小白总结Transformer模型要点
文章目录
- 前言
- 一、模型架构
-
- 0.背景知识
- 1.整体架构
- 2.Embedding和位置编码
- 3.多头注意力机制
- 4.残差连接
- 5.LayerNorm
- 6.Decoder
- 二、疑问汇总
- 三、模型实现
-
- 1.实现思路
- 2.实现过程
- 四、延伸学习
- 总结
参考:
(1)Transformer代码(源码)从零解读(Pytorch版本):https://www.bilibili.com/video/BV1dR4y1E7aL
(2)Transformer原理及其PyTorch源码讲解:https://www.bilibili.com/video/BV1o44y1Y7cp
(3)Transformer模型六大细节难点的逐行实现:
https://www.bilibili.com/video/BV1cP4y1V7GFhttps://www.bilibili.com/video/BV1Qg411N74v
(4)Transformer模型总结及其loss代码实现:https://www.bilibili.com/video/BV1dh411s7FW
前言
本文主要总结了Transformer模型的要点,包含模型架构各部分组成和原理、常见问题汇总、模型具体实现和相关拓展学习。
一、模型架构
0.背景知识
seq2seq模型:
由Encoder和Decoder共同组成,之间由Attention机制来建立关联性。
可以分为3类:
-
CNN
-
权重共享(平移不变性、可并行计算)
-
滑动窗口(局部关联性建模)
-
对相对位置敏感、对绝对位置不敏感
-
-
RNN(依次有序递归建模)
-
对顺序敏感(当前的输入依赖于上一层的输出)
-
串行计算耗时
-
长程建模能力弱
-
单步计算复杂度不变,计算复杂度与序列长度呈线性关系
-
对相对位置和绝对位置都敏感
-
-
TRM
-
无局部假设(可并行计算,对相对位置不敏感)
-
无有序假设
需要增加位置编码来反映位置变化对特征的影响;
对绝对位置不敏感。
-
任意两字符均可建模
擅长长短程建模;
自注意力机制需要序列长度的平方级别复杂度。
-
1.整体架构

