华人一作统一「视觉-语言」理解与生成:一键生成图像标注,完成视觉问答,Demo可玩...

来源:机器学习研究组订阅
这个 BLIP 模型可以「看图说话」,提取图像的主要内容,不仅如此,它还能回答你提出的关于图像的问题。
视觉 - 语言预训练 (Vision-Language Pre-training,VLP) 提高了许多视觉 - 语言任务的性能。然而,大多数现有的预训练模型只能在基于理解任务或基于生成任务中表现出色。
现有的 VLP 方法主要存在两个局限性:
(1)从模型角度来讲,大多数方法采用基于编码器的模型,或者采用基于编码器 - 解码器模型。然而,基于编码器的模型很难直接转换到文本生成任务中,而编码器 - 解码器模型还没有成功地用于图像 - 文本检索任务;
(2)从数据角度来讲,像 CLIP、SimVLM 等 SOTA 模型通过在 web 上收集的图像 - 文本对进行预训练,尽管扩大数据集获得了性能提升,但 web 上的文本具有噪声,对 VLP 来说并不是最优。
近日,来自 Salesforce Research 的研究者提出了 BLIP(Bootstrapping Language-Image Pre-training),用于统一视觉 - 语言理解和生成任务。BLIP 是一个新的 VLP 框架,可以支持比现有方法更广泛的下游任务。BLIP 通过自展标注(bootstrapping the captions),可以有效地利用带有噪声的 web 数据,其中标注器(captioner)生成标注,过滤器(filter)去除有噪声的标注。
该研究在视觉 - 语言任务上取得了 SOTA 性能,例如在图像 - 文本检索任务上, recall@1 提高 2.7%;在图像标注任务上,CIDEr 提高 2.8%、VQA 提高 +1.6%。当将 BLIP 以零样本的方式直接迁移到视频 - 语言任务时,BLIP 也表现出很强的泛化能力。
论文一作为Salesforce亚洲研究院高级研究科学家Junnan Li,香港大学电子工程学士,新加坡国立大学计算机科学博士。他的主要研究兴趣在于自监督学习、半监督学习、弱监督学习、迁移学习以及视觉与语言。

论文地址:https://arxiv.org/pdf/2201.12086.pdf
代码地址:https://github.com/salesforce/BLIP
试玩地址:https://huggingface.co/spaces/akhaliq/BLIP
BLIP 的效果如何呢?用户只需上传一张图像,或单击内置示例加载图像就可完成。
BLIP 模型具有两个功能:图像标注和回答问题。这里,我们上传了猫咪和狗的图片:在图像标注这一功能下,模型输出「caption: a puppy and a kitten sitting in the grass(一只小狗和一只小猫坐在草地上)」(如下图红框所示)。
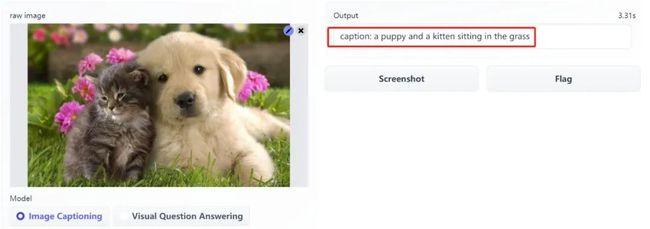
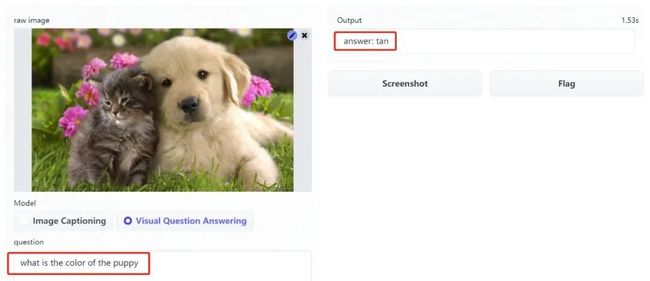
在回答问题功能下:当我们输入问题「what is the color of the puppy(小狗的颜色是什么)」,模型输出「tan(棕黄色)」。
上传著名油画《星夜》,在图像标注功能下模型输出「caption: a painting of a starry night over a city(一幅描绘城市星空的画)」。

