LSTM预测实例(数据集展示)
数据集展示
# load and plot dataset
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
# 加载数据
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
# 显示开头部分行
print(series.head())
#head( )函数表示只能读取前五行数据
画图
series.plot()
pyplot.show()
**运行结果:**

# 代码讲解
将数据集下载到名为“ shampoo-sales.csv ”的当前工作目录中 ”。
```bash
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
下面是对pandas的read_csv方法的讲解
header:设置导入 DataFrame 的列名称,默认为 “infer”,他与names 参数有着微妙的关系。
names:当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
下面直接上图解释:
1,两个都没有被赋值的时候:pd.read_csv('girl.csv',delim_whitespace=True)

2,header 赋值:
# 不指定names,指定header为1,则选取第二行当做表头,第二行下面为数据
pd.read_csv('girl.csv',delim_whitespace=True, header=1)

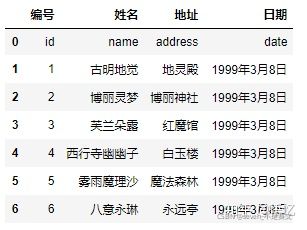
3,names 被赋值,header 没有被赋值:
pd.read_csv('girl.csv', delim_whitespace=True, names=["编号", "姓名", "地址", "日期"])
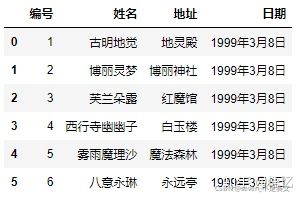
4,names和header都被赋值:(相当于先不看names,只看header,最后再换表头)
pd.read_csv('girl.csv', delim_whitespace=True, names=["编号", "姓名", "地址", "日期"], header=0)
# header为0代表先把第一行当做表头,下面的当成数据;然后再把表头用names给替换掉。
时间处理相关参数
parse_dates(将csv中的时间字符串转换成日期格式):指定某些列为时间类型,这个参数一般搭配date_parser使用

import pandas as pd
df=pd.read_csv('./TestTime.csv',parse_dates=[['time','date']])
#指定parse_dates = [ ['time', 'date'] ],即将[ ['time', 'date'] ]两列的字符串先合并后解析方可。合并后的新列会以下划线'_'连接原列名命名
print(df)
'''
结果:
time_date name
0 2019-10-10 21:33:30 'Bob'
1 2019-10-10 21:30:15 'Jerry'
2 2019-10-10 21:25:30 'Tom'
3 2019-10-10 21:20:10 'Vince'
4 2019-10-10 21:40:15 'Hank'
'''
这种书写时: parse_dates=['time','date']
# pd.read_csv()会分别对'time', 'date'进行字符串转日期,此外还会造成一个小小的麻烦。由于本例中的Time时间列格式为'HH:MM:SS',
parse_dates默认调用dateutil.parser.parse解析为Datetime格式,在解析time这一列时,会自作主张在前面加上一个当前日期。
'''
结果:
name time date
0 'Bob' 2019-10-17 21:33:30 2019-10-10
1 'Jerry' 2019-10-17 21:30:15 2019-10-10
2 'Tom' 2019-10-17 21:25:30 2019-10-10
3 'Vince' 2019-10-17 21:20:10 2019-10-10
4 'Hank' 2019-10-17 21:40:15 2019-10-10
"""
parse_dates=[0,1,2,3,4] : 尝试解析0,1,2,3,4列为时间格式;
parse_dates=[0] :解析第0列的值作为独立的日期列
date_parse :
特定格式读取日期或时间
![]()
要按指定格式读取日期,需要①将日期列设为索引,index_col=0;②指定parse_dates=True,即按指定格式解析索引列日期;③指定目标格式,即date_parser=parser,这里parser是我提前指定的目标格式。

index_col = None,0,False的区别这个图很通俗易懂
import io
import pandas as pd
t="""index,a,b
hi,hello,pandas,""" #故意在pandas后面多打了一个“,”
df = pd.read_csv(io.StringIO(t),index_col = 0)
print(df)
df = pd.read_csv(io.StringIO(t),index_col = False)
print(df)
df = pd.read_csv(io.StringIO(t),index_col = None)
print(df)
输出结果:
index a b
hi hello pandas NaN
index a b
0 hi hello pandas
index a b
hi hello pandas NaN
如果index_col是None或者0,他们输出时候都会多了个NaN,而且都将第一列作为行号。
而False不会用第一列作为行号,同时还会丢弃最后一列错误的值。
额外知识:
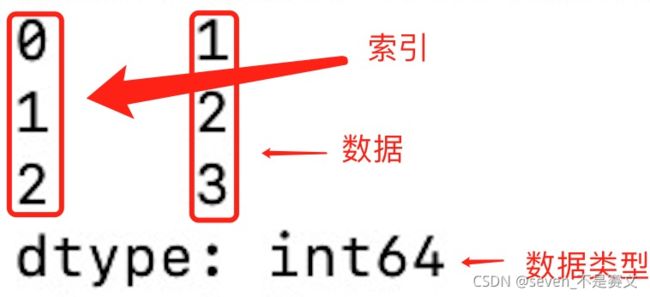
# Pandas 数据结构 - Series
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
sep:读取csv文件时指定的分隔符,默认为逗号。注意:"csv文件的分隔符" 和 "我们读取csv文件时指定的分隔符" 一定要一致。
原本的csv数据集:(连在一起了)
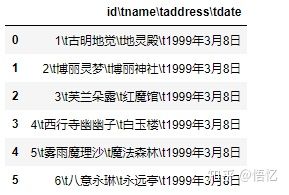
pd.read_csv('girl.csv', sep='\t') #结果如下图
这是知乎的超级详细的解释