『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
目录
- 代码位置
- 一、原始数据信息录入
- 二、数据信息整理
- 类别信息记录
- 图片信息记录
- 三、获取图片
- 小结
Github地址:Mask_RCNN
『计算机视觉』Mask-RCNN_论文学习
『计算机视觉』Mask-RCNN_项目文档翻译
『计算机视觉』Mask-RCNN_推断网络其一:总览
『计算机视觉』Mask-RCNN_推断网络其二:基于ReNet101的FPN共享网络
『计算机视觉』Mask-RCNN_推断网络其三:RPN锚框处理和Proposal生成
『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
『计算机视觉』Mask-RCNN_推断网络其五:目标检测结果精炼
『计算机视觉』Mask-RCNN_推断网络其六:Mask生成
『计算机视觉』Mask-RCNN_推断网络终篇:使用detect方法进行推断
『计算机视觉』Mask-RCNN_锚框生成
『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
『计算机视觉』Mask-RCNN_训练网络其三:训练Model
本节介绍的数据集class构建为官方demo,对从零开始构建自己的数据集训练感兴趣的建议了解了本文及本文对应的代码文件后,看一下『计算机视觉』Mask-RCNN_关键点检测分支介绍了由自己的数据构建Mask RCNN可用形式的实践。
代码位置
在脚本train_shapes.ipynb中,作者演示了使用合成图片进行训练Mask_RCNN的小demo,我们将以此为例,从训练数据的角度重新审视Mask_RCNN。
在训练过程中,我们最先要做的根据我们自己的数据集,集成改写基础的数据读取class:util.py中的Dataset class,然后根据数据集调整网络配置文件配置config.py中的Config 类,使得网络形状配适数,然后再去考虑训练的问题。按照逻辑流程,本节我们以train_shapes.ipynb中的数据生成为例,学习Dataset class的运作机理。
在示例程序中,首先创建新的Dataset的子类(这里贴出整个class代码,后面会分节讲解):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
|
一、原始数据信息录入
然后调用如下方法(IMAGE_SHAPE=[128 128 3],介绍config时会提到),准备训练用数据和验证集数据,注意,此时仅仅是在做准备并未真实的生成或读入图片数据,
| 1 2 3 4 5 6 7 8 9 |
|
其调用的load_shapes方法如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
这里涉及了两个父类继承来的方法self.add_class和self.add_image,我们去util.py中的Dataset class看一看,
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
也就是说,在Dataset中有self.image_info 和 self.class_info 两个list,它们的元素都是固定key的字典,
"source"对应数据集名称,
"id"对应本数据集内当前图片/类别标号
"path"仅image_info含有,对应图像路径,可为None
"name"仅class_info含有,对应类别描述
在后面的prepare方法中我们可以进一步了解,使用source.id作key,可以索引到一个内建的新的internal id,这也像我们解释了为什么文档中说Mask_RCNN支持多个数据集同时训练的由来。
回到load_shapes方法,self.random_image方法为新建方法,这里作者使用算法生成图像做训练,该方法返回生成图像函数所需的随机参数,之后调用add_image时传入path为None,也是因为数据并非从磁盘读取,而是自己生成,并传入了额外的self.random_image方法返回的生成参数(我们不必关系具体参数是什么),作为字典参数解读,添加进self.image_info中,
| 1 2 3 4 5 |
|
从这里,我们进一步了解了self.image_info的含义,记录每一张图片的id信息("source"和"id"),记录每一张图片的数据信息(如何获取图像矩阵的线索,包含"path"或者其他的字典索引,只要保证后面能实现函数,根据这个信息获取图片数据即可)
二、数据信息整理
在初始化了 self.image_info 和 self.class_info 两个list之后,Dataset已经记录了原始的类别信息和图像信息,调用prepare方法进行规范化,
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
类别信息记录
将"source.id"映射为唯一的internal IDs,并将全部的internal IDs存储在self.class_ids
source_class_ids,记录下每一个"source"对应的internal IDs
class_from_source_map,记录下"source.id":internal IDs的映射关系
| 1 2 3 4 |
|
输出如下:
