Pytorch-RNN关于pack_padded_sequence之enforce_sorted详解
先说需求:
如果不知道pack与pad,请看这里blog
- input为一个batch,这个batch里由N个segment组成,这个segment的序列十分重要,不能打乱。因此,我不能把这个batch按照segment的长度,来从大到小进行排序
- 但是我需要用LSTM来处理这个batch里面的每个segment
- 而且我还需要保证,LSTM处理之后,这个batch还是保持原来的segment序列
解决方法:
调用pack_padded_sequence来处理input,并且传入参数enforce_sorted=False
给出代码(一层的LSTM只需要用到最后一个unit的hidden_state,所以我直接采用LSTM的返回值了)
packed = rnn.pack_padded_sequence(x, x_len.cpu(), batch_first=True, enforce_sorted=False)
output, (hidden, _) = LSTM(packed)
if self.ndirections == 1:
return hidden.squeeze(0)
如果需要每个unit的hidden_state的话,那么就需要对output进行padding了(调用与pack_padded_sequence相对的函数——pad_packed_sequence)
all_hidden_state = rnn.pad_packed_sequence(output, batch_first=True, total_length=config.max_segment_len)[0]
原理
非常重要的三点,
-
当pack传入enforce_sorted==False时,pack函数会预先自动为input按照length进行排序,然后对排好序的input再进行pack;
-
如果pack时enforce_sorted==False,那么pad_packed_sequence的最终输出也会受到影响——在pack时排好序的input,在pad后会返回成原有的顺序;
-
即使pack时enforce_sorted==False,我们执行"LSTM(packed)"所返回出来的每个segment的features(即最后一个unit的hidden_state),仍然是原始input的序列的。
验证
- 先看Pytorch官网上给的doc 这里packed是按照lens排好序的(原理1),并且seq_unpacked与原始的seq是一模一样的(原理2)
Example:
>>> from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
>>> seq = torch.tensor([[1,2,0], [3,0,0], [4,5,6]])
>>> lens = [2, 1, 3]
>>> packed = pack_padded_sequence(seq, lens, batch_first=True, enforce_sorted=False)
>>> packed
PackedSequence(data=tensor([4, 1, 3, 5, 2, 6]), batch_sizes=tensor([3, 2, 1]),
sorted_indices=tensor([2, 0, 1]), unsorted_indices=tensor([1, 2, 0]))
>>> seq_unpacked, lens_unpacked = pad_packed_sequence(packed, batch_first=True)
>>> seq_unpacked
tensor([[1, 2, 0],
[3, 0, 0],
[4, 5, 6]])
>>> lens_unpacked
tensor([2, 1, 3])
- 原理3的验证
首先是输入seq,lens为[2, 1, 3],也就是说第一个segment,长度为2,我们需要用第2个LSTM Unit的hidden_state来代表它的features;同理第二个segment,长度为1,我们需要用第1个LSTM Unit的hidden_state来代表它的features
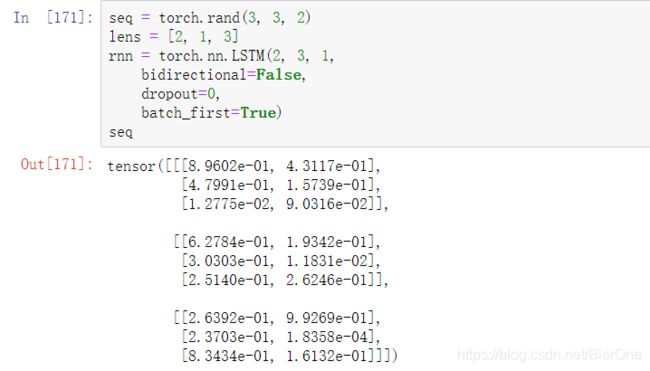
ok,接着我们把它输入到LSTM中去,我们来比较hidden与output_unpacked

可以发现,hidden的第一行,也就是第一个segment的features,正好对应output_unpacked 中第一个LSTM Units中的第二行,也就是LSTM的第二个Unit的hidden state,这正好与我们前面的lens对应起来了!第一个segment的长度为2 其他的亦同理