中文纠错——CRF+N-grams
中文纠错——CRF+N-grams
- 中文纠错的两步任务
-
- CRF: Conditional Random Field
-
- 1. CRF的原理
- 2. CRF在本实验的应用
- 3. 数据预处理
- N-grams
-
- 1. N-grams的原理
- 2. N-grams在本实验中的应用
- 代码
- 参考文献:
这是我的web搜索课程的大作业之一,为了这个作业学习了CRF和N-grams的原理,记录以便以后参考。
中文纠错的两步任务
本实验采用CRF模型对文本句子进行错误标注,n-grams模型对错误文本句子进行纠错。
CRF: Conditional Random Field
1. CRF的原理
- CRF的原理
条件随机场由图论发展而来,目前使用最广泛的是线性链条件随机场。
线性链条件随机场的定义如下:

其原理如下图所示:
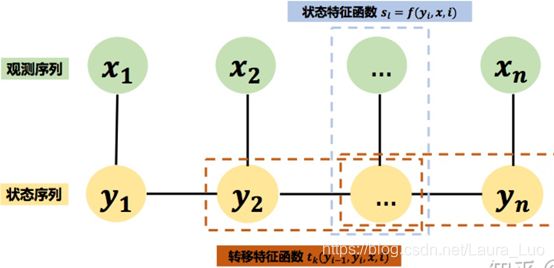
某一刻的状态 y i y_i yi 只与输入的观测序列和相邻的两个状态有关,如上图创建两个特征函数 s l , t k s_l,t_k sl,tk,由图论中的Hammersley-Clifford定理,可以得到:

其中
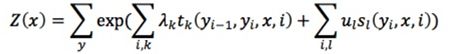
为归一化因子,特征函数 s l , t k s_l,t_k sl,tk为二值函数,函数值为0或1,满足特征条件时取值为1,否则为0; μ l , λ k μ_l,λ_k μl,λk为特征对应权值,其取值为任意值,当取值为正时,表示倾向于此特征,反之表示不倾向。在模型的训练当中,训练的参数为权重 μ l , λ k μ_l,λ_k μl,λk。
2. CRF在本实验的应用
可以见本实验的第一个任务看成中文词性标注任务,其中标注类别为2类——“C”和“W”。实验步骤如下:
(1) 对数据中的句子序列进行原子切分,得到原子切分序列;
(2) 对字进行标注;
(3) 确定特征函数;
(4) 训练CRF模型参数
其中,本实验采用的特征函数是
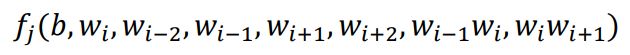
b表示bias, w i w_i wi表示第i个词。 f j f_j fj表示第j个标注序列的特征函数。设 l j l_j lj为一个序列的标注序列,s为输入的序列,那么此标注的分数为:
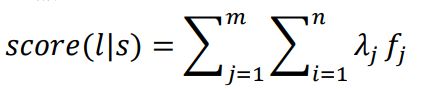
其条件概率:
![]()
3. 数据预处理
本实验中CRF模型训练的用到的数据集都经过了切分和字性标注的处理,句子被切分成一个个字,由出错序列和正确序列一一对比标注字的正误。句子序列的长度限制在5个字以上。但是产生的问题是,当正确序列与出错序列的长度不相同时,就不会标注字的正误,这种序列被跳过了,在实际问题中,无法解决赘余、缺字这样的拼写错误。
N-grams
1. N-grams的原理
N-grams将文本切分为长度等于N的字节片段(gram),统计所有gram的频度,按照一个阈值过滤形成关键gram表,作为文本的向量特征空间。N-grams假设第N个词的出现只与前面N-1个词相关,整句的概率就是各个词出现概率的乘积,例如当N=2时有:
P ( w 1 , w 2 , … , w n ) = ∏ i = 1 n P ( w i ∣ w i − 1 ) P(w_1,w_2,…,w_n) = \prod_{i=1}^{n}P( w_i |w_{i-1}) P(w1,w2,…,wn)=i=1∏nP(wi∣wi−1)
2. N-grams在本实验中的应用
本实验传入的训练数据是训练集中正确的句子序列,采用的是tri-grams。首先统计了在训练集中出现的tri-grams,并且将tri-grams按照频度降序排序形成tri-grams列表作为本次实验的向量特征空间,注意,本次实验并没有设置阈值。在纠错过程中,传入的数据是经过了CRF预测的标注数据,当检测到标注为‘W’的字时,就会截取这个字的前一个字和这个字的后一个字,三个字组成一个向量,到grams list中寻找第一个字和第三个字都和此向量相同的gram进行替换。
如果训练的数据集不够大,则找不到对应的gram,无法进行改错。
代码
本次代码在demo的基础上没有做任何改变
"""
@brief preprocess_crf.py
对数据进行预处理,打上标签,生成的文件放在.char.txt文件中
"""
import pandas as pd
def tagger(correct_s,wrong_s):
"""
对数据打标签
:param correct_s:
:param wrong_s:
:return:
"""
tag_data = []
if len(correct_s) != len(wrong_s): # 长度不相同的错误不可以更改?