6个Encoder的结构相同,但不是完全相同,只是结构相同、参数不同,在训练时不是训练一个Encoder、再复制到6份,而是6个Encoder都独立训练,这与预训练模型ALBERT共享Transformer中的某些层的参数达到减少BERT参数量的目的是有所区别的;
6个Decoder的结构也相同,参数不同,与Encoder类似。
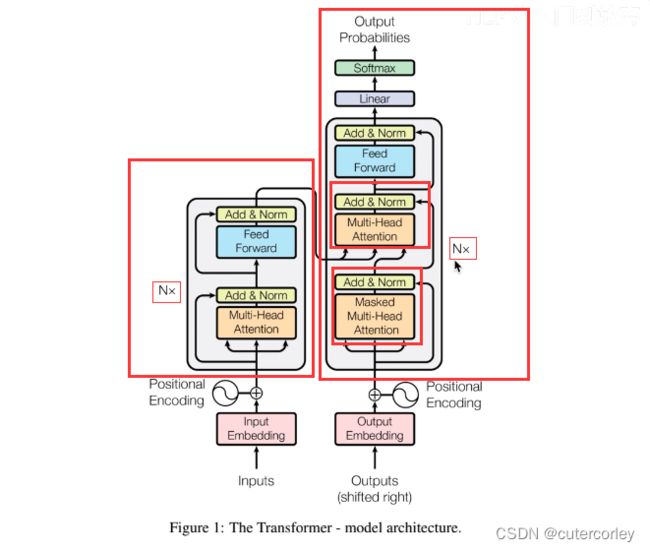
输入和输出的说明如下:
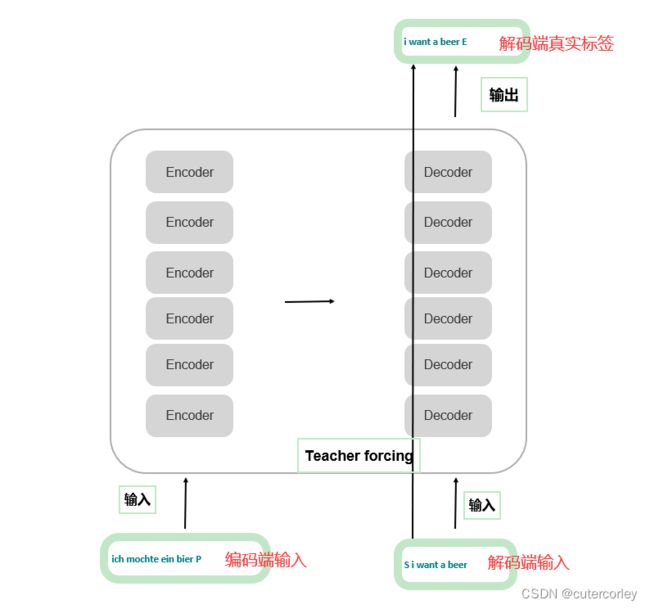
可以看到,有3个输入,解码端的真实标签,与解码端的输出计算损失,同时解码端是不能并行的,只能顺序执行,因为这一层解码器(当前时刻)的输入取决于(依赖于)上一层(上一时刻)的输出,因此真实标签与解码端的输入是错了一位的;
同时,在实际应用中,为了加快训练时的收敛速度,此时会使用到Teacher Forcing,即将真实标签与解码端原来的输入一起输入,为了不影响训练(即在训练当前单词时不看到后面的单词),此时就需要将当前单词后面的单词全部mask住,以达到更好的预测效果。更多关于Teacher Forcing,可以参考https://blog.csdn.net/qq_30219017/article/details/89090690。
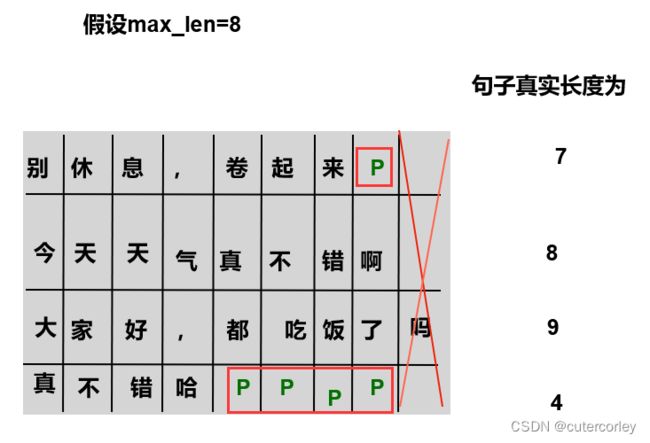
实际计算中是将多个句子作为一个Batch来处理的,可以使用矩阵来加快计算,但是句子的长度可能不一致,此时超过最大长度的就被舍弃,不够最大长度的就用Padding填充字符来填充,在注意力层中将其置为-∞,避免其对其他词产生影响:
2.Embedding和位置编码
Encoder包含3部分:
-
输入部分
-
注意力机制
-
前馈神经网络

输入部分包含Embedding和位置嵌入(位置编码)。
Embedding:

使用随机初始化和word2vec都可以,具体可以根据实际使用到的情况选择;
Embedding由稀琉的one-hot进入一个不带bias的FFN得到一个稠密的连续向量,用来表征单词。
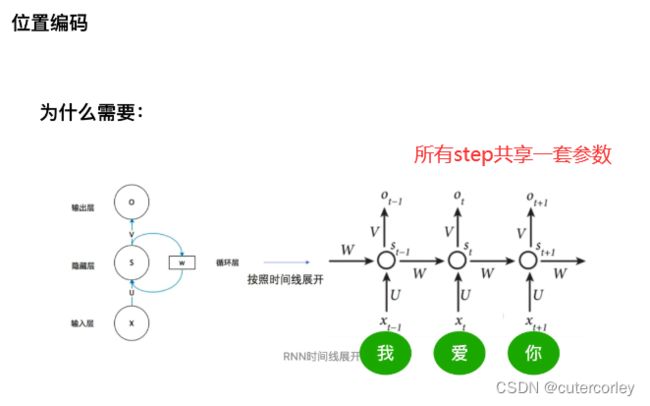
从RNN到位置编码:
RNN的结构天然与时序关系很符合,可以实现先处理某些数据、再处理另外的数据的效果。
(1)RNN的参数共享
RNN的U输入参数、W隐层参数和输出V是一套参数,对于所有的time step都共享一套参数,例如对于NLP任务来说,所有的单词都共用了这一套参数。
(2)RNN的梯度消失
不是因为连乘效应造成了梯度衰减,这里的梯度是梯度的和,其梯度消失不是指梯度逐渐趋近于0,而是总梯度被近距离梯度主导、被远距离梯度忽略不计。
更详细的关于RNN梯度消失的原因可参考https://blog.csdn.net/qq_28753373/article/details/103297994。
在TRM中:
实现了并行化,可以一起处理多个单词、而不是逐个地处理,这样可以加快处理速度,但是会忽略掉单词之间的相对位置信息,这时候就需要位置编码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wKGspfzc-1654266200425)(image/image_h8VM501H7C.png)]
之所以选择sin/cos来表征位置编码,是因为:
-
每个位置都是固定的
-
对于不同的句子,相同位置的距离一致
-
泛化能力较强,可以推广到更长的句子
通过使用sin/cos,可以使得pe(pos+k)可以写成pe(pos)和pe(k)的线性组合。
将位置编码和嵌入相加(维度相同):