[{'source': '', 'id': 0, 'name': 'BG'}, {'source': 'shapes', 'id': 1, 'name': 'square'}, {'source': 'shapes', 'id': 2, 'name': 'circle'}, {'source': 'shapes', 'id': 3, 'name': 'triangle'}] [0 1 2 3] {'': [0], 'shapes': [0, 1, 2, 3]} {'.0': 0, 'shapes.1': 1, 'shapes.2': 2, 'shapes.3': 3}
有固定的source为空的类别0(id和internal ID都是),标记为背景,会添加进source_class_ids中全部的数据集对应的类别中(上面"shape"数据集我们仅定义了3个类,在映射中多了一个0变成4个类)。
图片信息记录
图片信息不像类别一样麻烦,我们简单输出三张,
| 1 2 3 4 5 6 7 8 |
|
结果如下,
[{'id': 0, 'source': 'shapes', 'path': None, 'width': 128, 'height': 128, 'bg_color': array([163, 143, 173]), 'shapes': [('circle', (178, 140, 65), (83, 104, 20)), ('circle', (192, 52, 82), (48, 58, 20))]}, {'id': 1, 'source': 'shapes', 'path': None, 'width': 128, 'height': 128, 'bg_color': array([ 5, 99, 71]), 'shapes': [('triangle', (90, 32, 55), (39, 21, 22)), ('circle', (214, 49, 173), (39, 78, 21))]}, {'id': 2, 'source': 'shapes', 'path': None, 'width': 128, 'height': 128, 'bg_color': array([138, 52, 83]), 'shapes': [('circle', (180, 74, 150), (105, 45, 27))]}] [0 1 2] {'shapes.0': 0, 'shapes.1': 1, 'shapes.2': 2}
【注1】由于这是图像检测任务而非图像分类任务,故每张图片仅仅和归属数据集存在映射,和类别信息没有直接映射。图像上的目标和类别才存在映射关系,不过那不在本部分函数涉及范围内。
【注2】internal IDs实际上就是info的索引数组,使用internal IDs的值可以直接索引对应图片顺序的info信息。
总结,在调用self.prepare之前,通过自己的新建方法调用self.add_class()和self.add_image(),将图片和分类的原始信息以dict的形式添加到class_info与image_info两个list中,即可。
三、获取图片
然后我们获取一些样例图片进行展示,
| 1 2 3 4 5 6 7 |
|
由上面代码我们可以获悉如下信息:
使用self.image.ids即internal IDs进行图片选取
自行实现load_image方法,获取图片internal IDs,索引图片原始信息(info),利用原始信息输出图片
自行实现load_mask方法,获取图片internal IDs,索引图片原始信息(info),利用原始信息输出图片的masks和对应internal类别,注意一张图片可以有多个mask并分别对应自己的类别
上述代码输出如下(仅展示前两张),

下面贴出load_image和load_mask方法(详见train_shapes.ipynb),具体实现不是重点,毕竟我们也不是在研究怎么画2D图,重点在于上面提到的它们的功能,这涉及到我们迁移到自己的数据时如何实现接口。load_image方法返回一张图片,load_mask方法返回(h,w,c)的01掩码以及(c,)的class id,注意,c指的是盖章图片中instance的数目
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
小结
正如Dataset注释所说,要想运行自己的数据集,我们首先要实现一个方法(load_shapes,根据数据集取名即可)收集原始图像、类别信息,然后实现两个方法(load_image、load_mask)分别实现获取单张图片数据、获取单张图片对应的objs的masks和classes,这样基本完成了数据集类的构建。
The base class for dataset classes. To use it, create a new class that adds functions specific to the dataset you want to use. For example: class CatsAndDogsDataset(Dataset): def load_cats_and_dogs(self): ... def load_mask(self, image_id): ... def image_reference(self, image_id): ... See COCODataset and ShapesDataset as examples.