return ''
else:
for id, word in enumerate(wrong_s):
if word == correct_s[id]:
tag_data.append(word+" "+"C")
else:
tag_data.append(word+" "+"W")
return tag_data
def process(data,data_type):
f = open('data/{}.char.txt'.format(data_type),'w',encoding='utf-8')
for line in data:
w_c = line.split("\t")
wrong_sentence = w_c[0].split()
correct_sentence = w_c[1].split()
for i in tagger(wrong_s=wrong_sentence,correct_s=correct_sentence):
f.write(i)
f.write('\n')
f.write('\n')
输出结果一部分如图所示:
"""
@ brief crf.py
"""
from sklearn_crfsuite import CRF, metrics, scorers
import pandas as pd
import time
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
if i == 0:
p_word = ''
pp_word = ''
l_word = sent[i+1][0]
ll_word = sent[i+2][0]
elif i == 1:
p_word = sent[i-1][0]
pp_word = ''
l_word = sent[i + 1][0]
ll_word = sent[i + 2][0]
elif i == len(sent)-2:
p_word = sent[i-1][0]
pp_word = sent[i-2][0]
l_word = sent[i+1][0]
ll_word = ''
elif i == len(sent)-1:
p_word = sent[i - 1][0]
pp_word = sent[i - 2][0]
l_word = ''
ll_word = ''
else:
p_word = sent[i - 1][0]
pp_word = sent[i - 2][0]
l_word = sent[i + 1][0]
ll_word = sent[i + 2][0]
# 使用的特征:
#
features = {
'bias': 1.0,
'w-2':pp_word,
'w-1':p_word,
'w':word,
'w+1':l_word,
'w+2':ll_word,
'w-1:w':p_word+word,
'w:w+1':word+l_word
}
if i == 0:
features['BOS'] = True
if i == len(sent)-1:
features['EOS'] = True
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, label in sent]
def sen_filter(sentence,length):
if len(sentence)> length:
return True
else:
return False
def load_crf_data(data):
data = pd.read_csv(data, header=None, sep=' ')
sen = []
sen_list = []
label = []
label_list = []
for i, word in enumerate(list(data[0])):
if word != '。':
sen.append(word)
label.append(data[1][i])
else:
sen.append(word)
label.append(data[1][i])
sen_list.append(sen)
label_list.append(label)
sen = []
label = []
return sen_list,label_list
def load_crf_train_data(data_path):
# 加载训练集中的句子列表和标签列表
sen_list, label_list = load_crf_data(data_path)
word_label_s_list=[]
word_label_list=[]
# 加载数据成[[word1,label1],[word2,label2],...]形式
for i in range(0,len(sen_list)-1):
if sen_filter(sen_list[i], 5): # 滤去长度小于5的句子
for j in range(0,len(sen_list[i])-1):
word_label_list.append([sen_list[i][j],label_list[i][j]])
word_label_s_list.append(word_label_list)
word_label_list=[]
return word_label_s_list
if __name__ == "__main__":
# 读入训练和测试数据
train_sents = load_crf_train_data('data/train.char.txt')
test_sents = load_crf_train_data('data/test.char.txt')
# 数据转成特征
X_train = [sent2features(s) for s in train_sents]
y_train = [sent2labels(s) for s in train_sents]
X_test = [sent2features(s) for s in test_sents]
y_test = [sent2labels(s) for s in test_sents]
start =time.time()
# 训练crf模型
crf = CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=200,
all_possible_transitions=True
)
crf.fit(X_train,y_train)
labels = list(crf.classes_)
y_pred = crf.predict(X_test)
# 输出模型性能
sorted_labels = sorted(
labels,
key=lambda name: (name[1:], name[0])
)
print(metrics.flat_classification_report(
y_test, y_pred, labels=sorted_labels, digits=3
))
end = time.time()
print(end-start)
f = open('data/crf_predict.txt','w',encoding='utf-8')
for i in range(0,len(test_sents)):
for j in range(0,len(test_sents[i])):
word = test_sents[i][j][0]
label = y_pred[i][j]
w_l = word+" "+label
f.write(w_l)
f.write('\n')
f.write('。'+" "+"C")
f.write('\n')
f.write('\n')
predict的结果如下:

模型的性能:
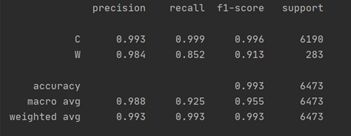
"""
ngram.py
"""
from nltk.util import ngrams
from collections import defaultdict
import time
import pandas as pd
start_time = time.time()
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~“”?,!【】()、。:;’‘……¥·"""
# 移除标点符号
def removePunctuations(sen):
temp_l = sen.split()
i = 0
for word in temp_l:
j = 0
for l in word:
if l in punctuation:
if l == "'":
