【MMDet Note】MMDetection中Head之RetinaHead代码理解与解读
文章目录
- 前言
- 一、RetinaNet的Head结构
- 二、RetinaHead代码解读
-
- 1.总概
- 2.def `__init__()`
- 3.def _init_layers(self)
- 4.def forward_single(self, x)
- 总结
前言
RetinaHead类 继承了 AnchorHead类(mmdetection/mmdet/models/dense_heads/retina_head.py)
本来想先读一读AnchorHead类的,但感觉一开始就读父类太过空洞,所以从具体的RetinaHead入手。
本文就简单对mmdetection/mmdet/models/dense_heads/retina_head.py中的RetinaHead类代码解读下。
一、RetinaNet的Head结构
下图来自RetinaNet论文。论文链接。
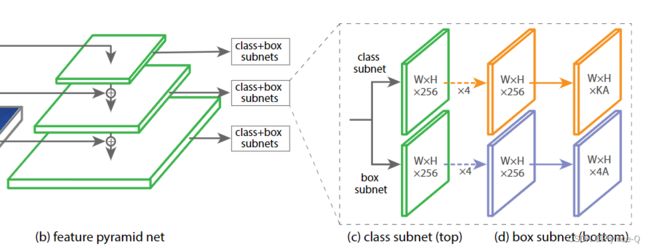
FPN的每一个stage都会连接一个输出头,输出头为双分支——类别预测( W × H × K A W \times H \times KA W×H×KA)和box回归预测( W × H × 4 A W \times H \times 4A W×H×4A)。W、H表示特征图宽、高; K表示类别个数; A表示anchor个数。
二、RetinaHead代码解读
1.总概
RetinaNet类是继承于父类AnchorHead类,其重写了父类的这3个方法。
from .anchor_head import AnchorHead
@HEADS.register_module()
class RetinaHead(AnchorHead):
def __init__():
...
# 以下这两个方法都是对于单个stage下的Head进行相关操作
def _init_layers(self): # 定义网络层结构
...
def forward_single(self, x): # 前向推理
...
2.def __init__()
定义了一些比较基础的参数,比如输入通道数,图中每个subnet中卷积层需要的个数。
def __init__(self,
num_classes, # 类别数量
in_channels, # 输入通道数,也即Neck每一个stage的输出通道数,一般均为256
stacked_convs=4, # Neck输出头中[class subnet、box subnet]的堆叠卷积层数量均为4
conv_cfg=None,
norm_cfg=None,
anchor_generator=dict(
type='AnchorGenerator',
octave_base_scale=4,
scales_per_octave=3,
ratios=[0.5, 1.0, 2.0],
strides=[8, 16, 32, 64, 128]),
init_cfg=dict(
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='retina_cls',
std=0.01,
bias_prob=0.01)),
**kwargs):
self.stacked_convs = stacked_convs
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
super(RetinaHead, self).__init__(
num_classes,
in_channels,
anchor_generator=anchor_generator,
init_cfg=init_cfg,
**kwargs)
3.def _init_layers(self)
为Neck的每一个stage的输出定义Head部分的网络结构(双分支Head结构),这里要注意它是对每一个stage的输出,所以代码中所展示的是对于单个stage输出去构建Head部分网络结构。
def _init_layers(self):
"""Initialize layers of the head."""
self.relu = nn.ReLU(inplace=True) # 激活函数
self.cls_convs = nn.ModuleList() # 对应图中的class subnet分支结构
self.reg_convs = nn.ModuleList() # 对应图中的box subnet分支结构
for i in range(self.stacked_convs): # stacked_convs=4
chn = self.in_channels if i == 0 else self.feat_channels # 由于继承了AnchorHead类, 变量feat_channel=256
# 构建4个中间卷积层,分类和回归分支不共享权重
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg))
# 构建最终输出层
# 类别分支最后的shape为(W x H x KA)
self.retina_cls = nn.Conv2d(
self.feat_channels, # 256
self.num_base_priors * self.cls_out_channels,
3,
padding=1)
# box回归分支最后的shape为(W x H x 4A)
self.retina_reg = nn.Conv2d(
self.feat_channels, # 256
self.num_base_priors * 4,
3, padding=1)
4.def forward_single(self, x)
这块做的就是foward()的工作,对输入x进行正推。
最终输出shape为( W × H × K A W \times H \times KA W×H×KA)的类别预测和shape为( W × H × 4 A W \times H \times 4A W×H×4A)的box回归预测。
def forward_single(self, x):
cls_feat = x
reg_feat = x
for cls_conv in self.cls_convs:
cls_feat = cls_conv(cls_feat)
for reg_conv in self.reg_convs:
reg_feat = reg_conv(reg_feat)
cls_score = self.retina_cls(cls_feat)
bbox_pred = self.retina_reg(reg_feat)
return cls_score, bbox_pred
总结
AnchorHead类的代码解读过段时间会发布~~
本文仅代表个人理解,若有不足,欢迎批评指正。