服务器RTX3090安装显卡驱动,cuda,cudnn,gpu版pytorch记录
这东西有点麻烦,RTX3090还是很矫情的。操作一致,机器一致,但是每一次安装都会遇到不一样的问题???
先列一下笔者安装成功的所有的标准配置版本,尽量和标准配置一样,否则会出一些奇奇怪怪的阴间问题。
系统:ubutnu 18.04.6 LTS
内核:GNU/Linux 5.4.0-91-generic x86_64
驱动:470.82.01
cuda:11.4
cudnn:8.2.4
anaconda3:5.2.0
如果按照博客的来,中间没有遇到问题的话,预计一个小时左右能够全部安装完毕
(当然很可能会遇到各种各样的问题…)
1. 安装ubuntu 18.04
正常来说18.04和20.04应该都是可以的,16.04就不行,因为会不支持很多RTX3090需要的依赖。
注意:本篇博客的安装流程以18.04为例(最后成功),笔者先前也在20.04上尝试过一样的安装流程,中间除了有遇到过内核版本问题以外,最终也能够安装成功,因此按照流程来基本也可行。简言之,推荐读者使用和笔者一样的配置,即使用ubutnu 18.04 LTS版本。
随便网上搜个教程就行(比方说这个),在其他windows机器上制作启动盘(比方説用UltralSO),然后目标机器通过u盘启动。目标机器插上启动盘,重启狂按del(看自己设备是哪个键),如果重启之后进不了BIOS,那么按照下面这篇博客的来(假设目标机器本来就是linux,如果是windows的话自行百度相对而言更简单):
解决安装 Ubuntu 后无法进入BIOS、UEFI 和Grub 引导
安装的时候,语言尽量选择英语,不然很多路径会有些问题。然后看你自己的情况,选择要不要清空磁盘。中间其他的选项默认就行。
基本上不出意外是可以重装成功的,这一步没啥难度。
2. 配置apt source,ssh,make,etc.,并更换内核
更换内核版本
这一步其实是可选的,而且针对的是ubutnu20.04。所以,如果读者机器的内核版本已经是5.4以上了,请跳过这一步。
因为笔者先前使用ubutnu 20.04的时候,出现过因内核版本太低导致后续各种apt install的奇怪问题。这里的话采用5.4.50版本的内核。
首先使用uname -r查看当前内核版本 :
![]()
然后去官网下载对应的内核版本,比方说我这里想装5.4.50的话,找到对应的目录(选择amd64这个folder,目前大家的机器应该都是AMD64位),然后下载如下所示4个文件(三个generic的.deb文件,还有一个all.deb文件):

记得把这四个.deb文件放到服务器某个单独的文件夹下(确保该文件夹下没有其他.deb文件),然后在该目录下运行:
sudo dpkg -i *.deb

之后的话可以重启,然后进入到grub引导里面手动选择刚刚新添加的内核版本,但是这样的话太麻烦,每次重启之后都要手动选择,所以这里选择修改grub配置文件来永久更改。
先输入cmd查看目前的内核:
grep submenu /boot/grub/grub.cfg
![]()
把上面这段输出中的gnulinux-advanced-f4aefacb-f5c2-4f42-809d-be71507b305f先存着,然后再输入:
grep gnulinux /boot/grub/grub.cfg

把上面这段输出中的gnulinux-5.4.50-050450-generic-advanced-f4aefacb-f5c2-4f42-809d-be71507b305f也存着(注意是上图红框内的那行generic, 不是下面那行recovery)
最后把上面那两段存着的字符组合成如下(>可以理解为切换):
gnulinux-advanced-f4aefacb-f5c2-4f42-809d-be71507b305f>gnulinux-5.4.50-050450-generic-advanced-f4aefacb-f5c2-4f42-809d-be71507b305f
写到grub配置文件里,把GRUB_DEFALUT=0替换成上面这段(注意要加上引号):
sudo vim /etc/default/grub

最后输入sudo update-grub更新:

reboot,再输入uname -r查看是否切换内核成功:
![]()
apt
装好之后先给apt换个源
## 备份source
cp /etc/apt/sources.list /etc/apt/sources.list.back
## 编辑换源,vim当然也行,如果有的话
vi /etc/apt/sources.list
把sources.list中的内容替换为中科大源(注意不要用清华源,已经停更了据说,笔者之前用了阿里云源,会有点问题,ustc验证过是没问题的):
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb-src https://mirrors.ustc.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
然后:
sudo apt update ## 更新apt软件源
sudo apt upgrade ## 更新所有软件
理论上来讲是不会有error的。(有error的话你就得考虑要不要继续往下了,凭笔者重装10+次的经验得出来的血泪教训)
另外,不同的ubuntu版本可能需要不同的源,如果读者在网上搜索ubutnu apt源,切记要带上自己的ubuntu版本号。一定要确保apt update 和 upgrade没有问题才行,否则换个博客换个源。
net-tools、vim
下载一些必备的包(可以根据自己的需求再安装一些):
sudo apt install net-tools
sudo apt-get install vim
sudo apt-get install git
ssh
如果此台机器是服务器,后续有远程用自己pc机连服务器的需求,那么可以有这一步,否则也可以跳过这一步。
安装openssh
sudo apt-get install openssh-server
开启ssh:
service sshd start
执行上述要是遇到openssh-client的依赖问题,类似于下图:

可以通过删除重装openssh-client来解决,具体参考:安装openssh-server失败解决
上述ssh server打开之后的话可以通过其他pc机ssh远程连接该台机器进行后续的操作。具体而言,先使用ifconfig查看本机的ip地址:

然后在其他机器上用ssh [email protected] 输入登录密码进去。
因为每次用ssh登陆的时候都要输一次密码还是比较麻烦,可以直接自己的pc机上生成密钥对,然后把公钥cp到服务器上:
ssh-keygen
之后可以输入你自己的秘钥,当然还是建议直接enter跳过,不然的话到时候连ssh其实还是要输密码…
ssh-copy-id [email protected]
这样之后再用ssh连接远程主机的时候,这台机器就不用输密码。

如果copy秘钥的时候出现如下所示错误(说明你的这台pc之前连接过一个同IP地址的服务器):

则尝试替换掉原先本机的秘钥:
ssh-keygen -R XXX ## XXX 为上述的目标服务器IP

之后再重复上述操作,将秘钥copy到服务器上即可。
gcc & cmake
服务器上还得有个g++、cmake等(后面装驱动会用到):
sudo apt-get install build-essential
build-essential会把这一类所有相关的依赖都安装完毕。
可以尝试看看有没有安装成功:
gcc --version

make -v

之后可以给实验室所有同学设置usr group和sudo权限,这里略过。
3. 安装显卡驱动
这一步有点麻烦,自己也探索了好久,中间也难免重装了好几次系统(头疼.jpg)
先用如下命令查看设备属性:
ubuntu-drivers devices
如下为例,会有推荐的driver版本:

如果上述命令没有输出,那试试看添加ppa源:sudo add-apt-repository ppa:graphics-drivers/ppa之后再尝试。
之后建议离线安装包安装,可以去nvidia官网下载对应的显卡驱动,如果网速太慢,可以去下面这个镜像站:
NVIDIA_DRIVER(找到自己的版本)
下载之后上传服务器(当然也可以在服务器上wget),然后运行安装:
bash NVIDIA-Linux-x86_64-470.86.run
注意,如果你是自己用的pc机,需要图形界面的话,这个地方必须加上参数--no-opengl-files,否则到时候机器一旦重启,你就无法进入图形界面;当然,如果是实验室大家用的服务器(都是用ssh登录,用不到图形界面),那这个地方不加上也可以,因为图形界面默认会占用一小部分显存(笔者就选择了关闭图形界面)。
该参数的具体解释详见:Ubuntu 安装 cuda 时卡在登录界面(login loop)的解决方案之一
进入到安装界面(中间一些选择,默认就行):



之后用nvidia-smi试试看有没有装好:

正常来说离线安装应该是没问题。
当然…可能会遇到很多奇奇怪怪的毛病,下面举几个自己遇到的:
bug 1. 没有禁用nouveau
若是老老实实按照笔者上述流程来安装,这个bug必出现,莫慌!
其实网上几乎所有博客都是建议安装驱动前,先用各种方法把nouveau集成显卡驱动禁用。笔者这里之所以没有事先禁用是因为踩了坑(不知道为何,按照网上各种贴子禁用方法,修改/etc/modprobe.d/blacklist-nvidia-nouveau.conf之后重启,机器的网卡驱动就也会被莫名禁用,试了各种方法,没有解决)。
后来灵机一动,安装nvidia-driver的时候,若是没有事先禁用nouveau,那么安装程序会让你选择是否在etc目录下写一个文件来禁用nouveau。毫无疑问,这自己手动去改配置文件,肯定没有人家程序自动改来得靠谱啊。
所以,按照笔者上面的流程安装,必然会遇到安装过程中提示类似于"nouveau已经存在"的字样,这个时候选择自动写入etc禁用nouveau即可(这一步忘记截图了,意会即可)。
然后自己可以手动用sudo update-initramfs -u更新一下,再重启一下
重启之后,terminal输入lsmod | grep nouveau确保没有任何输出显示,说明nouveau禁用成功。
再重新运行显卡驱动安装就可以。理论上来说,这次就不会再有错误。
12.2更新:今天在ubuntu18.04上按照上述流程又装了一遍,发现没有禁用nouveau(lsmod | grep nouveau会有一堆输出),显卡驱动还是安装成功了…很玄学,貌似20.04大概率是需要禁用nouveau的。
bug 2. driver版本不兼容
如果出现下面的报错:

