拓展的。
另外,这里的模型训练是适用 model.neg_log_likelihood() 。这是代码中建立好的 BiLSTM_CRF 类的一部分,弄明白需继续看 model(参考:pytorch版的bilstm+crf实现sequence label,有模型注解)
torch.nn.Parameter():首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。(参考)【一句话解释:就是希望它能够梯度下降,学习优化】

注意:转移矩阵是随机的,而且放入了网络中,是会更新的)(如果转移矩阵A的概念不懂可以理解了转移矩阵再回来看






参考2:pytorch实现BiLSTM+CRF用于NER(命名实体识别)(提到了viterbi编码,很有启发!记录如下)【统筹CRF算法code,以及forward_score - gold_score 作为loss的根本原因】
CRF是判别模型, 判别公式如下 y 是标记序列,x 是单词序列,即已知单词序列,求最有可能的标记序列

Score(x, y) 即单词序列 x 产生标记序列 y 的得分,得分越高,说明其产生的概率越大。
在pytorch的tutorial中,其用于实体识别定义的 Score(x,y) 包含两个特征函数,一个是转移特征函数,一个是状态特征函数

代码中用到了前向算法和维特比算法(viterbi)
log_sum_exp函数就是计算
,前向算法(_forward_alg)需要用到这个函数
前向算法,求出α(alpha),即Z(x),也就是

,如果不懂可以看一下李航的书关于CRF的前向算法
但是不同于李航书的是,代码中α都取了对数,一个是为了运算方便,一个为了后面的最大似然估计。
这个代码里面没有进行优化,作者也指出来了,其实对feats的迭代完全没有必要用两次循环,其实矩阵相乘就够了,作者是为了方便我们理解,所以细化了步骤
维特比算法(viterbi)中规中矩,可以参考李航书上条件随机场的预测算法
neg_log_likelihood函数的作用:
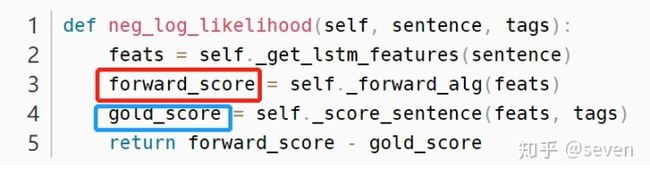
我们知道forward_score是log Z(x),即
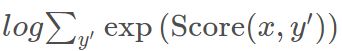
gold_score是

我们的目标是极大化

两边取对数即
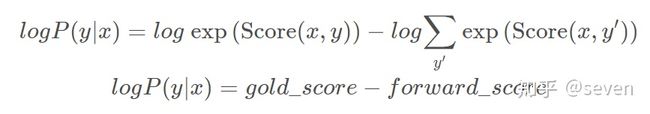
所以我们需要极大化 gold_score - forward_score,也就是极小化 forward_score - gold_score。
这就是为什么 forward_score - gold_score 可以作为loss的根本原因。
参考3:Bi-LSTM-CRF for Sequence Labeling(记录如下)
这篇跟参考2讲的是一个意思。得分score表示为

也很清晰地提到了CRF的作用以及score中P和A矩阵分别代表的含义:P为Bi-LSTM的输出矩阵;A为tag之间的转移矩阵

在许多参考文章中都有提到score的成分包含了两部分,一个是Bilstm的输出结果,另一个就是CRF的转移矩阵,而转移矩阵的作用就是去给标注结果一些约束。例如标注B的后面不能接B这种约束。这种约束是根据转移矩阵A提供的。而转移矩阵A是根据你提供的训练集,训练学习、梯度下降得到的。根据画红线的去看上方score的定义,就明白定义了每一种标注情况为一条路径,使用score去计算该路径的得分的意思了。再啰嗦一下:Ayi, yi+1是表达这个tagyi(标注yi)转移至下一个tagyi+1(标注yi+1)的分数(概率)。而Pi,yi就是Bilstm的输出矩阵,可以看到每个字对应到不同tag(标注)的分数。【不懂也没关系,有很多文章都提到了。反复看就会有感觉了】
CRF的概率函数表示为

S(X,y)的计算很简单,而

(下面记作logsumexp)的计算稍微复杂一些,因为需要计算每一条可能路径的分数。这里用一种简便的方法,对于到词的路径,可以先把到词的logsumexp计算出来,因为

