【MMDet Note】MMDetection中Backbone之ResNet代码理解与解读
文章目录
- 前言
- 一、总概
- 二、代码解读
-
- 1.self.forward方法
- 2.ResNet类与其__init__()
- 3.self._make_stem_layer方法
- 4.self.make_res_layer方法
-
- 4.1 ResLayer类
- 4.2 `__init__` 中 self.res_layers
- 总结
前言
mmdetection/mmdet/models/backbones/resnet.py中的ResNet类的个人理解与代码解读。
一、总概
本文以mmdetection/configs/base/models/faster_rcnn_r50_fpn.py中backbone的参数配置为例进行解读。
backbone=dict(
# ResNet-50
type='ResNet',
depth=50,
num_stages=4,
# 表示本模块输出的特征图索引,(0, 1, 2, 3),表示4个 stage 输出都需要,
# 其对应的 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
二、代码解读
1.self.forward方法
先不看ResNet类的__init__,先看forward方法,因为这个可以更直观的了解主干网络的大致结构与构造流程。
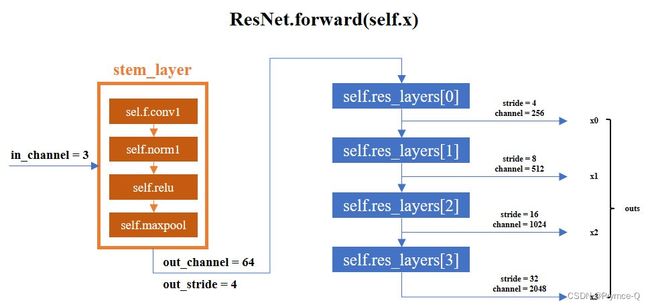
结构图如上所示,从左到右从上到下的顺序进行主干网络的构建,代码如下:
def forward(self, x):
"""Forward function."""
if self.deep_stem: # self.deep_stem = False
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
# 如果i在self.out_indices中才保留
if i in self.out_indices: # self.out_indices = (0,1,2,3)
outs.append(x)
return tuple(outs)
那么我们只需要弄清楚,在ResNet类中的__init__过程,self.conv1、self.norm1、self.relu、self.maxpool、self.res_layers这些是如何构建起来的。
2.ResNet类与其__init__()
__init__主要是对self的一些参数进行确认,排查是否冲突,最重要的就是上面所说的对self.conv1、self.norm1、self.relu、self.maxpool、self.res_layers的构造。我们还是以Faster RCNN中的backbone的参数配置为例。
@BACKBONES.register_module()
class ResNet(BaseModule):
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)), # ResNet-50
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
# BasicBlock,Bottleneck都是一个单独的类,可以理解成模块
def __init__(self,
# 网络深度
depth, # 50
# 输入图像的channel数
in_channels=3,
# 主干卷积层的channel数,默认等于base_channels
stem_channels=None,
base_channels=64,
# stage数量
num_stages=4,
# 每个stage第一个残差块的stride参数
strides=(1, 2, 2, 2),
# 膨胀(空洞)卷积参数设置
dilations=(1, 1, 1, 1),
# 输出特征图的索引,每个stage对应一个
# 其对应的 stride 为 (4,8,16,32),channel 为 (256, 512, 1024, 2048)
out_indices=(0, 1, 2, 3),
# 风格设置
style='pytorch',
# 是否用3个3×3的卷积核代替主干上1个7×7的卷积核
deep_stem=False,
# 是否使用平均池化代替stride为2的卷积操作进行下采样
avg_down=False,
# 冻结层数,-1表示不冻结
frozen_stages=-1, # 1
# 构建卷积层的配置
conv_cfg=None,
# 构建归一化层的配置
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
# 是否使用dcn(可变形卷积)
dcn=None,
# 指定哪个stage使用dcn
stage_with_dcn=(False, False, False, False),
plugins=None,
with_cp=False,
# 是否对残差块进行0初始化
zero_init_residual=True,
# 预训练模型(已弃用,若指定会自动调用init_cfg)
pretrained=None,
# 指定预训练模型
init_cfg=None): # init_cfg = dict(type='Pretrained', checkpoint='torchvision://resnet50')
super(ResNet, self).__init__(init_cfg)
self.zero_init_residual = zero_init_residual # self.zero_init_residual = True
# 判断是否有该depth设置下的模型, 如 depth=51 就会报错
if depth not in self.arch_settings:
raise KeyError(f'invalid depth {depth} for resnet')
block_init_cfg = None
# 下面进行预训练模型设定, pretained 已经弃用, 即 pretained=None
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be specified at the same time'
# 如果指定预训练模型,就会自动读取模型配置与参数
if isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
