lecture 18:几种估计方法与标准误
1、林林总总的标准误
标准误在统计推断中发挥着至关重要的作用,直接影响着系数的显著性和置信区间,并最终影响到假设检验的结论。因此,正确地估计标准误在实证分析的过程中显得尤为重要。当干扰项满足「独立同分布 (iid)」 条件时, OLS 所估计的标准误是无偏的。但是当误差项之间存在相关性时,OLS 所估计的标准误是有偏的,不能很好地反映估计系数的真实变异性 (Petersen, 2009),故需要对标准误进行调整。在多种调整标准误的方式中,「聚类调整标准误 (cluster)」是一种有效的方法 (Petersen, 2009)。
相关内容可参考 Petersen (2009)、Thompson (2011)、 Cameron and Miller (2015)、 Abadie et al. (2017) 、Gu and Yoo (2019)等文献。
1. 应对异方差,使用white标准误等等
调整OLS估计的协方差矩阵(covariance matrix)的位置,并修正OLS估计的标准误差。目前学者们已经提出了多个调整方法,并且statsmodels对应于以下类型。
HC0:White(1980)的不均匀分散健壮协方差矩阵估计
HC1:Mackinon and White(1985)的不均匀分散健壮协方差矩阵推定v1
HC2:MacKinnon and White(1985)的不均匀分散健壮协方差矩阵推定v2
HC3:MacKinnon and White(1985)的不均匀分散健壮协方差矩阵推定v3
使用wooldridge包装的数据集gpa3进行说明。在这个例子中,我们将探索大学GPA和高中的成绩、性别、人种等有着怎样的关系。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
import lmdiag
import wooldridge
from statsmodels.stats.api import het_breuschpagan, het_white
from seaborn import residplot
from statsmodels.stats.outliers_influence import reset_ramsey
gpa3 = wooldridge.data('gpa3').query('spring == 1') #
wooldridge.data('gpa3', description=True)
wooldridge.data('gpa2', description=True)
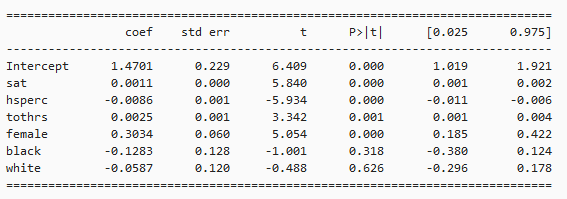
form_ols = 'cumgpa ~ sat + hsperc + tothrs + female + black + white'
mod_ols = ols(form_ols, data=gpa3)
res_ols = mod_ols.fit()
print(res_ols.summary().tables[1])

稳健标准误估计:
res_robust = res_ols.get_robustcov_results(cov_type='HC3', use_t=True)
print(res_robust.summary().tables[1])
 这样编码也是可以的:
这样编码也是可以的:
res_HC3 = ols(form_ols, data=gpa3).fit(cov_type='HC3', use_t=True)
print(res_HC3.summary().tables[1])
2. Newey-West标准误
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9],
'b':[3,5,6,2,4,6,7,8,7,8,9]})
reg = smf.ols('a ~ 1 + b',data=df).fit(cov_type='HAC',cov_kwds={'maxlags':1})
print( reg.summary() )
或者这样写代码:
reg = smf.ols('a ~ 1 + b',data=df).fit()
new = reg.get_robustcov_results(cov_type='HAC',maxlags=1)
print(new.summary())

import pandas as pd
import statsmodels.formula.api as sm
import statsmodels.stats.sandwich_covariance as sw
import numpy as np
import statsmodels as statsmodels
from linearmodels import PanelOLS, FamaMacBeth
df = pd.read_table('http://www.kellogg.northwestern.edu/faculty/petersen/htm/papers/se/test_data.txt',
names=['firmid','year','x','y'],
delim_whitespace=True)
# Note: this adjustment doesn't really make sense for our sample dataset, it's just an illustration.
nw_ols = sm.ols(formula='y ~ x', data=df).fit(cov_type='HAC',
cov_kwds={'maxlags': 3},
use_t=True)
nw_ols.summary()
3. 一维聚类调整标准误
使用聚类方法调整标准误时,放宽了随机误差项「独立同分布」的假定,要点如下:
- 允许组内个体的干扰项之间存在相关性;
- 不同组之间个体的干扰项之间彼此不相关;
- 系数估计值仍然采用 OLS 估计值,因为它是无偏的。这里是引用
import pandas as pd
import statsmodels.formula.api as sm
import statsmodels.stats.sandwich_covariance as sw
import numpy as np
import statsmodels as statsmodels
from linearmodels import PanelOLS, FamaMacBeth
df = pd.read_table('http://www.kellogg.northwestern.edu/faculty/petersen/htm/papers/se/test_data.txt',
names=['firmid','year','x','y'],
delim_whitespace=True)
OLS Coefficients and Standard Errors Clustered by Firm or Year
cluster_firm_ols = sm.ols(formula='y ~ x', data=df).fit(cov_type='cluster',
cov_kwds={'groups': df['firmid']},use_t=True)
cluster_firm_ols.summary()
cluster_year_ols = sm.ols(formula='y ~ x', data=df).fit(cov_type='cluster',cov_kwds={'groups': df['year']},use_t=True)
cluster_year_ols.summary()