重点来了,训练自己的数据集
工程目录如下图所示:
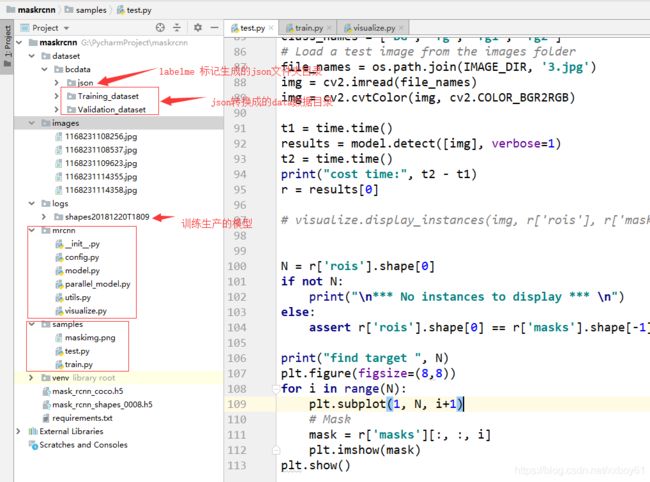
train.py
# # Mask R-CNN - Train on Shapes Dataset
#
#
# This notebook shows how to train Mask R-CNN on your own dataset. To keep things simple we use a synthetic
# dataset of shapes (squares, triangles, and circles) which enables fast training. You'd still need a GPU,
# though, because the network backbone is a Resnet101, which would be too slow to train on a CPU. On a GPU,
# you can start to get okay-ish results in a few minutes, and good results in less than an hour.
# The code of the *Shapes* dataset is included below. It generates images on the fly, so it doesn't require
# downloading any data. And it can generate images of any size, so we pick a small image size to train faster.
# In[1]:
import os
import sys
import random
import math
import re
import time
import numpy as np
import cv2
import yaml
from PIL import Image
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
# Root directory of the project
ROOT_DIR = os.path.abspath("../")
sys.path.append(ROOT_DIR) # To find local version of the library
# Import Mask RCNN
from mrcnn.config import Config
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
from mrcnn.model import log
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory to save logs and model checkpoints, if not provided
# through the command line argument --logs
DEFAULT_LOGS_DIR = os.path.join(ROOT_DIR, "logs")
# ## Configurations
# In[2]:
class ShapesConfig(Config):
"""Configuration for training on the bceasy dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 1 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 1 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 3 # background + 3 shapes(fg, fg1, fg2)
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 320
IMAGE_MAX_DIM = 320
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8 * 8, 16 * 8, 32 * 8, 64 * 8, 128 * 8) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 50
# use small validation steps since the epoch is small
VALIDATION_STEPS = 5
config = ShapesConfig()
config.display()
# ## Notebook Preferences
# In[3]:
def get_ax(rows=1, cols=1, size=8):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Change the default size attribute to control the size
of rendered images
"""
_, ax = plt.subplots(rows, cols, figsize=(size * cols, size * rows))
return ax
# ## Dataset
#
# Create a synthetic dataset
#
# Extend the Dataset class and add a method to load the shapes dataset, `load_shapes()`, and override the following methods:
#
# * load_image()
# * load_mask()
# * image_reference()
# In[4]:
class ShapesDataset(utils.Dataset):
"""Generates the shapes synthetic dataset. The dataset consists of simple
shapes (fg, fg1, fg2) placed randomly on a blank surface.
The images are generated on the fly. No file access required.
"""
def get_obj_index(self, image):
'''
get instances in image
:param image:
:return:
'''
n = np.max(image)
return n
def from_yaml_get_class(self, image_id):
'''
get mask label from yaml
:param image_id:
:return: labels expect BG
'''
info = self.image_info[image_id]
with open(info['yaml_path']) as f:
temp = yaml.load(f.read())
labels = temp['label_names']
del labels[0]
return labels
# rewrite draw_mask
def draw_mask(self, num_obj, mask, image, image_id):
info = self.image_info[image_id]
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
pixel = image.getpixel((i, j))
if pixel == index + 1:
mask[j, i, index] = 1
return mask
def load_shapes(self, count, labelme_json_folder):
'''
Generate the requested number of synthetic images.