绝对位置向量包含着相对位置信息:

原版的Transformer中因为线性变换,相对位置信息会在注意力机制中消失,具体解释可参考https://github.com/DA-southampton/NLP_ability/blob/master/深度学习自然语言处理/Transformer/原版Transformer的位置编码究竟有没有包含相对位置信息.md和《Transformer面试题答案解析》。
同时,虽然在注意力机制中会消除相对位置信息,但是由于残差连接的存在,因此位置编码表征的位置信息可以向更高的层传递(流入深层),因此位置信息是一直存在的,不会消失。
这里之所以选择正弦和余弦函数,是因为正余弦函数可以拆解,从而将以后时刻的位置表示为前面位置的线性组合,因此可以增加泛化能力。
具体实现位置编码时,有2种方式:
(1)将得到的PE矩阵直接与Word Embedding相加
(2)将得到的PE来构造Embedding,并对词语序列进行Embedding编码,得到位置的Embedding,再与Word Embedding相加。
3.多头注意力机制
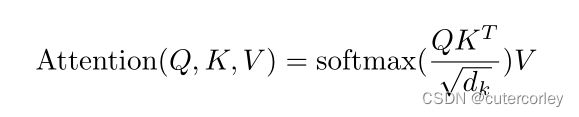
Q、K、V是相对矩阵,softmax得到了相似度,是一个向量,最后乘V得到加权和向量。
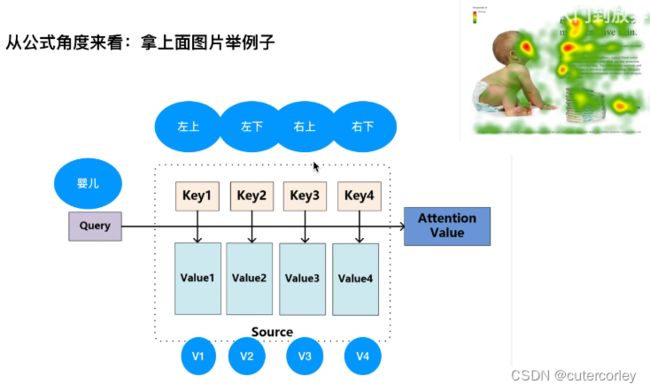

获取Q、K、V的方法:

在使用W参数时,每一个Head有一套W参数,所有的输入都是用这套参数,多个Head就有多套W参数,一般就是8套不同的W参数;多头使得建模能力更强,表征空间更丰富;多头可以类比于CNN中的多通道卷积,来探索不同空间中的信息。