4. 二维聚类调整
OLS Coefficients and Standard Errors Clustered by Firm and Year
cluster_2ways_ols = sm.ols(formula='y ~ x', data=df).fit(cov_type='cluster',
cov_kwds={'groups': np.array(df[['firmid', 'year']])},
use_t=True)
cluster_2ways_ols.summary()

5. firm 或者 year 的固定效应来调整标准误
在做实证的时候,我们常常在模型中加入如公司、家庭、行业等虚拟变量,其实与中外论文中所说的 公司固定效应、家庭固定效应、行业固定效应是一个意思。
(1)个体固定效应模型:个体固定效应模型是对于不同的时间序列(个体)只有截距项不同的模型;
(2)时点固定效应模型:时点固定效应模型就是对于不同的截面(时点)有不同截距的模型。如果确知对于不同的截面,模型的截距显著不同,但是对于不同的时间序列(个体)截距是相同的,那么应该建立时点固定效应摸型;
(3)时点个体固定效应模型:时点个体固定效应模型就是对于不同的截面(时点)、不同的时间序列(个体)都有不同截距的模型。如果确知对于不同的截面、不同的时间序列(个体)模型的截距都显著不相同,那么应该建立时点个体固定效应模型。
1.firm的固定效应(如果不加EntityEffects、TimeEffects,即变为OLS估计了 )
# linearmodels needs the index to be entity/date.
df2 = df.set_index(['firmid', 'year'])
firm_fe_panel = PanelOLS.from_formula('y ~ x + EntityEffects', data=df2).fit()
firm_fe_panel.summary
或者这样写:
firm_fe_ols = sm.ols(formula='y ~ x + C(firmid)', data=df).fit(use_t=True)
firm_fe_ols.summary()
# The summary is ommitted because the large number
# of dummy variables make it unpleasant to look at.
2.year的固定效应
year_fe_panel = PanelOLS.from_formula('y ~ x + TimeEffects', data=df2).fit()
year_fe_panel.summary
或者这样写:
year_fe_ols = sm.ols(formula='y ~ x + C(year)', data=df).fit(use_t=True)
year_fe_ols.summary()
3. firm+year的固定效应
firm_year_fe_panel = PanelOLS.from_formula('y ~ x + EntityEffects + TimeEffects', data=df2).fit()
firm_year_fe_panel.summary
或者:
firm_year_fe_ols = sm.ols(formula='y ~ x + C(firmid) + C(year)', data=df).fit(use_t=True)
#firm_year_fe_ols.summary()
# The summary is ommitted because the large number
# of dummy variables make it unpleasant to look at.
6. firm或者year固定效应+ 聚类 来调整标准误
With linearmodels:
firm_year_fe_panel = PanelOLS.from_formula('y ~ x + TimeEffects',
data=df2).fit(cov_type='clustered', cluster_entity=True, cluster_time=True)
firm_year_fe_panel.summary
With statsmodels:
firm_cluster_year_fe_ols = sm.ols(formula='y ~ x + C(year)', data=df).fit(cov_type='cluster',
cov_kwds={'groups': df['firmid']},
use_t=True)
firm_cluster_year_fe_ols.summary()
7. Fama-MacBeth方法 调整标准误
FamaMacBeth.from_formula('y ~ 1+x', data=df2).fit()
也可以结合 Newey-West 方法来估计:
FamaMacBeth.from_formula('y ~ 1 + x', data=df2).fit(cov_type='kernel',
kernel='bartlett',
bandwidth=3)
8. Driscoll-Kraay方法 调整标准误
dk_ols = sm.ols(formula='y ~ x', data=df).fit(cov_type='nw-groupsum',
cov_kwds={'time': np.array(df.year),
'groups': np.array(df.firmid),
'maxlags': 5},
use_t=True)
dk_ols.summary()