:param count:number of images to generate
:param train_img_folder:train image folder
:param labelme_json_folder: labelme_json_to_dataset's folder
:param imgs_list:train imgs
:return:
'''
# Add classes
self.add_class("shapes", 1, "fg")
self.add_class("shapes", 2, "fg1")
self.add_class("shapes", 3, "fg2")
imgs_list = os.listdir(labelme_json_folder)
# Add images
# Generate random specifications of images (i.e. color and
# list of shapes sizes and locations). This is more compact than
# actual images. Images are generated on the fly in load_image().
for i in range(count):
file_name = imgs_list[i][:-5]
mask_path = labelme_json_folder + "/" + file_name + "_json/label.png"
yaml_path = labelme_json_folder + "/" + file_name + "_json/info.yaml"
train_img_path = labelme_json_folder + "/" + file_name + "_json/img.png"
train_img = cv2.imread(train_img_path)
self.add_image("shapes", image_id=i, path=train_img_path,
width=train_img.shape[1], height=train_img.shape[0],
mask_path=mask_path, yaml_path=yaml_path)
def image_reference(self, image_id):
"""Return the shapes data of the image."""
info = self.image_info[image_id]
if info["source"] == "shapes":
return info["shapes"]
else:
super(self.__class__).image_reference(self, image_id)
# rewrite load_mask
def load_mask(self, image_id):
"""Generate instance masks for shapes of the given image ID.
"""
info = self.image_info[image_id]
# number of object
img = Image.open(info['mask_path'])
num_obj = self.get_obj_index(img)
mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img, image_id)
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
for i in range(num_obj - 2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
labels = []
labels = self.from_yaml_get_class(image_id)
labels_form = []
for i in range(len(labels)):
if labels[i].find("fg") != -1:
labels_form.append("fg")
elif labels[i].find("fg1") != -1:
labels_form.append("fg1")
elif labels[i].find("fg2") != -1:
labels_form.append("fg2")
class_ids = np.array([self.class_names.index(s) for s in labels_form])
return mask, class_ids.astype(np.int32)
def draw_shape(self, image, shape, dims, color):
"""Draws a shape from the given specs."""
# Get the center x, y and the size s
x, y, s = dims
if shape == 'square':
cv2.rectangle(image, (x - s, y - s), (x + s, y + s), color, -1)
elif shape == "circle":
cv2.circle(image, (x, y), s, color, -1)
elif shape == "triangle":
points = np.array([[(x, y - s),
(x - s / math.sin(math.radians(60)), y + s),
(x + s / math.sin(math.radians(60)), y + s),
]], dtype=np.int32)
cv2.fillPoly(image, points, color)
return image
def random_shape(self, height, width):
"""Generates specifications of a random shape that lies within
the given height and width boundaries.
Returns a tuple of three valus:
* The shape name (square, circle, ...)
* Shape color: a tuple of 3 values, RGB.
* Shape dimensions: A tuple of values that define the shape size
and location. Differs per shape type.
"""
# Shape
shape = random.choice(["fg", "fg1", "fg2"])
# Color
color = tuple([random.randint(0, 255) for _ in range(3)])
# Center x, y
buffer = 20
y = random.randint(buffer, height - buffer - 1)
x = random.randint(buffer, width - buffer - 1)
# Size
s = random.randint(buffer, height // 4)
return shape, color, (x, y, s)
def random_image(self, height, width):
"""Creates random specifications of an image with multiple shapes.
Returns the background color of the image and a list of shape
specifications that can be used to draw the image.
"""
# Pick random background color
bg_color = np.array([random.randint(0, 255) for _ in range(3)])
# Generate a few random shapes and record their
# bounding boxes
shapes = []
boxes = []
N = random.randint(1, 4)
for _ in range(N):
shape, color, dims = self.random_shape(height, width)
shapes.append((shape, color, dims))
x, y, s = dims
boxes.append([y - s, x - s, y + s, x + s])
# Apply non-max suppression wit 0.3 threshold to avoid
# shapes covering each other
keep_ixs = utils.non_max_suppression(np.array(boxes), np.arange(N), 0.3)
shapes = [s for i, s in enumerate(shapes) if i in keep_ixs]
return bg_color, shapes
# In[5]:
# Training dataset
train_labelme_json_folder = os.path.join(ROOT_DIR, "dataset\\bcdata\\Training_dataset")
print('mask_folder', train_labelme_json_folder)
train_imgs_list = os.listdir(train_labelme_json_folder)
train_imgs_count = len(train_imgs_list)
print('train_imgs_count', train_imgs_count)
dataset_train = ShapesDataset()
dataset_train.load_shapes(train_imgs_count, train_labelme_json_folder)
dataset_train.prepare()
# Validation dataset
val_labelme_json_folder = os.path.join(ROOT_DIR, "dataset\\bcdata\\Validation_dataset")
print('val_labelme_json_folder', val_labelme_json_folder)
val_imgs_list = os.listdir(val_labelme_json_folder)
val_imgs_count = len(val_imgs_list)
print('val_imgs_count', val_imgs_count)
dataset_val = ShapesDataset()
dataset_val.load_shapes(val_imgs_count, val_labelme_json_folder)
dataset_val.prepare()
# ## Create Model
# In[7]:
# Create model in training mode
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# In[ ]:
