百行代码复现扩散模型-基于线性回归
文章目录
- 引言
- 简化模型
-
- 原本模型
- 模型改造
- 实现过程
-
- 数据集
- 文本编码
- 图像编码解码
- 扩散过程
- 训练过程
- 生成过程
- 完整实现
- 结论
引言
多模态的深度学习模型,通常需要大量的算力去训练和验证。 这导致缺乏算力的普通读者,阅读“大模型”论文,只能按论文作者所写来构造自己的认知。 可能对很多类似笔者的人来说:纸上得来终觉浅。
或许我们可以退而求其次,只选择 Follow 论文的思路。 本文以 Diffusion Model 为例,说明从核心思想来说, 也许简单的线性模型,就可以对这个模型做比较好的诠释。
本文使用简单的线性模型,简化原本的 Diffusion Model ,确切地说是:Latent Diffusion Model 。 简化的模型保留了原本模型的主体架构,可以在一台普通的笔记本电脑上, 只需要几秒就可以训练出一个“去噪模型”。
该模型使用 MNIST 数据集,语料库也只有10个元素,而且由于简化模型主体是线性模型,所以不能期待效果有多惊艳。 整体的复现代码不到100行。如果你的预期不高,那么它还是会超出你的预期。
简化模型
为了降低计算量,此处我们基于 LDM Latent Diffusion Model 进行 Follow , 也就是在特征空间进行扩散和生成,而非在原始的像素空间。
此处首先简单回顾下 LDM 的主体架构,然后给出本文的修改点。
原本模型
原本的 LDM 模型可以在 arxiv 中查到:Latent Diffusion Model , 此处我们复用论文中的模型架构图,
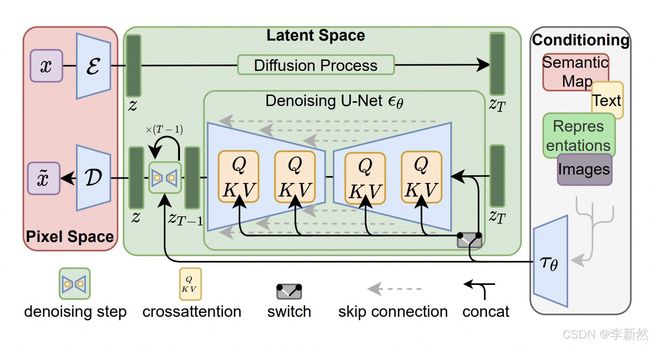
从图中可以看到,该模型有两个编码器和一个解码器,
- 图像编码器,将图片编码到特征向量,也就是图示的
Latent Space - 图像解码器,与图片编码器是配对儿的,通常是
VAE模型 - 文本编码器,将文本编码到特征向量,也就是图示的
Latent Space,可以使用LLM
模型包含两个过程,训练过程和生成过程。其中,训练过程,
- 首先图像编码器将原始图片编码到
Latent Space,也就是低维的向量 - 然后进行
Diffusion扩散过程,得到噪声图片,记录添加噪声的过程。此处是逐步扩散的。 - 文本编码器将“指导文本”编码到
Latent Space,也就是低维向量 - 训练去噪模型:文本向量和噪声图片向量拼接,做为输入特征;噪声做为目标向量。 训练出的去噪模型通常是类
U-Net架构的模型
模型的生成过程,
- 在特征空间
Latent Space生成噪声图片向量 - 文本编码器将“指导文本”编码到
Latent Space,也就是低维向量 - 将噪声图片向量和文本向量拼接,输入到已训练出的去噪模型
- 去噪模型生成预测的噪声向量。
- 原始输入的噪声图片向量,减去预测出的噪声向量,得出生成的图片向量
- 生成的图片向量经过图像解码器,解码为原始的图片
详细的过程可以参考一些博客文章,比如:An Introduction to Diffusion Models and Stable Diffusion 。 或者其它的一些图示,
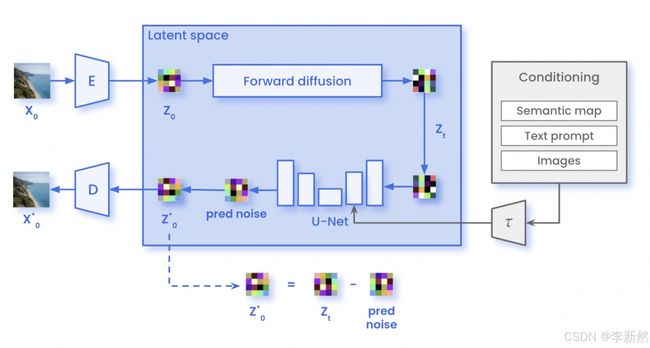
方便更好的理解,本文不再赘述。
模型改造
本文对原始论文的 LDM 模型改造如下,
- 对文本使用
OneHot独热编码器 - 对图片使用
PCA做编码器,解码使用反向PCA构造 - 扩散过程简化为单步,直接添加噪声
- 去噪模型简化为简单线性回归模型
- 添加模态交互部分,融和文本向量和图片向量
注意:模型融和部分是此处新增的。 原本的 LDM 模型,在训练去噪模型 U-Net 时,模型内部会做模态的融和。
实现过程
改造后的模型,实现过程相对比较简单。最终版本的实现不到100行代码。以下拆分来看下,
数据集
本文使用 MNIST 数据集,可以直接使用 pytorch 加载,
from torchvision import datasets
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import numpy as np
import torch
def plot_sample(d):
if not type(d) == type(torch.tensor([0])):
d = torch.tensor(d)
N, W, H = d.shape
imgs = d.reshape(N, 1, W, H)
img = make_grid(imgs, nrow=10)
plt.imshow(img[0], cmap='gray')
plt.axis('off')
plt.show()
return img
root = './torchdata/'
MNIST = datasets.MNIST(root, download=True, train=True)
X = MNIST.data[:100, :, :].numpy()
X = (X > 0) + 0
plot_sample(X)
简单绘制数据集中的图片如下,

注意,此处做了简单的二值化处理。
文本编码
由于数据集中只有10种类型的手写数字,那么驱动文本也只有10个文本。 本文使用 OneHot 独热编码,来编码文本向量。
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categories=[[str(i) for i in range(10)]], sparse_output=False)
enc.fit_transform([[str(i)] for i in range(10)])
编码结果如下,
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0