利用Amazon Machine Learning与Amazon Redshift建立二进制分类模型
日常生活中的大部分决策都以二进制形式存在,具体来说就是这类问题能够以是或者否来回答。而在商业活动中,能够以二进制方式回答的问题也有很多。举例来说:“这种情况是否属于交易欺诈?”,“这位客户是否会购买该产品?”或者“这位用户是否存在流失风险?”等等。在机器学习机制中,我们将此称为二进制分类问题。很多商业决策都能够通过准确预测二进制问题的答案来得到强化。Amazon Michine Learning(简称Amazon ML)就提供了一套简单而且成本低廉的选项,帮助大家以快速且规模化的方式找出此类问题的答案。
在今天的文章中,我们将以Kaggle.com网站提供的实例作为起始。这一次,大家可以接触到网络广告行业当中经常涉及的点击率预测案例。在示例当中,大家将预测特定用户点击特定广告的实际可能性。
准备用于构建机器学习模型的数据
直接从Kaggle站点获取数据来构建这套模型当然也是可行的,不过为了强化其现实意义,我们这一次将利用Amazon Redshift作为数据中介。在多数情况下,建立机器学习模型所需要的历史事件数据已经被存储在了数据仓库当中。Amazon ML与Amazon Redshift这套强有力的组合能够帮助大家查询相关事件数据并执行汇聚、加入或者处理等操作,从而为机器学习模型准备好所需的一切数据。我们在后文中将给出与此相关的部分示例。
要顺利完成本次指导教程,大家需要拥有一个AWS账户、一个Kaggle账户(用于下载数据集)、Amazon Redshift集群以及SQL客户端。如果大家还没有建立过Amazon Redshift集群也完全不必担心,现在可以申请到为期两个月的dw2.large单节点集群免费试用期,这足以支持大家完成本次学习。
建立一套Amazon Reshift集群
在AWS管理控制台的Supported Regions(支持区域)列表当中选定US East(美国东部,即北弗吉尼亚州区域),而后在Database部分选择Amazon Redshift。最后选择Launch Cluster(启动集群)。
在接下来的Cluster Details(集群详细信息)页面当中,对该集群及数据库进行命名(可分别为ml-demo与dev),而后输入主用户名及密码。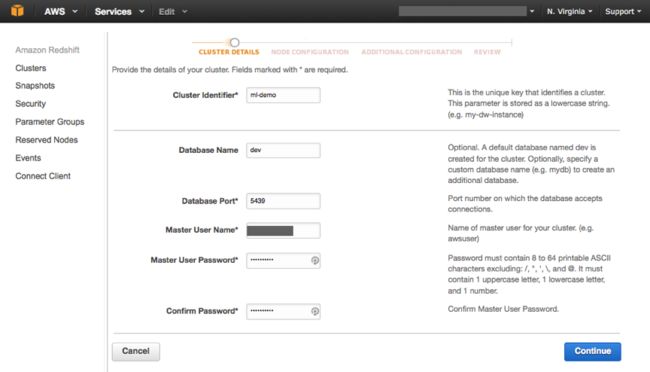
在Node Configuration(节点配置)页面当中,对该集群的布局进行定义。针对本次示例所涉及的数据量,大家只需要单一dc1.large节点即可(并接入至Amazon Redshift免费层级)。

选择Continue,在接下来的页面中审查设置并选择Launch Cluster(启动集群)。几分钟之后,该集群即可正式供大家使用。这时,选定该集群名称并查看其配置信息。
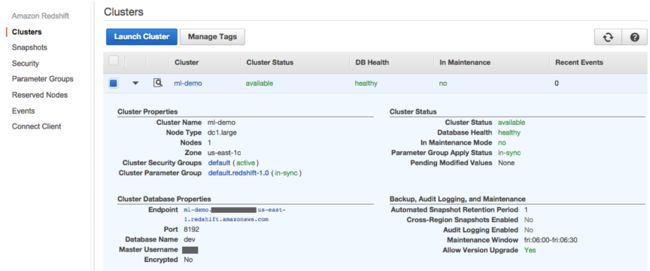
在这里,大家需要注意其中的Endpoint值,要确保其能够接入该集群并使用下载自Kaggle站点的数据。
下载并保存数据
点击此处从Kaggle网站上下载培训文件,而后将其上传至AmazonSimple Storage Service(即Amazon简单存储服务,简称Amazon S3)。由于文件较大,我们需要利用AWS命令行将其进行拆分上传。
# Download the train data from: http://www.kaggle.com/c/avazu-ctr-prediction/download/train.csv.gz # upload the file to S3 aws s3 cp train.csv.gz s3:///click_thru/input/大家可以利用多种SQL客户端与该集群实现对接,例如SQL-Workbench或者Aginity Workbench,当然我们也可以在基于Linux的EC2实例中利用终端内的psql命令实现接入。
ssh -i .pem [email protected] psql -h ml-demo..us-east-1.redshift.amazonaws.com -U -d dev -p 5439 psql -h ml-demo.在我们的SQL客户端内创建一个表,用于保存所有来自Kaggle网站的事件数据。请确保每一列都使用了正确的数据类型。.us-east-1.redshift.amazonaws.com -U -d dev -p 5439