# 如果没有指定预训练模型(init_cfg is None)就会自动生成模型配置参数组装模型
elif pretrained is None: # 满足
if init_cfg is None: # 不满足
self.init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(
type='Constant',
val=1,
layer=['_BatchNorm', 'GroupNorm'])
]
block = self.arch_settings[depth][0]
if self.zero_init_residual:
if block is BasicBlock:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm2'))
elif block is Bottleneck:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm3'))
else:
raise TypeError('pretrained must be a str or None')
self.depth = depth # self.depth = 50
if stem_channels is None:
stem_channels = base_channels
self.stem_channels = stem_channels # self.stem_channels = 64
self.base_channels = base_channels # self.base_channels = 64
self.num_stages = num_stages # self.num_stages = 4
assert num_stages >= 1 and num_stages <= 4
self.strides = strides # self.strides = (1, 2, 2, 2)
self.dilations = dilations # self.dilations = (1, 1, 1, 1)
assert len(strides) == len(dilations) == num_stages
self.out_indices = out_indices # self.out_indice = (0, 1, 2, 3)
assert max(out_indices) < num_stages
self.style = style # self.style = 'pytorch'
self.deep_stem = deep_stem # self.deep_stem = False
self.avg_down = avg_down # self.avg_down = False
self.frozen_stages = frozen_stages # self.frozen_stages = 1
self.conv_cfg = conv_cfg # self.conv_cfg = None
self.norm_cfg = norm_cfg # self.norm_cfg = dict(type='BN', requires_grad=True)
self.with_cp = with_cp # self.with_cp = False
self.norm_eval = norm_eval # self.norm_eval = True
self.dcn = dcn # self.dcn = None
self.stage_with_dcn = stage_with_dcn # self.stage_with_dcn = (False, False, False, False)
if dcn is not None:
assert len(stage_with_dcn) == num_stages
self.plugins = plugins # self.plugins = None
self.block, stage_blocks = self.arch_settings[depth] # self.block, stage_blocks = Bottleneck, (3, 4, 6, 3)
self.stage_blocks = stage_blocks[:num_stages] # self.stage_blocks = stage_blocks[:4] = (3, 4, 6, 3)
self.inplanes = stem_channels # self.inplanes = 64
# 使用self._make_stem_layer方法构造stem_layer(下面一小节会有详细解释)
self._make_stem_layer(in_channels, stem_channels) # in_channels = 3, stem_channels = 64
# self.conv1 = Conv2d(in_c = 3, out_c = 64, kernel_size = 7, s = 2, p = 3)
# self.norm1_name, norm1
# self.relu = nn.ReLU(inplace=True)
# self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 该处输出特征图 channel = 64, stride = 4
# 下面使用self.make_stage_plugins构造res_layer(对于这个方法4.2节中会更加详细解释,这里只简单给出一些变量的具体值)
self.res_layers = []
for i, num_blocks in enumerate(self.stage_blocks): # self.stage_blocks = (3/ 4/ 6/ 3)
stride = strides[i] # self.strides = (1/ 2/ 2/ 2)
dilation = dilations[i] # self.dilations = (1/ 1/ 1/ 1)
dcn = self.dcn if self.stage_with_dcn[i] else None
if plugins is not None:
stage_plugins = self.make_stage_plugins(plugins, i)
else:
stage_plugins = None
planes = base_channels * 2**i # planes = [64/ 128/ 256/ 512]
res_layer = self.make_res_layer(