因此先计算每一步的路径分数和直接计算全局分数相同,但这样可以大大减少计算的时间。
参考4:BiLSTM-CRF中CRF层解析-4(用程序的思想去理解怎么计算所有路径的得分和,巨良心)
这篇文章提到了动态规划的编程思想,虽然跟pytorch的tutorial有些许偏差。但已经很到位了。卡在_foward_alg函数的同学多看几遍这篇文章,先理解一下动态规划的思路吧。会有帮助的。
参考5:BiLSTM-CRF中CRF层解析-5(还是这个系列,讲预测)
上一篇在讲loss的一部分:所有路径的得分和。现在讲怎么去解码预测。大概的思路就是根据最高的得分去反哺这条路径,使用较多的就是Viterbi解码了。这篇文章就很详细很详细地提到了怎么去解码这个路径,具体就直接进到博主的解析上看吧!致敬一下参考4和参考5的作者:勤劳的凌菲
参考6:pytorch lstm crf 代码理解(走心的解读,统筹代码块的作用,其心得部分十分到位)
这里就罗列一下作者的心得体会:
- 反向传播不需要一定使用forward(),而且不需要定义loss=nn.MSError()等,直接score1 - score2 (neg_log_likelihood函数),就可以反向传播了。
- 使用self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size)) 将想要更新的矩阵,放入到module的参数中,然后两个矩阵无论怎么操作,只要满足 y = f(x, w),就能够反向传播
- 从代码看出每个循环里只是去了转移矩阵A的一行,或者就是一个值,进行操作,转移矩阵就能够更新。至于为什么能够更新,作者也不知道,这涉及到pytorch的机制。
- 发射矩阵(emit score)是 BiLSTM算出来的。转移矩阵是单独定义的,要学习的。初始矩阵是 [-1000,-1000,-1000,0,-1000],固定的。因为当加了开始符号后,第一个位置是开始符号的概率是100%。
- 显式的加入了start标记,隐式的使用了end标记(总是最后多一步转移到end)的分数
参考7:PyTorch高级实战教程: 基于BI-LSTM CRF实现命名实体识别和中文分词
对这份pytorch NER tutorial,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中。但这种方式并不适合处理很多的数据(数据格式迁移问题),但是对于 demo 来说非常友好,把英文改成中文,标签改成分词问题中的 “BEMS” 就可以跑起来了。
参考资料:
- pytorch中bilstm-crf部分code解析(也很良心了,作者画了草图帮助理解)
- pytorch版的bilstm+crf实现sequence label(比较粗的注解)
三、模型代码拓展部分(pytorch篇)
前面我们介绍了很久pytorch实现NER任务的主流model——Bilstm+CRF,为了便于新手入门,所以还是稍微简陋了一些。刚好看到有份资源是移植这个tutorial去实践的,还是很有必要学习的
资料:ChineseNER(中文NER、有tf和torch版,市面上Bilstm+CRF的torch code基本都是出自官方tutorial)(py2.7)
因为是py2的代码,所以是需要改成py3的。
训练代码:train_py3.py

但这个“Bosondata.pkl”是需要我们先到路径“ChineseNERdataboson”下运行"data_util.py"才生成的

当然,原代码也是存在python版本的问题(原代码是py2的)例如:
报错:AttributeError: 'str' object has no attribute 'decode'
解决方法:把 .decode("*") 那部分删除即可
溯源:https://www.cnblogs.com/xiaodai0/p/10564471.html
报错:ImportError: No module named 'compiler.ast'
解决方法:重新写一个函数来替代 from compiler.ast import flatten 的flatten函数
import collections
def flatten(x):
result = []
for el in x:
if isinstance(x, collections.Iterable) and not isinstance(el, str):
result.extend(flatten(el))
else:
result.append(el)
return result溯源:https://blog.csdn.net/w5688414/article/details/78489277

当成功运行"data_util.py"生成“Bosondata.pkl”后,把"train_py3.py"里面第38行的"word2id"修改为"id2word"(应该是作者打错了),然后在代码路径下创造文件夹“model”,就可以开始训练了。
最后附上修改后的github源码
Hyfred/Pytroch_NER_tutorialgithub.com
供参考借鉴,感谢大家。