打开nvidia-installer.log之后看到如下:

说明驱动版本和自己机器不兼容。
因此,建议选择ubuntu-drivers devices中推荐的版本。
或者,可以尝试如下ppa安装方法(没试过但是感觉蛮高赞的):
stackexchange
4. 安装anaconda和python环境
下载安装
推荐去清华镜像,找到anaconda3-5.2.0

下载之后bash运行这个sh文件,然后进入anaconda安装界面:
press ‘yes’之后,这个地方注意一下,让你选择安装路径,如果是自己用的pc机,那么默认的路径没问题,如果是团队用的服务器,注意尽量不要装在root根目录,一般实验室每个人都有自己代码数据的存储路径,最好更改conda下载路径到自己的路径:

这个过程中会提示是否写入环境变量,建议no,后面会手动添加。
环境变量
建议手动配置环境变量,这里有两种选择:
- 导入conda.sh到usr bashrc(只对当前用户生效,推荐):
echo ". XXX/anaconda3/etc/profile.d/conda.sh" >> ~/.bashrc ## XXX为之前那步你选择安装的anconda的位置
echo "conda activate" >> ~/.bashrc
source ~/.bashrc ## 刷新bashrc
- 建立一个全局的软连接(对所有用户生效,不是很推荐):
sudo ln -s XXX/anaconda3/etc/profile.d/conda.sh /etc/profile.d/conda.sh ## 建立软连接,该操作针对所有用户
echo "conda activate" >> ~/.bashrc
source ~/.bashrc ## 刷新bashrc
之后打开新的terminal,不出意外,应该会自动进入conda的base环境:
![]()
注意!老版本的conda在配置环境变量时(包括之前一步,如果选择让anaconda自动配置环境变量的话),大多用以下这种:
echo "export PATH=XXX/anaconda3/bin:$PATH" >> ~/.bashrc ## XXX为之前那步你选择安装的anconda的位置
但是比较新的conda应该是要按照笔者上述这种方法来配置,而且官方推荐.bashrc文件里面不能有上面这行(但是笔者自己试的时候,加上也可以照样也还是能激活base,只不过会报个错,可能强迫症会有点难受)。
5. 安装cuda、cudnn
这里提醒一下,如果要目标机器需要安装多个版本的cuda的话 (比方说实验室一群人用的服务器,每个人都有不同的cuda版本需要),那么请使用笔者另一篇博客:同台设备配置多cuda环境, 来代替第5节内容(这里用的是run file安装,相对而言更稳妥,但是没有办法安装多cuda)
首先去官网查看自己做安装的driver版本和cuda、cudnn之间的对应,可以参考我另一篇blog:
查看cudnn和cuda,cuda和driver之间的对应关系
cuda安装
然后去下载cuda(选run file):
官网cuda下载地址
安装运行之前最好检查一下有没有gcc:
gcc --version

首先需要给可执行行权限:
sudo chmod a+x cuda_11.4.3_470.82.01_linux.run
然后安装:
sudo sh cuda_11.4.3_470.82.01_linux.run
输入accept

选择install

最后屏幕会出一个summary

配置环境变量:
vim ~/.bashrc
末尾加上(改为自己的cuda安装路径):
export PATH="/usr/local/cuda-11.4/bin${PATH:+:${PATH}}"
export LD_LIBRARY_PATH="/usr/local/cuda-11.4/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
更新bashrc:
source ~/.bashrc
之后用nvcc -V试试看有没有成功(注意这个-V是大写的!),有如下输出则表示cuda安装成功:

cudnn安装
之后下载cudnn(需要用邮箱注册一个账号):
官网cudnn下载地址
需要下载下面四个(一个tar包,三个deb):

对于下载的cudnn的tar包,解压tar -zxvf cudnn-11.4-linux-x64-v8.2.4.15.tgz -C ./之后,当前目录下会多一个名为cuda的folder,之后cp cudnn.h 和 lib64 这两个库(根据自己cuda的路径调整),并更改这两个库的权限:
sudo cp cuda/include/cudnn.h /usr/local/cuda-11.4/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-11.4/lib64
sudo chmod a+r /usr/local/cuda-11.4/include/cudnn.h /usr/local/cuda-11.4/lib64/libcudnn*
然后安装那三个libcudnn的Deb包:
sudo dpkg -i libcudnn8_8.2.4.15-1+cuda11.4_amd64.deb
sudo dpkg -i libcudnn8-dev_8.2.4.15-1+cuda11.4_amd64.deb
sudo dpkg -i libcudnn8-samples_8.2.4.15-1+cuda11.4_amd64.deb

