xgboost回归预测模型_XGBoost模型(3)--球员身价预测
任务类型:回归
背景介绍: 每个足球运动员在转会市场都有各自的价码。本次数据练习的目的是根据球员的各项信息和能力值来预测该球员的市场价值。
数据来源:数据竞赛:足球运动员身价估计-SofaSofa

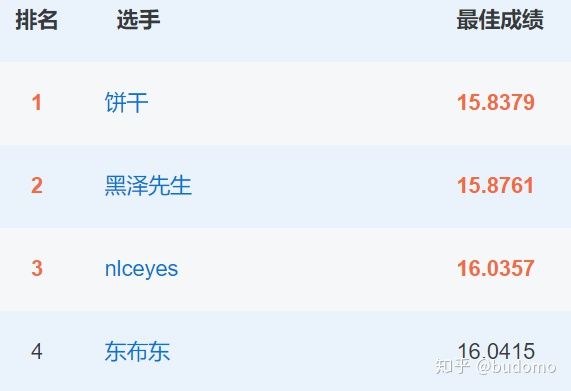
目前竞赛的排行榜如下:
(一)初始的XGBoost模型
属性非常多,初始的XGBoost模型选用4个属性
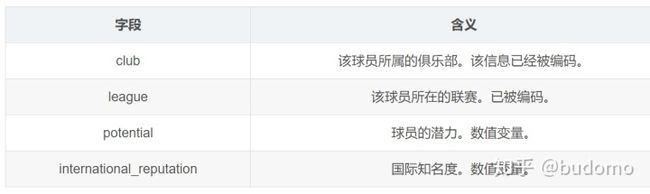
巧合的是刚好这些字段都没有缺失值。不用预处理
代码:
# 球员身价预测
import pandas as pd
import matplotlib.pyplot as plt
import xgboost as xgb
import numpy as np
from xgboost import plot_importance
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
def loadDataset(filePath):
df = pd.read_csv(filepath_or_buffer=filePath)
return df
# 只选了了4个特征建立模型
def featureSet(data):
data_num = len(data)
XList = []
for row in range(0, data_num):
tmp_list = []
tmp_list.append(data.iloc[row]['club'])
tmp_list.append(data.iloc[row]['league'])
tmp_list.append(data.iloc[row]['potential'])
tmp_list.append(data.iloc[row]['international_reputation'])
XList.append(tmp_list)
yList = data.y.values
return np.array(XList), yList
def trainandTest_mae(X_train, y_train, X_test,y_test):
# XGBoost训练过程
model = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=False, objective='reg:gamma')
model.fit(X_train, y_train)
# 对测试集进行预测
ans = model.predict(X_test)
#误差mae
mae=mean_absolute_error(y_test, ans)
print("mae:",mae)
# 显示重要特征
plot_importance(model)
plt.show()
# 主程序代码:
trainFilePath = 'train.csv'
testFilePath = 'test.csv'
data = loadDataset(trainFilePath)
#获得数据集
X, y = featureSet(data)
#划分训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#训练和测试模型,并输出mae指标
trainandTest_mae(X_train, y_train, X_test, y_test)输出结果:
重要特征:

【小修改1】:增加年龄属性
def featureSet(data):
data_num = len(data)
XList = []
for row in range(0, data_num):
tmp_list = []
tmp_list.append(data.iloc[row]['club'])
tmp_list.append(data.iloc[row]['league'])
tmp_list.append(data.iloc[row]['potential'])
tmp_list.append(data.iloc[row]['international_reputation'])
#获得年龄
d=data.iloc[row]['birth_date']
s= d.split('/')
tmp_list.append(s[-1])
XList.append(tmp_list)
yList = data.y.values
return np.array(XList), yList输出结果: (达到288/361名)
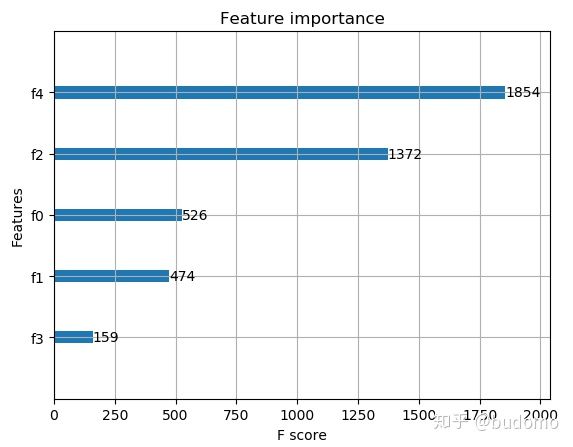
重要特征:(可见,F4年龄属性很重要)
(二)、增加特征工程
scikit中包含了一个特征选择的模块sklearn.feature_selection,而在这个模块下面有以下几个方法
- Removing features with low variance(剔除低方差的特征)
- Univariate feature selection(单变量特征选择)
- Recursive feature elimination(递归功能消除)
- Feature selection using SelectFromModel(使用SelectFromModel进行特征选择)
根据官方文档,有以下几种得分函数来检验变量之间的依赖程度:
- 对于回归问题: f_regression, mutual_info_regression
- 对于分类问题: chi2, f_classif, mutual_info_classif
由于这是一个回归预测问题,所以我选择了f_regression这个得分函数
f_regression的参数:
sklearn.feature_selection.f_regression(X, y, center=True)
X:一个多维数组,大小为(n_samples, n_features),即行数为训练样本的大小,列数为特征的个数
y:一个一维数组,长度为训练样本的大小
return:返回值为特征的F值以及p值【补充1】:关于F-score值和p-value值的定义:


【补充2】
不过在进行这个操作之前,我们还有一个重大的任务要完成,那就是对于空值的处理!幸运的是scikit中也有专门的模块可以处理这个问题:Imputation of missing values
sklearn.preprocessing.Imputer的参数:
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)其中strategy代表对于空值的填充策略(默认为mean,即取所在列的平均数进行填充):
- strategy=’median’,代表取所在列的中位数进行填充
- strategy=’most_frequent’, 代表取所在列的众数进行填充
axis默认值为0:
- axis=0,代表按列进行填充
- axis=1,代表按行进行填充
言归正传,考虑下面几个特征,选择其中重要特征

计算这些属性的F-score重要性值
import pandas as pd
from sklearn.feature_selection import f_regression
from sklearn.impute import SimpleImputer
import numpy as np
data = pd.read_csv('train.csv')
#进行缺失值的填充
X=data.loc[:, 'rw':'gk']
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
x_new = imputer.fit_transform(X) #结果为numpy类型
y_new=data.loc[:,'y'].values #结果为numpy类型
#求解特征的重要度F-score, 及对应的p_value
# 按F-score选择属性(>2000)
F_score, p_value = f_regression(x_new, y_new)
print(len(F_score))
print(F_score)11个属性的F-score值:
[2531.07587725 1166.63303449 2891.97789543 2531.07587725 2786.75491792
2891.62686404 3682.42649605 1394.46743195 531.08672792 1166.63303449
303.07144505]按照F-score>2000考虑,选择rw, st, lw, cf, cam, cm, cdm这7个特征,加入现有的5个特征中。
类似地,再加上下面几个特征:

代码:
import pandas as pd
import matplotlib.pyplot as plt
import xgboost as xgb
import numpy as np
from xgboost import plot_importance
from sklearn.impute import SimpleImputer
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
def loadDataset(filePath):
df = pd.read_csv(filepath_or_buffer=filePath)
return df
# 只选了了5个特征建立模型,包括年龄
def featureSet(data):
#进行缺失值的填充
X=data.loc[:, 'rw':'gk']
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
x_new = imputer.fit_transform(X) #结果为numpy类型
data_num = len(data)
XList = []
for row in range(0, data_num):
tmp_list = []
tmp_list.append(data.iloc[row]['club'])
tmp_list.append(data.iloc[row]['league'])
tmp_list.append(data.iloc[row]['potential'])
tmp_list.append(data.iloc[row]['international_reputation'])
#获得年龄
d=data.iloc[row]['birth_date']
s= d.split('/')
tmp_list.append(s[-1])
#特征选择增加的(可以通过特征选择添加)
tmp_list.append(data.iloc[row]['pac'])
tmp_list.append(data.iloc[row]['sho'])
tmp_list.append(data.iloc[row]['pas'])
tmp_list.append(data.iloc[row]['dri'])
tmp_list.append(data.iloc[row]['def'])
tmp_list.append(data.iloc[row]['phy'])
tmp_list.append(data.iloc[row]['skill_moves'])
#增加筛选的7个特征
tmp_list.append(x_new[row][0])
tmp_list.append(x_new[row][2])
tmp_list.append(x_new[row][3])
tmp_list.append(x_new[row][4])
tmp_list.append(x_new[row][5])
tmp_list.append(x_new[row][6])
tmp_list.append(x_new[row][7])
XList.append(tmp_list)
yList = data.y.values
return np.array(XList), yList
def trainandTest_mae(X_train, y_train, X_test,y_test):
# XGBoost训练过程
model = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=160, silent=False, objective='reg:gamma')
model.fit(X_train, y_train)
# 对测试集进行预测
ans = model.predict(X_test)
#误差mae
mae=mean_absolute_error(y_test, ans)
print("mae:",mae)
# 显示重要特征
plot_importance(model)
plt.show()
trainFilePath = 'train.csv'
testFilePath = 'test.csv'
data = loadDataset(trainFilePath)
#获得数据集
X, y = featureSet(data)
#划分训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#训练和测试模型,并输出mae指标
trainandTest_mae(X_train, y_train, X_test, y_test)
输出结果:(排名达到199/361)
输出特征重要度:

【结语】:还可以根据特征工程的方法,增加更多的特征。
参考文献:
Scikit中的特征选择,XGboost进行回归预测,模型优化的实战_人工智能_HuangQinJian-CSDN博客
2. 数据集:数据竞赛:足球运动员身价估计-SofaSofa