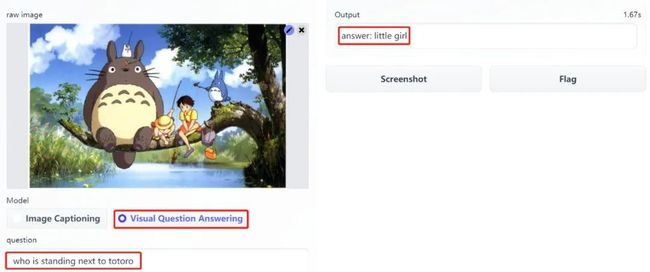
上传经典动画《龙猫》,向模型提问「who is standing next to totoro(谁坐在龙猫旁边)」,模型回答「little girl(小女孩)」。
架构 & 方法
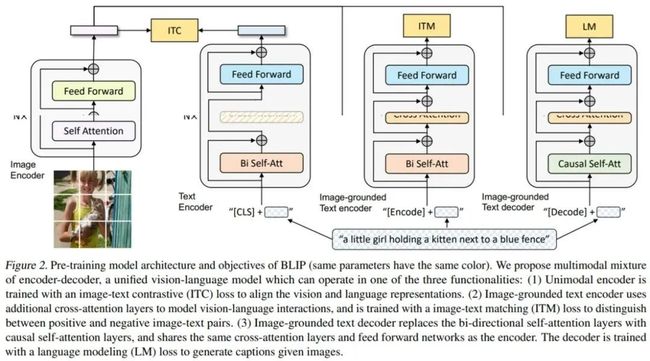
研究者提出的 BLIP 是一个统一的视觉语言预训练(vision-language pre-training, VLP)框架,从有噪声的图像文本对中学习。接下来详细解读模型架构 MED(mixture of encoder-decoder)、它的预训练目标以及用于数据集自展的方法 CapFilt。下图 2 为 BLIP 的预训练模型架构和目标。
动态运行示意图如下:
模型架构
研究者将一个视觉 transformer 用作图像编码器,该编码器将输入图像分解为 patch,然后将这些 patch 编码为序列嵌入,并使用一个额外的[CLS] token 表征全局图像特征。相较于将预训练目标检测器用于视觉特征提取的方法,使用 ViT 在计算上更友好,并且已被最近很多方法所采用。
为了预训练一个具备理解和生成能力的统一模型,研究者提出了多任务模型 MED(mixture of encoder-decoder),它可以执行以下三种功能的任意一种:
单峰编码器
基于图像的文本编码器
基于图像的文本解码器
预训练目标
研究者在预训练过程中共同优化了三个目标,分别是两个基于理解的目标和一个基于生成的目标。每个图像文本对只需要一个前向传播通过计算更重(computational-heavier)的视觉 transformer,需要三个前向传播通过文本 transformer,其中激活不同的功能以计算以下 3 个损失,分别是:
图像文本对比损失(image-text contrastive loss, ITC),激活单峰编码器,旨在通过鼓励正图像文本对(而非负对)具有相似的表征来对齐视觉与文本 transformer 的特征空间;
图像文本匹配损失(image-text matching loss, ITM),激活基于图像的文本编码器,旨在学习捕获视觉与语言之间细粒度对齐的图像文本多模态表征;
语言建模损失(language modeling loss, LM),激活基于图像的文本解码器,旨在给定一张图像时生成文本描述。
为了在利用多任务学习的同时实现高效的预训练,文本编码器和解码器必须共享除自注意力(self-attention, SA)层之外的所有参数。具体地,编码器使用双向自注意力为当前输入 token 构建表征,同时解码器使用因果自注意力预测接下来的 token。
另外,嵌入层、交叉注意力(cross attention, CA)层和 FFN 在编码和解码任务之间功能类似,因此共享这些层可以提升训练效率并能从多任务学习中获益。
CapFilt
研究者提出了一种提升文本语料库质量的新方法——CapFilt(Captioning and Filtering)。如下图 3 所示,CapFilt 引入了两个主要的模块:一个是为给定 web 图像生成标注的标注器(captioner),另一个是消除有噪声图像文本对的过滤器(filter)。这两个模块都源于同一个预训练 MED 模型,并各自在 COCO 数据集上微调。
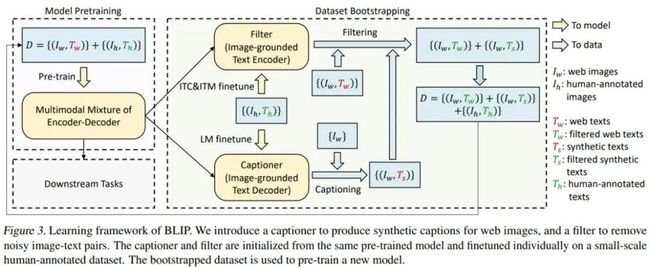
具体地,标注器是一个基于图像的文本解码器。它利用 LM 目标进行微调,以解码给定图像的文本。比如,给定 web 图像 I_w,则标注器生成标注 T_s,其中每张图像一个标注。
过滤器是一个基于图像的文本编码器。它利用 ITC 和 ITM 目标进行微调,以学习文本是否与图像匹配。过滤器消除原始 web 文本 T_w 和合成文本 T_s 中的噪声文本,其中如果 ITM 头(head)预测一个文本与图像不匹配,则该文本被认为有噪声。
最后,研究者将过滤后的图像文本对于人工注释对相结合以生成一个新的数据集,并用它预训练了新模型。
实验结果
研究者在 PyTorch 中实现模型,并在两个 16-GPU 节点上预训练模型。其中,图像 transformer 源于在 ImageNet 上预训练的 ViT,文本 transformer 源于 BERT_base。
CapFilt 的效果
下表 1 中,研究者比较了在不同数据集上预训练的模型,以验证 CapFilt 在下游任务(包括微调和零样本设置下的图像文本检索和图像标注)上的效用。

