【机器学习实战】对加州住房价格数据集进行回归预测(线性回归、决策树、随机森林)
1. 使用交叉验证来验证线性回归
def display_scores(scores):
print("分数:", scores)
print("均值:", scores.mean())
print('标准差:', scores.std())
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10)
lin_scores
lin_rmse_scores = np.sqrt(-lin_scores)
lin_rmse_scores
display_scores(lin_rmse_scores)

2. 使用交叉验证来验证决策树
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring='neg_mean_squared_error', cv=10)
tree_rmse_scores = np.sqrt(-scores)
tree_rmse_scores
def display_scores(scores):
print("分数:", scores)
print("均值:", scores.mean())
print('标准差:', scores.std())
display_scores(tree_rmse_scores) # 决策树

- 根据均值可以看出,决策树确实过拟合了…效果要比线性模型还差。
3. 使用随机森林训练、交叉验证评估
3.1 训练并评估随机森林
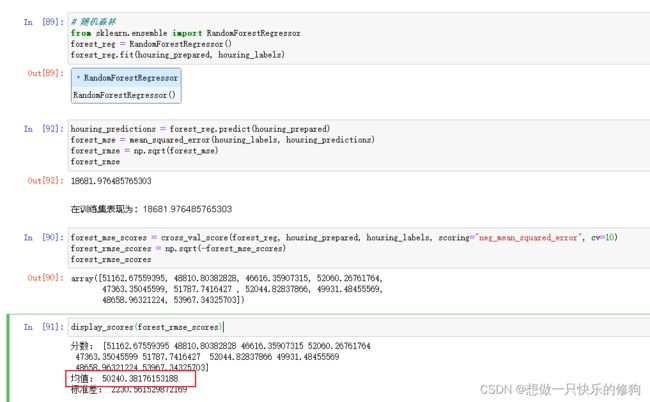
# 随机森林
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse
forest_mse_scores = cross_val_score(forest_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_mse_scores)
forest_rmse_scores
display_scores(forest_rmse_scores)
3.2 使用网格搜索进行参数调优
# 网格搜索
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators' : [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features':[2, 3, 4]}
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(housing_prepared, housing_labels)
grid_search.best_params_ # 最优参数组合
# 最好的估算器
grid_search.best_estimator_
# 评估分数
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
# 每个属性的相对重要程度(通过最佳模型)
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
# 将重要性分数与属性名称结合显示
extra_attribs = ["rooms_per_hold", "pop_per_hhold", "bedrooms_per_room"]
cat_one_hot_attribs = list(encoder.classes_)
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True) #从大到小



3.3 通过测试集评估系统
final_model = grid_search.best_estimator_
X_test = start_test_set.drop("median_house_value", axis=1)
y_test = start_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
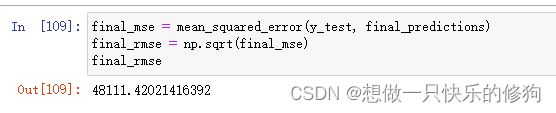
- 是比决策树、线性回归要好的。