2. 经典的参数估计方法
比较普遍的参数估计方法:
1、普通最小二乘法(OLS):适用于满足经典假设条件的但方程模型;
2、加权最小二乘法(WLS):适合于异方差数据,加权的实质是用一个变量除以误差项,使得误差项的方差变为常数;
3、工具变量法(IV):适合解释变量为随机情况,及解释变量与误差项相关。此时思路是找一个与解释变量相关而与误差项不相关的变量,成为工具变量,用工具变量替代解释变量做回归。
4、两阶段最小二乘法(2SLS):适用于联立方程组模型恰好识别和过度识别情况,用所用的前定变量的线性组合作为每个内生变量的工具变量。具体操作时对某个方程,把里面的内生变量对所有前定变量回归,用得到的结果得到内生变量的估计值,然后用以替代原始的内生变量再进行一次回归。
5、最大似然估计(ML):对似然函数求最大值。
6、广义矩方法(GMM):
7、
8、
方法比较:
1. 矩估计(GMM)还是极大似然法(MLE) 原文地址
在经济学结构模型的实证中,许多情况下我们并不能可能简单用线性回归来估计问题。因为结构模型导出的最优化条件,大多数情况下是非线性的。这就导致了最小乘法大多数时候对于模型的估计恐怕会显得无能为力。
所以我们对于结构模型的估计最常见的两种方法可能就是矩估计和极大似然值估计这两种。虽然矩估计相对来说比较万能:我们只要可以通过结构模型模拟出数据,让模拟出数据的矩和真实数据的矩相拟合就可以。但是事实上在大多数情况下,我们既可以用矩估计来估计模型,也可以通过极大似然法来估计模型,比如说我们可以根据结构模型直接推导出看到某一个值的条件概率,从而去最大化样本整体概率发生的可能性。
那么问题就来了,当两种方法都可以使用的时候,到底是使用矩估计法好呢?还是使用极大似然估计法好?还真有人做过这样的研究,Fuhrer et al. (1995) 在他们的论文中对于矩估计方法和极大似然值方法在具体的实证操作中的表现做了详细的比较,并且总结了各自的优缺点。
对于极大似然法而言优点不言而喻:
因为渐近有效所以估计的结果更容易显著,当然这也和极大似然法通常伴随着很强的概率分布假设有关; 极大似然估计法对于参数和模型的标准化设定没有矩估计法这么敏感; 虽然是渐近分布,但是在相对较小的样本下,极大似然值法相比矩估计仍然更加有效,估计偏差也来得更小;
当然极大似然法的缺点也很明显:
一旦使用极大似然值法,数据的产生过程必须严格完整地被假定并且描述,这意味着估计者需要对数据的产生过程有着非常高的认知和了解,也意味着大多数情况下我们可能会作出许多错误的假设判断; 极大似然值法一般来说不太适用于包含理性预期的结构模型,因为这类模型中似然函数通常高度非线性化,这会使得模型的估计因为搜索全剧最优而变得极其困难复杂; 即使模型是线性的,极大似然函数因为其特性大多数情况下也是非线性的(比如说线性回归中的极大似然函数是一个和指数要有对数相关的函数)。正因为如此,如果模型本身不是线性的,那么极大似然法的估计就会变得愈加糟糕。
相比而言矩估计法的优势也很明显:
模型的参数更容易被识别,相比极大似然法。使用矩估计法在一般情况下只需要简单讨论识别条件就可以,只要每一个参数都能为其找到一个对应的矩条件模型一般就能被识别出来; 样本数量只要足够大,矩估计的优势也就越大,据估计在大样本下一致收敛更强,并且渐近正态分布; 矩估计对于模型基本什么没什么特别的假设,使用的时候也毋需假设数据中的某些未知项服从特定分布,这样会使得模型的解释性也来得更强。
矩估计的缺点是:
一般来说如果想要获得更显著的参数,矩估计因为依赖于更少的分布假设,估计出来的参数显著性要明显小于极大似然估计; 矩估计法对于参数和模型的标准化设定相对敏感; 在小样本下矩估计的表现几近崩溃……
2. GMM估计分析步骤及结果解读
原文地址
GMM估计是用于解决内生性问题的一种方法,除此之外还有TSLS两阶段最小二乘回归。
如果存在异方差则GMM的效率会优于TSLS,但通常情况下二者结论表现一致,很多时候研究者会认为数据或多或少存在异方差问题,因而可直接使用GMM估计。
内生变量是指与误差项相关的解释变量。对应还有一个术语叫‘外生变量’,其指与误差项不相关的解释变量。产生内生性的原因通常在三类,分别说明如下:

内生性问题的判断上,通常是使用Durbin-Wu-Hausman检验(SPSSAU在两阶段最小二乘回归结果中默认输出),当然很多时候会结合自身理论知识和直观专业性判断是否存在内生性问题。如果假定存在内生性问题时,直接使用两阶段最小二乘回归或者GMM估计即可。一般不建议完全依照检验进行判断是否存在内生性,结合检验和专业理论知识综合判断较为可取。
内生性问题的解决上,通常使用工具变量法,其基本思想在于选取这样一类变量(工具变量),它们的特征为:工具变量与内生变量有着相关(如果相关性很低则称为弱工具变量),但是工具变量与被解释变量基本没有相关关系。寻找适合的工具变量是一件困难的事情,解决内生性问题时,大量的工作用于寻找适合的工具变量。
关于引入工具变量的个数上,有如下说明:

过度识别和恰好识别是可以接受的,但不可识别这种情况无法进行建模,似想用一个工具变量去标识两个内生变量,这是不可以的。
工具变量引入时,有时还需要对工具变量外生性进行检验(过度识别检验),针对工具变量外生性检验上,SPSSAU提供Hansen J检验。特别提示,只有过度识别时才会输出此两个检验指标。
GMM估计类型参数说明如下:

3.
4. 经济
参考文献:
Stata:聚类调整后的标准误
Petersen的主页
Python处理标准误
日本神户大学的计量讲义