block=self.block, # self.block = Bottleneck
inplanes=self.inplanes,
planes=planes,
num_blocks=num_blocks,
stride=stride,
dilation=dilation,
style=self.style,
avg_down=self.avg_down,
with_cp=with_cp,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
dcn=dcn,
plugins=stage_plugins,
init_cfg=block_init_cfg)
self.inplanes = planes * self.block.expansion
layer_name = f'layer{i + 1}'
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
# 固定指定stage的权重
self._freeze_stages()
self.feat_dim = self.block.expansion * base_channels * 2**(
len(self.stage_blocks) - 1)
其中最为关键的就是self._make_stem_layer、self.make_res_layer方法,在下两小节中讲解。
3.self._make_stem_layer方法
def _make_stem_layer(self, in_channels, stem_channels): # in_channels = 3, stem_channels = 64
if self.deep_stem: # self.deep_stem = False 不满足
self.stem = nn.Sequential(
build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels // 2,
kernel_size=3,
stride=2,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels // 2,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels)[1],
nn.ReLU(inplace=True))
else:
# stem_layer构造如下:
# Conv2d(in_c = 3, out_c = 64, kenerl_size = 7, s = 2, p = 3)
self.conv1 = build_conv_layer(
self.conv_cfg, # None, 在build_conv_layer中会被给予Conv2d
in_channels, # 3
stem_channels, # 64
kernel_size=7,
stride=2,
padding=3,
bias=False)
# BN_norm层
self.norm1_name, norm1 = build_norm_layer(
self.norm_cfg, stem_channels, postfix=1) # self.norm_cfg = dict(type='BN', requires_grad=True), stem_channels = 64
self.add_module(self.norm1_name, norm1)
# 激活函数relu
self.relu = nn.ReLU(inplace=True)
# maxpool层
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
这样便得到了self.conv1、self.norm1、self.relu、self.maxpool的构造情况,且stem_layer的输出channel为64,stride为4。
而self.res_layers的构建过程将在下一小节的self.make_res_layer方法中进行讲解。
4.self.make_res_layer方法
它是通过mmdetection/mmdet/models/utils/res_layer.py中的ResLayer类构造而成的。
def make_res_layer(self, **kwargs):
"""Pack all blocks in a stage into a ``ResLayer``."""
return ResLayer(**kwargs)
那我们先看看ResLayer类的代码,之后再具体地分析__init__中self.res_layers是如何构建的~~
4.1 ResLayer类

class ResLayer(Sequential): # 先用第一次循环的值为例进行解释
def __init__(self,
block, # self.block = Bottleneck
inplanes, # self.inplanes = 64 以下是循环的所有可能情况
planes, # planes = 64 # planes = [64/ 128/ 256/ 512]
num_blocks, # num_blocks = 3 # self.stage_blocks = (3/ 4/ 6/ 3)
stride=1, # stride = 1 # self.strides = (1/ 2/ 2/ 2) 控制整体模块的stride
avg_down=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
downsample_first=True,
**kwargs):
self.block = block
downsample = None
if stride != 1 or inplanes != planes * block.expansion: # 满足
downsample = []
conv_stride = stride
if avg_down: # 不满足
conv_stride = 1
downsample.append(
nn.AvgPool2d(
kernel_size=stride,
stride=stride,
ceil_mode=True,
count_include_pad=False))
downsample.extend([
build_conv_layer(
conv_cfg, # None,就是conv2d
inplanes, # 64
planes * block.expansion, # 256
kernel_size=1,
