Python NLP 入门
Python NLP 入门 用TextBlob进行情感分析
目前在NLP领域取得的成就为我们提供了能够在不同层次上分析自然语言的工具:从单词和文本分割到对静态单词背后的情绪的实际理解,即所谓的情感分类方法。
然而,一些方法的复杂性并不必然意味着你应该在编程方面有很高的造诣,才能在Python中实现情感分析这样的高级任务。
情感分析 情感分析的重点是在文本语料库中区分意见、态度,甚至是表情符号。
因此,定义情感的范围在不同的方法之间有很大差异。虽然一个标准的分析器最多可以确定三种基本的极性情绪(积极、消极、中性),但精炼模型的限制要宽泛得多。
因此,他们可以超越极性,确定六种 "普遍 "情绪,如愤怒、厌恶、恐惧、快乐、悲伤和惊讶。

此外,根据你正在进行的任务,也可以从上下文中收集额外的信息,如作者或一个主题。这些数据可以帮助避免一个更复杂的问题,而不仅仅是在进一步分析中对两极的通常分类--即主观/客观的识别。
例如,让我们以《商业内幕》中的这句话为例
3月,埃隆-马斯克将对冠状病毒爆发的担忧描述为 "恐慌 "和 "愚蠢",此后他在推特上发布了不正确的信息,比如他认为儿童对该病毒 "基本免疫 "的理论。
正如你所看到的,这里的主观性是通过E.Musk和文本作者的个人意见表达的。
TextBlob软件包
TextBlob包的优势在于其基于规则的性质:要进行情感分析,TextBlob需要一套预先定义的分类词,例如可以从NLTK数据库中下载。
此外,情感是根据语义关系和输入句子中每个词的频率来确定的,因此可以获得更准确的输出。
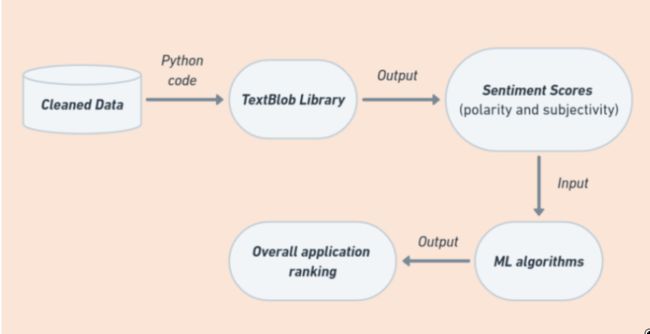
一旦第一步完成,Python模型得到了必要的输入数据,用户就会收到上面提到的以极性和主观性为形式的情感分数。我们可以在下面的图表中看到这个过程是如何进行的。
作者制作的图表
TextBlob对极性任务的输出是一个范围为[-1.0, 1.0]的浮点数,其中
-1.0为负数 1.0为正极性
这个分数也可以等于0,代表对一个语句的中性评价,因为它不包含训练集中的任何词语。 而主观性/客观性识别任务报告的浮动范围是[0.0, 1.0],其中
0.0是非常客观的
1.0是一个非常主观的句子
有各种Python与TextBlob情感分析器交互的例子:从基于不同Kaggle数据集的模型(如电影评论)开始,到通过Twitter API计算推文的情感。
如何构建一个情感分析器
让我们看看一个简单的分析器,我们可以应用于一个特定的句子或一个短文。我们首先从导入TextBlob库开始。
导入TextBlob
from textblob import TextBlob
导入后,让我们加载一个用于分析的句子,并实例化一个TextBlob对象,同时将情感属性分配给我们自己的分析。
准备一个输入句子
sentence = '''该平台提供世界上最好的教育的普及,与顶级大学和组织合作,提供在线课程。'''
sentence = '''The platform provides universal
access to the world's best education,
partnering with top universities and
organizations to offer courses online.'''
#创建一个textblob对象并分配情感属性
analysis = TextBlob(sentence).sentiment
print(analysis)
注意,情感属性是一个Sentiment(polarity, subjectivity)形式的命名元组。
其中,分析的预期输出是。
Sentiment(polarity=0.5, subjectivity=0.26666666666666666)
如果你只对这两个指标中的一个感兴趣,也可以通过简单地执行以下命令来单独获得结果。
from textblob import TextBlob
# 准备一个输入句子
sentence = '''The platform provides universal access to the world's best education, partnering with top universities and organizations to offer courses online.'''
analysisPol = TextBlob(sentence).polarity
analysisSub = TextBlob(sentence).subjectivity
print(analysisPol)
print(analysisSub)
这将给我们带来输出。
0.5
0.26666666666666666
TextBlob的一大优点是,它允许用户选择一种算法来实现高级NLP任务。
PatternAnalyzer--默认的分类器,建立在模式库之上 NaiveBayesAnalyzer--基于电影评论语料库训练的NLTK模型 要改变默认设置,我们只需在代码中指定一个NaiveBayes分析器。
从实践到实际数据 让我们对直接来自Twitter的推文进行情感分析。
from textblob import TextBlob
# 用于解析推文
import tweepy
# 从NLTK导入NaiveBayesAnalyzer分类器
from textblob.sentiments import NaiveBayesAnalyzer
之后,我们需要通过API密钥(你可以通过开发者账户获得)与Twitter API建立连接。
# Uploading api keys and tokens
api_key = 'XXXXXXXXXXXX')
api_secret = 'XXXXXXXXXXXX')
access_token = 'XXXXXXXXXXXX'.
access_secret = 'XXXXXXXXXXXX')
# 建立连接
twitter = tweepy.OAuthHandler(api_key, api_secret)
api = tweepy.API(twitter)
现在,我们可以对任何主题的推文进行分析。一个被搜索的词(如lockdown)既可以是一个词,也可以是更多。由于这个任务会因为大量的推文而耗费时间,因此强烈建议限制输出。
# 这个命令将在一个 "封锁 "主题中调回5条推文
corpus_tweets = api.search("lockdown", count=5)
for tweet in corpus_tweets:
print(tweet.text)
这最后一段代码的输出将带回五条提到你的搜索词的推文,其形式如下。
RT@DhwaniPandya: 亚洲最密集的贫民窟如何遏制病毒以及盯着勤劳的贫民窟人口的经济灾难...... 这个例子的最后一步是将默认模型切换到NLTK分析器,该分析器将其结果以命名图元的形式返回。Sentiment(classification, p_pos, p_neg)。
# 应用NaiveBayesAnalyzer
blob_object = TextBlob(tweet.text, analyzer=NaiveBayesAnalyzer())
# 运行情感分析
analysis = blob_object.sentiment
print(analysis)
最后,我们的Python模型将得到以下情感评价。
Sentiment(classification='pos', p_pos=0.5057908299783777, p_neg=0.49420917002162196)
这里,它被归类为积极情绪,p_pos和p_neg值分别为~0.5。
总结
在这篇文章中,我们不仅介绍了情感分析的基本原理,而且还通过使用TextBlob包来构建一个实际的分析器的教程。
TextBlob是一个解决NLP挑战的强大库,因为它提供了一个简单的API,让用户可以快速跳到执行NLP任务。
本文由 mdnice 多平台发布