下图 4 中给出了一些标注示例以及对应的图像,从而在质量上验证了标注器有效地生成新的文本描述,过滤器有效地消除原始 web 文本和合成文本中的噪声标注。

合成标注的关键:多样性
在 CapFilt 方法中,研究者使用一种随机解码方法——核抽样(nucleus sampling)来生成合成标注。下表 2 中与束搜索(beam search)方法进行了比较,可以看到核抽样取得了更好的数据结果,尽管由于过滤器更高的噪声比导致了更大的噪声。

参数共享与解耦
在预训练中,文本编码器和解码器共享所有参数,除自注意力层外。表 3 评估了使用不同参数共享策略进行预训练的模型性能,其中预训练是在 14M 带有 web 文本的图像上进行的。
结果表明,除 SA 外,所有层具有参数共享优于那些没有进行参数共享的,同时也减少了模型的大小,从而提高了训练效率。

在 CapFilt 中,标注器和过滤器分别在 COCO 上进行了端到端的微调,表 4 研究了标注器和过滤器以共享参数的方式进行预训练的影响。
由于参数共享,标注器产生的噪声标注不会被过滤器过滤掉,这可以从较低的噪声比 (8% 比 25%) 看出。

与 SOTA 模型进行比较
该研究将 BLIP 与 VLP 模型在视觉 - 语言下游任务上进行了比较。如表 5 所示,与现有方法相比,BLIP 实现了性能改进。使用相同的 14M 预训练图像,BLIP 在 COCO 上的 recall@1 比之前的最佳模型 ALBEF 高 2.7%。

该研究还通过将在 COCO 上微调的模型直接迁移到 Flickr30K 来执行零样本检索。结果如表 6 所示,BLIP 也大大优于现有方法。

在图像标注任务上,该研究采用两个数据集:NoCaps 和 COCO,两者都使用在 COCO 上微调并具有 LM 损失的模型进行评估。如表 7 所示,使用 14M 预训练图像的 BLIP 显著优于使用相似数量的预训练数据的方法。使用 129M 图片的 BLIP 与使用 200M 图片的 LEMON 相比,具有相媲美性能。

视觉问答 (VQA) 要求模型在给定图像和问题的情况下预测答案。该研究没有将 VQA 制定为多答案分类任务,而是遵循 Li 等人研究将其视为一个答案生成任务,它支持开放式 VQA。
结果如表 8 所示,在测试集上,使用 14M 图像,BLIP 的性能比 ALBEF 高出 1.64%。使用 129M 图像,BLIP 比 SimVLM 获得了更好的性能,而 SimVLM 使用了 13 倍多的预训练数据和更大的视觉骨干,并附加了一个卷积阶段。

更多实验数据请参见原论文。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