stride=conv_stride, # 1
bias=False),
build_norm_layer(norm_cfg, planes * block.expansion)[1]
])
downsample = nn.Sequential(*downsample)
# downsample 构建了一个下采样且提高channel数量的Conv2d模块,该downsample 在构建具体的Bottleneck模块时候会被使用到。
layers = []
if downsample_first: # 满足
layers.append(
block( # Bottleneck
inplanes=inplanes, # 64 输入channel = 64
planes=planes, # 64 输出channel = planes * Bottleneck.expansion = 64*4 = 256
stride=stride, # 1
downsample=downsample, # Conv2d(in_c = 64, out_c = 256, stride = 1, kernel_size = 1)
conv_cfg=conv_cfg, # None
norm_cfg=norm_cfg, # dict(type='BN')
**kwargs))
inplanes = planes * block.expansion # inplanes = 64 *4 = 256
for _ in range(1, num_blocks): # num_blocks = 3
layers.append(
block( # Bottleneck
inplanes=inplanes, # 输入channel = 256
planes=planes, # 输出channel = planes * Bottleneck.expansion = 64*4 = 256
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
**kwargs))
else: # downsample_first=False is for HourglassModule
... # 略
看到这里说一句,Bottleneck的代码不讲啦~~比较短自己看看就好了。个人觉得最重要的是先知道Bottleneck类的输入输出size是怎么样的,上面代码注释里有写。
4.2 __init__ 中 self.res_layers
看完了ResLayer类的代码,我们再回过来看self.__init__ ()中构造self.res_layers的那一块代码。
# 摘自第2节中的self.__init__ ()
self.res_layers = []
for i, num_blocks in enumerate(self.stage_blocks): # self.stage_blocks = (3/ 4/ 6/ 3)
stride = strides[i] # self.strides = (1/ 2/ 2/ 2)
dilation = dilations[i] # self.dilations = (1/ 1/ 1/ 1)
dcn = self.dcn if self.stage_with_dcn[i] else None
if plugins is not None:
stage_plugins = self.make_stage_plugins(plugins, i)
else:
stage_plugins = None
planes = base_channels * 2**i # planes = [64/ 128/ 256/ 512]
res_layer = self.make_res_layer(
# xxx变量表示xxx类中用到了该行变量
block=self.block, # ResLayer变量 self.block = Bottleneck
inplanes=self.inplanes, # ResLayer变量&Bottleneck变量
planes=planes, # ResLayer变量&Bottleneck变量 planes = [64/ 128/ 256/ 512]
num_blocks=num_blocks, # ResLayer变量 self.stage_blocks = (3/ 4/ 6/ 3)
stride=stride, # ResLayer变量&Bottleneck变量 self.strides = (1/ 2/ 2/ 2)
dilation=dilation, # ResLayer变量&Bottleneck变量 self.dilations = (1/ 1/ 1/ 1)
style=self.style, # Bottleneck变量self.style = 'pytorch'
avg_down=self.avg_down, # ResLayer变量 False
with_cp=with_cp, # Bottleneck变量 False
conv_cfg=conv_cfg, # ResLayer变量&Bottleneck变量 None
norm_cfg=norm_cfg, # ResLayer变量&Bottleneck变量 dict(type='BN', requires_grad=True)
dcn=dcn, # Bottleneck变量 None
plugins=stage_plugins, # Bottleneck变量 None
init_cfg=block_init_cfg) # Bottleneck变量 None
self.inplanes = planes * self.block.expansion # Bottleneck.expansion = 4 self.inplanes = [256, 512, 1024, 2048]
layer_name = f'layer{i + 1}' # layer_name = ['layer1', 'layer2', 'layer3', 'layer4']
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
最终ResNet的reslayer如下图中的蓝色矩形。
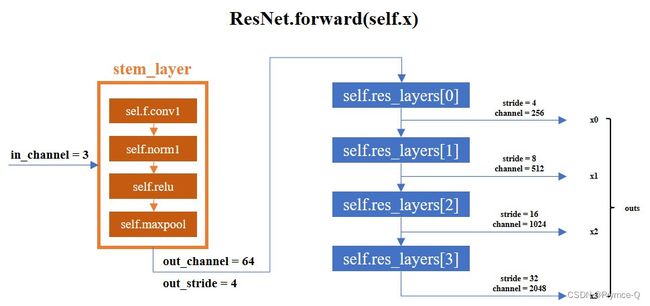
(个人能力有限,一次性逻辑并不能说的十分周全,如果有哪些地方联系不起来或者缺失的,还请大家在评论区指出,我会后期再加上去)
总结
本文仅代表个人理解,若有不足,欢迎批评指正。
参考:
轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解