之所以在Q*K时要除以dk的平方根,是为了防止Q*K很大时,softmax反向传播时梯度很小,容易造成梯度消失的情况,之所以除的值是dk的平方根,是为了保证方差为1。具体解释可参考https://www.zhihu.com/question/339723385/answer/782509914和《Transformer面试题答案解析》。
计算相似度有3种方式:
-
点乘
得到的是一个向量在另一个向量上的长度,是一个标量,反映两个向量之间的相似度,两个向量越相似,点乘的结果也越大
-
MLP(多层网络)
-
cosine相似性
实际操作中通过矩阵(多个单词的embedding)来实现并行:
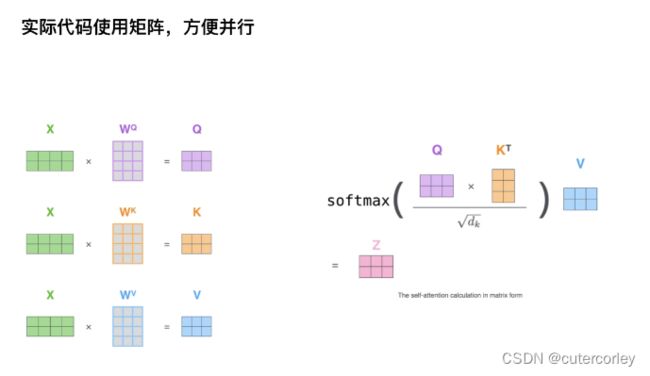
同时,在编码器端,Q、K、V是相同的,都是输入经过Embedding和位置编码得到的输出,即都是在EncoderLayer的输入;会使用线性Linear模型做映射,得到参数矩阵Wq、Wk、Wv。
在实际计算Q*K时,是相当于计算了一个句子中各个词之间的关联度,如下:
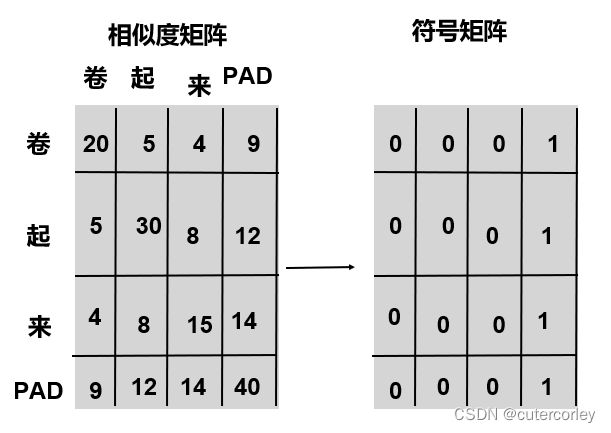
实际上,Q和K是两个相同的矩阵,左边极为Q与K的转置相乘的结果,可以看到,在计算一个词与句子中其他词的关联度时,也将Pad考虑了进来,但是实际上在进行softmax时不应该考虑Pad,此时就可以将Pad位置置为1,其他正常位置为0,以后在计算时就可以排除值为1的位置,消除pad带来的影响,具体就是使用了masked_fill_(mask, value)方法来实现用value填充tensor中与mask中值为1的位置相对应的元素,具体是将mask中为1的位置全部置为负无穷小、消除softmax时对其他词的影响。
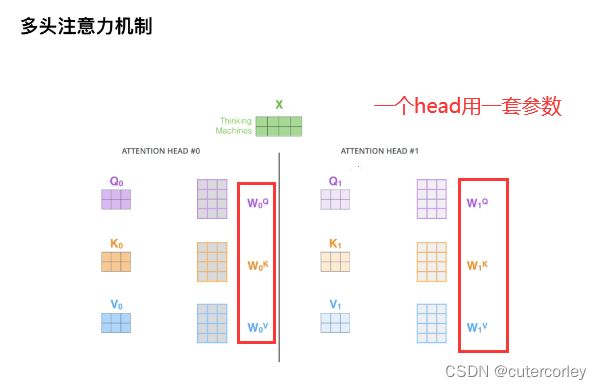
这样效果好的原因是相当于将原始信息达到了多个空间,保证了Transformer可以注意到不同子空间的信息,捕捉到更多的特征信息。同时,不同的Head使用不同的参数,但是输入(Q、K、V)都是Embedding和PE的和,最终每个Head单独计算得到一个Attention。
最后合并多个Head的输出(attention向量),并进入一个FNN得到最终的向量:

整个过程的维度变换可以参考http://t.zoukankan.com/lijianming180-p-12366528.html。
4.残差连接
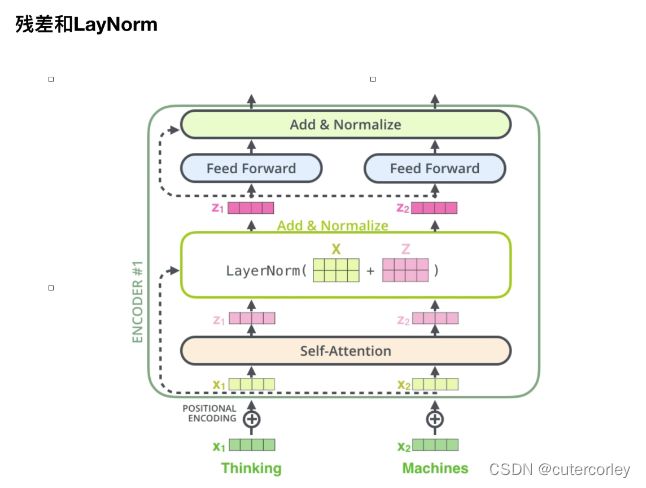
残差示意图如下:

链式求导如下:

梯度消失的原因一般是连乘造成的,但是从图中可以看到,因为前面加了1,即使连乘的数量再多、变为趋近于0,确保了红框中的值≥1,从而保证了梯度不会变为0,缓解了梯度消失的出发生,这也是在NLP任务中用到残差的网络可以使得网络很深的原因。
再想到RNN,一般很少有多个RNN叠在一起,一般就是单层RNN,或者双向LSTM,再复杂的就是ELMO(双层双向LSTM),训练已经很慢了,如果单纯用RNN想把模型做深难度很大。GNMT(谷歌神经机器翻译)更深,用了很多技巧加速训练。此时就可以用到残差,因为其可以缓解梯度消失,可以将模型做得更深。
阿里的RE2文本匹配模型使用了N-block的循环,用到了残差网络,因为block越多、模型越深,残差可以缓解梯度消失、保证模型可以做得更深,避免出现模型难以训练的情况。
关于RE2的更多信息,可参考https://zhuanlan.zhihu.com/p/78197267。
5.LayerNorm
在NLP中很少使用BN,基本都使用LN,因为BN的效果很差;
后续也有很多对BN的改进,以支持NLP任务。
特征缩放是为了消除量纲的影响,让模型收敛得更快。
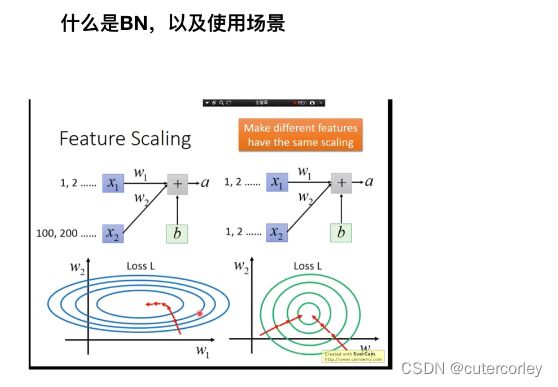
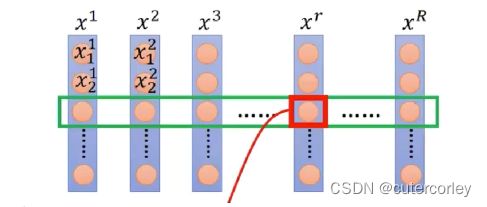
BN是对一个Batch中的多个样本的同一维度的数据进行归一化处理,可以看作一个Batch中的所有样本的同一个特征(例如人的身高、体重等多个维度分别进行BN)。
BN优点:
-
可以解决内部协变量偏移;
-
缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
BN的缺点:
-
batch_size较小的时候,效果差
BN的假设是使用一个Batch中样本的均值和方差来模拟全部数据的均值和方差,此时如果Batch的数量很少时,就会出现假设偏差较大的情况。
-
BN在RNN中效果比较差
这一点和第一点原因很类似。
因为RNN的输入是动态的,即数据的长度可能不一样,因此不能有效地得到整个Batch的均值和方差。
LN是对一个样本的所有特征进行缩放,例如对一个句子样本的所有单词做缩放。
为什么使用LN、不使用BN:

可以看到,相比于BN,LN在NLP任务中更有意义,例如我和今具有不同的语义信息,而LN是对一个句子进行缩放,一个句子的所有词存在于同一个语义信息中,这样可以得到更容易理解的语义。
前馈神经网络:

同时,FFN也是只考虑对单个位置进行建模,不同位置之间共享参数,类似于1*1的pointwise的CNN。
6.Decoder

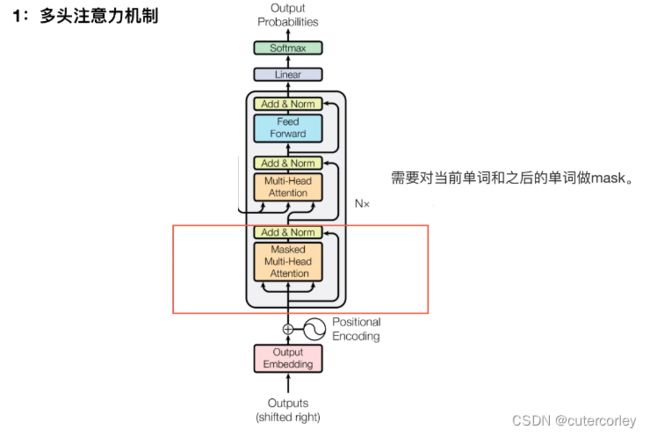
之所以要进行Mask遮挡:

没有遮挡
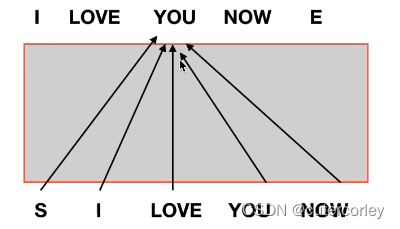
可以看到, 所有单词都会为You这个单词提供信息。
但是通过这样的方式训练出来的模型,在预测阶段会出现问题,比如预测阶段的当前单词为You,并不知道ground truth中You后面的信息(单词)什么(这也就是预测的出发点),看不见未来时刻的单词;因此如果在训练时不遮挡掉后面的单词,则模型在训练和测试时就会存在gap。
有遮挡

在训练和测试时都遮挡掉当前单词后面的单词,从而消除了训练和测试的gap,保证了一致性。
遮挡可以直观地理解为:在进行翻译时,遮挡掉后面的单词,让人来翻译得到后面位置的单词,也就是通过训练得到答案,而不是直接给出答案。
同时需要注意,在进行Mask时,有2个地方需要分别考虑:
(1)自注意力层Mask Multi-Head Attention,有2部分需要进行Mask,一部分是解码端输入的Padding的 Mask,另一部分是当前单词后面的单词进行Mask(上三角矩阵):
图示如下:

矩阵中,为1的位置是应该遮挡起来、看不到的。
(2)交互注意力层,只对编码端输出的Padding部分进行Mask:
Encoder的输入是K,将K中的Pad符号传给模型后面,同时忽略Decoder的Q中的Pad。
Encoder和Decoder之间的交互:

一个Encoder的输出与每一个Decoder进行交互:

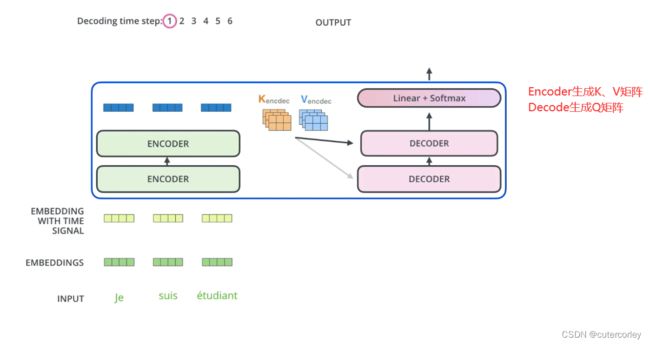
更细致的过程如下:
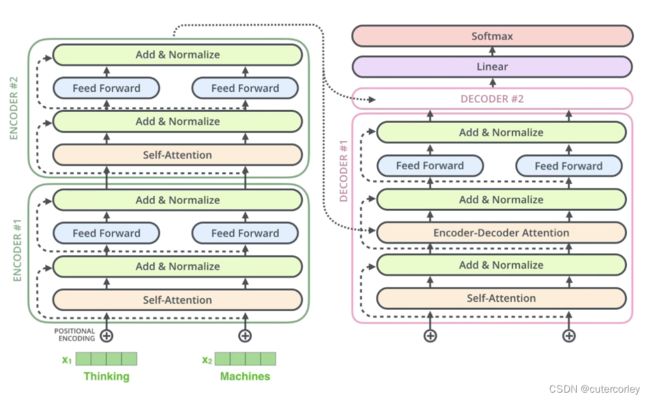
二、疑问汇总
翻译链接:https://www.yiyibooks.cn/yiyibooks/Attention_Is_All_You_Need/index.html
1.常见的attention计算方法

可以参考https://zhuanlan.zhihu.com/p/113120800。
2.为什么正弦曲线可以支持处理大于语料库中最长序列长度的序列?