# In[8]:
# Which weights to start with?
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# Load weights trained on MS COCO, but skip layers that
# are different due to the different number of classes
# See README for instructions to download the COCO weights
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
# Load the last model you trained and continue training
model.load_weights(model.find_last(), by_name=True)
# ## Training
#
# Train in two stages:
# 1. Only the heads. Here we're freezing all the backbone layers and training only the randomly initialized layers (i.e. the ones that we didn't use pre-trained weights from MS COCO). To train only the head layers, pass `layers='heads'` to the `train()` function.
#
# 2. Fine-tune all layers. For this simple example it's not necessary, but we're including it to show the process. Simply pass `layers="all` to train all layers.
# In[ ]:
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=20,
layers='heads')
# In[ ]:
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 10,
epochs=20,
layers="all")test.py
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
import cv2
from PIL import Image
import time
# Root directory of the project
ROOT_DIR = os.path.abspath("../")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn.config import Config
from datetime import datetime
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR ,"mask_rcnn_shapes_0034.h5")
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 2
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 3 # background + 3 shapes(fg, fg1, fg2)
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 320
IMAGE_MAX_DIM = 320
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8 * 8, 16 * 8, 32 * 8, 64 * 8, 128 * 8) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small
VALIDATION_STEPS = 5
def get_instances_mask(image, boxes, masks, class_ids, class_names, scores=None):
"""
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
masks: [height, width, num_instances]
class_ids: [num_instances]
class_names: list of class names of the dataset
scores: (optional) confidence scores for each box
"""
# Number of instances
N = boxes.shape[0]
if not N:
print("\n*** No instances to display *** \n")
else:
assert boxes.shape[0] == masks.shape[-1] == class_ids.shape[0]
# Show area outside image boundaries.
height, width = image.shape[:2]
img = np.zeros((height, width, 1), np.uint8)
masked_image = image.astype(np.uint32).copy()
for i in range(N):
# Bounding box
if not np.any(boxes[i]):
# Skip this instance. Has no bbox. Likely lost in image cropping.
continue
y1, x1, y2, x2 = boxes[i]
# Mask
mask = masks[:, :, i]
# Mask Polygon
# Pad to ensure proper polygons for masks that touch image edges.
padded_mask = np.zeros((mask.shape[0] + 2, mask.shape[1] + 2), dtype=np.uint8)
padded_mask[1:-1, 1:-1] = mask
image, contours, hierarchy = cv2.findContours(padded_mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
img = cv2.drawContours(img, contours, -1, (255), cv2.FILLED)
return img
def get_instances(image, mask):
"""
Apply the given mask to the image.
"""
for c in range(3):
image[:, :, c] = np.where(mask <= 128, 255, image[:, :, c])
return image
#import train_tongue
class InferenceConfig(ShapesConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'fg', 'fg1', 'fg2']
# Load a test image from the images folder
file_names = os.path.join(IMAGE_DIR, '1168231109623.jpg')
img = cv2.imread(file_names)
img = cv2.resize(img, (720, 720))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_copy = img.copy()
t1 = time.time()
results = model.detect([img], verbose=1)
t2 = time.time()
print("cost time:", t2 - t1)
r = results[0]
#visualize.display_instances(img, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])
mask_img = get_instances_mask(img, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])
cv2.imshow('mask_img', mask_img)
mask_img = cv2.medianBlur(mask_img, 5)
instances = get_instances(img_copy, mask_img)
instances = cv2.cvtColor(instances, cv2.COLOR_RGB2BGR)
cv2.imshow('image', instances)
cv2.waitKey(0)