if j + 1 < len(word) and word[j + 1] == 's':
j = j + 1
continue
word = word.replace(l, "")
j += 1
temp_l[i] = word
i = i + 1
content = " ".join(temp_l)
return content
# 读入数据
def loadCorpus(file_path, bi_dict, tri_dict, quad_dict, vocab_dict):
w1 = '' # for storing the 3rd last word to be used for next token set
w2 = '' # for storing the 2nd last word to be used for next token set
w3 = '' # for storing the last word to be used for next token set
token = []
# 语料库的总字数
word_len = 0
# open the corpus file and read it line by line
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
content = removePunctuations(line)
token = content.split()
word_len = word_len + len(token)
if not token:
continue
# add the last word from previous line
if w3 != '':
token.insert(0, w3)
temp0 = list(ngrams(token, 2))
# since we are reading line by line some combinations of word might get missed for pairing
# for trigram
# first add the previous words
if w2 != '':
token.insert(0, w2)
# tokens for trigrams
temp1 = list(ngrams(token, 3))
# insert the 3rd last word from previous line for quadgram pairing
if w1 != '':
token.insert(0, w1)
# add new unique words to the vocaulary set if available
# 统计词频
for word in token:
if word not in vocab_dict:
vocab_dict[word] = 1
else:
vocab_dict[word] += 1
# tokens for quadgrams
temp2 = list(ngrams(token, 4))
# count the frequency of the bigram sentences
for t in temp0:
sen = ' '.join(t)
bi_dict[sen] += 1
# count the frequency of the trigram sentences
for t in temp1:
sen = ' '.join(t)
tri_dict[sen] += 1
# count the frequency of the quadgram sentences
for t in temp2:
sen = ' '.join(t)
quad_dict[sen] += 1
# then take out the last 3 words
n = len(token)
# store the last few words for the next sentence pairing
if (n - 3) >= 0:
w1 = token[n - 3]
if (n - 2) >= 0:
w2 = token[n - 2]
if (n - 1) >= 0:
w3 = token[n - 1]
return word_len
def correct(data, tri_dict_order_list):
data = pd.read_csv(data, header=None, sep=' ')
sen = []
sen_list = []
label = []
label_list = []
for i, word in enumerate(list(data[0])):
if word != '。':
sen.append(word)
label.append(data[1][i])
else:
sen.append(word)
label.append(data[1][i])
sen_list.append(sen)
label_list.append(label)
sen = []
label = []
f = open('predict.txt', 'w', encoding='utf-8')
for sen_num, sen in enumerate(sen_list):
correct_sen = []
for word_num, word in enumerate(sen):
if label_list[sen_num][word_num] == "C":
correct_sen.append(word)
if label_list[sen_num][word_num] == 'W':
if word_num == 0:
if sen_num == 0:
p_word = ' '
l_word = sen[word_num + 1]
else:
p_word = sen_list[sen_num - 1][-1]
l_word = sen[word_num + 1]
if word_num == len(sen) - 1:
if sen_num == len(sen_list) - 1:
p_word = sen[word_num - 1]
l_word = ' '
else:
p_word = sen[word_num - 1]
l_word = sen_list[sen_num + 1][0]
else:
p_word = sen[word_num - 1]
l_word = sen[word_num + 1]
correct_sen.append(calculate_ngram(p_word, word, l_word, tri_dict_order_list))
f.write(' '.join(correct_sen))
f.write('\n')
print("原句:" + ''.join(sen))
print("纠错结果:" + ''.join(correct_sen))
print()
f.close()
def calculate_ngram(p_word, word, l_word, ngram_list):
for gram in ngram_list:
if p_word == gram[0][0] and l_word == gram[0][4]:
return gram[0][2]
break
else:
continue
return word
if __name__ == '__main__':
vocab_dict = defaultdict(int)
bi_dict = defaultdict(int)
tri_dict = defaultdict(int)
quad_dict = defaultdict(int)
prob_dict = defaultdict(list)
start = time.time()
token_len = loadCorpus('target_train.txt', bi_dict, tri_dict, quad_dict, prob_dict)
tri_dict_order_list = sorted(tri_dict.items(), key=lambda x: x[1], reverse=True)
correct("data/crf_predict.txt", tri_dict_order_list)
end = time.time()
print(end-start)
一部分输出如图:
![]()
改对了
 改错了
改错了
参考文献:
https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html
https://zhuanlan.zhihu.com/p/148813079