3.序列转导模型是什么?

序列转导就是任何将输入序列转换为输出序列的任务,也就是常说的seq2seq,先行应用包括语音识别、文本转语音、机器翻译、蛋白质二级结构预测。更多可参考https://www.isi.edu/~tg/posts/2021/05/nmt-generalization-n-challenges/和https://www.cs.toronto.edu/~graves/seq_trans_slides.pdf。
4.3个评价指标的理解?

对Transformer的深入理解和优化可参考https://zhuanlan.zhihu.com/p/380489239。
5.

三、模型实现
1.实现思路
-
由整体到局部
-
理解数据的流动形状
上一个部分的输出是下一个部分的输入,数据的大小、形状和维度。
2.实现过程
参考:
https://nlp.seas.harvard.edu/2018/04/03/attention.htmlhttps://jozeelin.github.io/2019/10/21/The-Annotated-Transformer-Harvard/
2.Generator:
代码如下:
class Generator(nn.Module):
'''
定义标准线性+softmax生成步骤
'''
def __init__(self, d_model, vocab):
super().__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
log_softmax(self.proj(x), dim=-1)中,dim为-1与列表类似,表示最后一个维度,例如tensor的维度为torch.Size([2, 3, 4, 5])时,经过dim为-1时,输出的结果变为torch.Size([2, 3, 4])维度。
更多可参考https://blog.csdn.net/twelve13/article/details/109552544。
3.LayerNorm
代码如下:
class LayerNorm(nn.Module):
'''构建一个LayerForm模块'''
def __init__(self, features, eps=1e-6):
super().__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
x.mean(-1, keepdim=True)中,keepdim=True表示要计算的维度保留,只不过这个维度的长度变为1,这里就是最后一个维度保留且为1,如果为keepdim=False(默认值),则表示去掉该维度。具体可参考https://blog.csdn.net/qq_36810398/article/details/104845401。
n.train
在训练时会报错,如下:
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\modules\module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\modules\sparse.py", line 158, in forward
return F.embedding(
File "E:\Anaconda3\envs\pytorchbase\Lib\site-packages\torch\nn\functional.py", line 2044, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
这是因为num_embeddings(词典的词个数)不够大,进行词嵌入的时候字典从1, …, n,映射所有的词(或者字)num_embeddings =n是够用的,但是会考虑pad,pad默认一般是0,所以我们会重新处理一下映射字典0, 1, 2, …, n一共n+1个值,此时num_embeddings=n+1才够映射。更具体的说明和示例可参考https://blog.csdn.net/weixin_42912710/article/details/114479862。
四、延伸学习
1.残差连接
https://zhuanlan.zhihu.com/p/42706477。
2.KL散度
KL散度,即相对熵或信息散度,是两个概率分布间差异的非对称性度量 。在信息论中,相对熵等价于两个概率分布的信息熵的差值,若其中一个概率分布为真实分布,另一个为理论(拟合)分布,则此时相对熵等于交叉熵与真实分布的信息熵之差,表示使用理论分布拟合真实分布时产生的信息损耗。公式为 D K L ( p ∥ q ) = ∑ i = 1 N [ p ( x i ) log p ( x i ) − p ( x i ) log q ( x i ) ] D_{K L}(p \| q)=\sum_{i=1}^{N}\left[p\left(x_{i}\right) \log p\left(x_{i}\right)-p\left(x_{i}\right) \log q\left(x_{i}\right)\right] DKL(p∥q)=∑i=1N[p(xi)logp(xi)−p(xi)logq(xi)]。更多可参考https://blog.csdn.net/weixinhum/article/details/85064685。
3.contiguous
contiguous方法用来保证Tensor在内存中的保存是连续的,如果Tensor不是连续的,则会重新开辟一块内存空间保证数据是在内存中是连续的,如果Tensor是连续的,则contiguous无操作。更多可参考https://zhuanlan.zhihu.com/p/64551412。
总结
Transformer模型是Seq2Seq类模型中一个跨时代的模型,是NLP经典之作,使用自注意力的机制代替了以前的LSTM,从而实现了效果和效率上的提升,并为后来的Bert等众多预训练模型奠定了基础,同时后来也逐渐在CV等众多领域大展拳脚,地位十分重要。