【目标检测】Fast R-CNN前言
目录:论文Fast R-CNN前言总结
- 一、概述
-
- 1. 背景
- 2. R-CNN缺点
- 3. SPPNet
- 二、Fast R-CNN简介
- 三、ROI pooling layer
- 四、fine-tuning
一、概述
1. 背景
简化了最先进的基于卷积网络的目标检测器的训练过程(R-CNN)。提出一个单阶段训练算法,联合学习候选框分类和修正他们的空间位置。
所得到的方法用来训练非常深的检测网络(例如VGG16) 比R-CNN快9倍,比SPPnet快3倍。在运行时,检测网络在PASCAL VOC 2012数据集上实现最高准确度,其中mAP为66%(R-CNN为62%),每张图像处理时间为0.3秒,不包括候选框的生成。测试时间比R-CNN快213倍。
2. R-CNN缺点
1、训练过程是多级流水线(multi-stage pipeline)
- R-CNN首先使用目标候选框对卷积神经网络使用log损失进行微调。
- 然后,它将卷积神经网络得到的特征送入SVM。 这些SVM作为目标检测器,替代通过微调学习的softmax分类器。
- 在第三个训练阶段,学习检测框回归。
2、训练时时间和空间开销大
对于SVM和检测框回归训练,从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,这个过程在单个GPU上需要2.5天(VOC07 trainval上的5k个图像)。这些特征需要数百GB的存储空间。
3、目标检测速度慢
在测试时,从每个测试图像中的每个目标候选框提取特征。用VGG16网络检测目标每个图像需要47秒(在GPU上)。
R-CNN很慢是因为它为每个目标候选框进行卷积神经网络正向传递,而不共享计算。
因为是分阶段训练,训练SVM和bbox回归时无法更新前面CNN的参数,模型精度上不去。
3. SPPNet
SPPnet通过共享计算加速R-CNN。SPPnet计算整个输入图像的卷积特征图,然后使用从共享特征图提取的特征向量来对每个候选框进行分类。通过最大池化将候选框内的特征图转化为固定大小的输出(例如,6X6)来提取针对候选框的特征。多个输出被池化,然后连接成空间金字塔池。SPPnet在测试时将R-CNN加速10到100倍。由于更快的候选框特征提取训练时间也减少3倍。
缺点:
- 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器.
- 特征需要写入磁盘
- 训练SVM,bbox回归时算法不能更新卷积层的参数,这会影响网络的精度
二、Fast R-CNN简介
其论文的名字就是 Fast R-CNN。使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(再Pascal VOC数据集上)。
针对上述问题,Fast R-CNN的想法是将整个模型分成两步:
-
第一步是选取候选区域
-
第二步就是提出一个RoI层,整合了整个模型,把CNN、变换层、SVM分类器、bbox回归这几个模块整一起,大家一起训练
新的模型将多个训练阶段合并,训练后面阶段的同时可以更新前面阶段的参数,模型收敛的更好了。同时因为多个阶段合并,候选区域的特征不需要再写入磁盘,一直在显存中,训练的速度大大的提升。
Fast R-CNN 算法流程可分为3个步骤:
-
一张图像生成1K~2K个 候选区域(使用Selective Search方法
-
将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
-
将每个特征矩阵通过ROI(Region of Interest) pooling层缩放到 7x7 大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
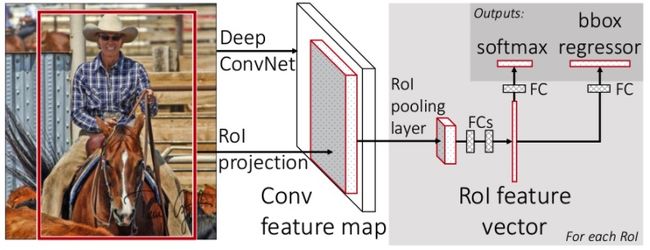
Fast R-CNN网络将整个图像和一组候选框作为输入。
1、网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。
2、然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。
把图片的候选区域映射到feature map得到对应的patch(这和SPPNet的处理类似)。然后把这个patch塞给ROI层(Region of interest)得到固定大小的的特征向量(feature vector).
3、每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :
- 一个输出K个类别加上1个背景类别的Softmax概率估计
- 另一个作为bbox回归,输出回归的选框数据。即为K个类别的每一个类别输出四个实数值。每组4个值表示K个类别的一个类别的检测框位置的修正。
三、ROI pooling layer
作用:
- 把不同尺寸的侯选区域提取特征变换成为固定大小的特征向量
每个RoI由指定其左上角(r,c)及其高度和宽度(h,w)的四元组(r,c,h,w)定义。
RoI最大池化通过将大小为 h×w 的RoI窗口分割成 H×W 个网格,子窗口大小约 h/H×w/W,然后对每个子窗口执行最大池化,并将输出合并到相应的输出网格单元中。其中 H 和 W 是层的超参数,独立于任何特定的RoI。
通过该层,可以将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
四、fine-tuning
用反向传播训练所有网络权重是Fast R-CNN的重要能力。
- 为什么SPPnet无法更新低于空间金字塔池化层的权重?
根本原因是当每个训练样本(即RoI)来自不同的图像时,通过SPP层的反向传播是非常低效的,这正是训练R-CNN和SPPnet网络的方法。低效的部分是因为每个RoI可能具有非常大的感受野,通常跨越整个输入图像。由于正向传播必须处理整个感受野,训练输入很大(通常是整个图像)。
提出了一种更有效的训练方法:利用训练期间的特征共享。