重启验证
上面的cuda和cudnn安装之后可以reboot重启一下,输入以下命令检验是否安装成功:
cd /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery
sudo make
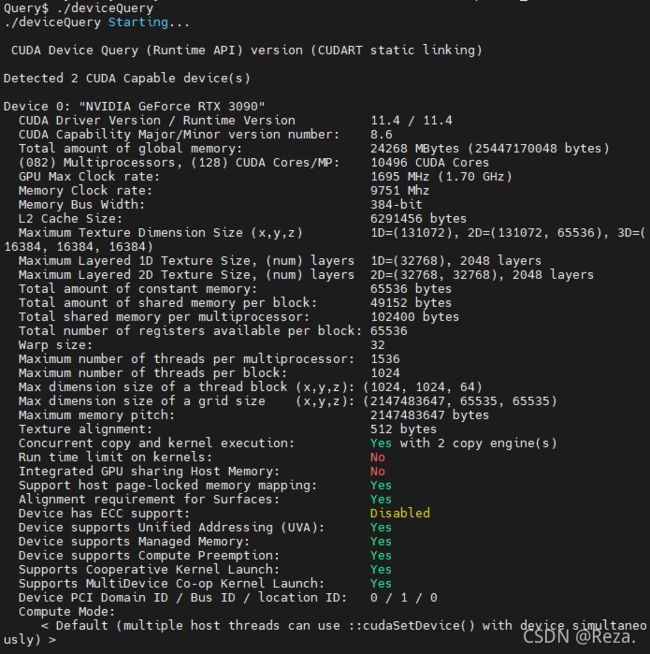
./deviceQuery
若是安装成功,运行之后terminal里面最后会有一个Result = PASS:

6. 安装cuda版本的pytorch
pip&conda换源
先把pip源换成国内,详见我的另一篇博客:
pip 一键换源
顺带也把conda源换了,详见我的另一篇博客:
conda换源
安装torch
这里要提醒一下:如果设备是RTX3090的话,是不能使用cuda11以下的torch的(也就是只能用torch>=1.7),因为RTX3090相对而言比较新,如果是cuda11以下的torch是不能兼容RTX3090提供的算力的(你可以安装没有报错,但是在用GPU的时候会报错)
先去官网确定自己的torch和torchvision之间的对应版本关系:

然后去下载离线包,找到对应版本的torch和torchvision:
离线包下载地址


之后pip安装即可:
pip install torch-1.8.0+cu111-cp38-cp38-linux_x86_64.whl
pip install torchvision-0.9.0+cu111-cp38-cp38-linux_x86_64.whl
此处需要提醒一点,若是安装的cuda版本高于torch支持(比方说笔者这里,cuda版本是11.4,但是安装的torch1.8.0只支持最高11.1).一般来说安装之后问题不是很大,只要差的版本不是很大就行。但最好还是一致。 详见:本机cuda版本可以高于安装pytorch时的cuda版本吗?
之后可以安装一些其他依赖,pandas,json,etc.有关于TensorFlow GPU版本,还有类似于Keras,这里不做介绍。
7. 验证
最后验证一下是否安装成功,terminal里进入python环境,然后执行以下代码:
import torch
torch.cuda.is_available() ## 输出应该是True
t=torch.nn.Linear(3,3)
t.to("cuda:0")
input=torch.randn((3,3)).requires_grad_().to("cuda:0")
output=t(input)
loss=torch.sum(output)
torch.autograd.grad(loss,input,retain_graph=True) ## 输出应该是一个gpu上的梯度矩阵
loss.backward()
没有报错则算成功,说明可以使用gpu进行推理反传
8. 其他
最后再吐槽一下网上很多博客,有些误人子弟,当然也有一些其实是可以成功的,但是毕竟每个人机器都不是很一样,这里面变量很多,你也不知道别人的方法在你那里行不行得通。总之,装环境这种切忌盲目跟,很多时候你不仅需要拥有检索搜集信息的能力,还需要知其然并知其所以然(人家为什么要用这个cmd?你的问题和人家的问题是一个问题吗?)。要是装的时候感觉仿照的这篇博客不太对头了,好像它的问题报错和我有点不太一样,或者它的屏幕输出和我有点不太一样,那么应该考虑赶紧换一篇(包括本篇)。
最后,胆大心细吧,退一百步讲,大不了装错了重装系统呗(笔者写这篇重装了10+次,感觉每一步操作都能背出来了…);还要有耐心,装环境还是可以增强自己的能力的。