CREATE TABLE click_train ( id varchar(25) not null, click boolean, -- the format is YYMMDDHH but defined it as string hour char(8), C1 varchar(20), banner_pos smallint, site_id varchar(10), site_domain varchar(10), site_category varchar(10), app_id varchar(10), app_domain varchar(10), app_category varchar(10), device_id varchar(10), device_ip varchar(10), device_model varchar(10), device_type integer, device_conn_type integer, C14 integer, C15 integer, C16 integer, C17 integer, C18 integer, C19 integer, C20 integer, C21 integer );在SQL客户端内,使用COPY命令将各事件复制到集群当中:
COPY click_train FROM 's3:///input/click_thru/train.csv.gz' credentials 'aws_access_key_id=;aws_secret_access_key=' GZIP DELIMITER ',' IGNOREHEADER 1;
如果一切工作已准备就绪,大家应该会在使用以下SELECT查询命令后看到现有记录数量已经超过4000万条:
dev=# SELECT count(*) FROM click_train; count ---------- 40428967 (1 row)
利用来自Amazon Redshift的数据构建一套机器学习模型
在之前的文章当中,我们曾经探讨过如何利用来自S3的数据文件构建机器学习模型。事实上,此类数据也可以由来自数据库并转储于SQL内的文件提供。由于SQL转储操作非常常见,因此Amazon ML直接将两类高人气数据库源整合在了一起,也就是Amazon RelationalDatabase Service(即Amazon关系数据库服务,简称Amazon RDS)以及Amazon Redshift。在整合之后,我们能够加快数据获取过程,从而更轻松地直接利用“实时”数据改进机器学习模型。
要利用来自Amazon Redshift的数据构建机器学习模型,我们首先需要允许Amazon ML接入到Amazon Redshift当中。具体操作为运行UNLOAD命令对Amazon S3进行相关查询,而后开始培训流程的下一个阶段。
在IAM控制台当中创建一个名为AML-Redshift的新角色,而后选择Continue。
在Select Role Type(即选择角色类型)页面当中,为Amazon Machine Learning Role for Redshift Data Source选择默认角色类型。
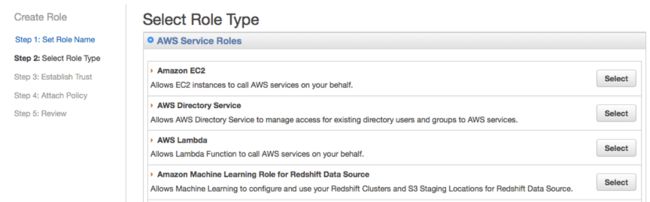
而Attach Policy(即附加策略)页面当中,从列表中选定一种策略而后点击Continue。
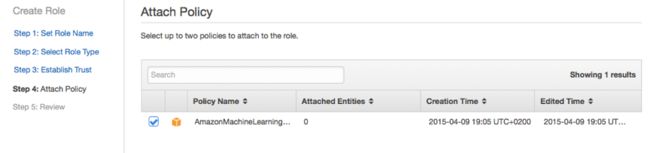
最后,审查新角色的设置信息,复制其中的Role ARN值以备下一步使用,接着选择Create。
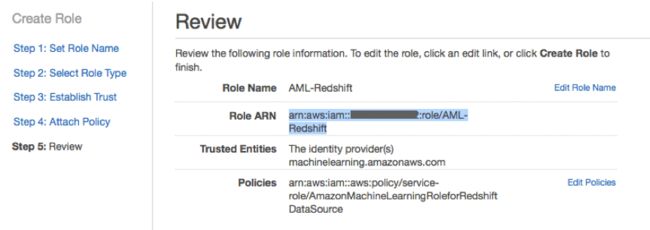
在Amazon Machine Learning控制台当中,选择Create new… Datasource and ML model(即创建新的……数据源与机器学习模型)。
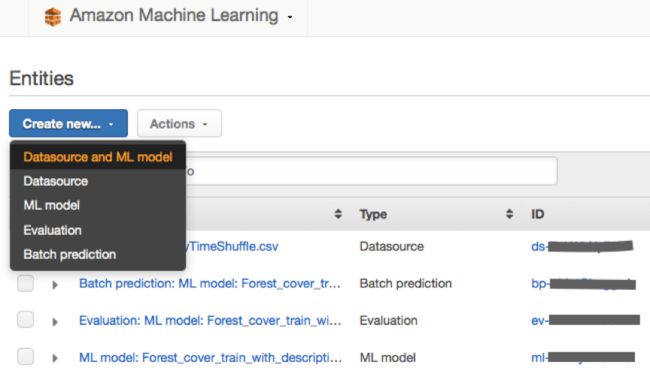
在Data Input(数据输入)页面当中,选择Redshift并填写相关信息,具体包括刚刚创建角色的ARN值、集群名称、数据库名称、用户名以及密码内容。大家还需要指定所要使用的SELECT查询(后文将具体说明)、S3存储桶名称以及作为暂存位置的文件夹。
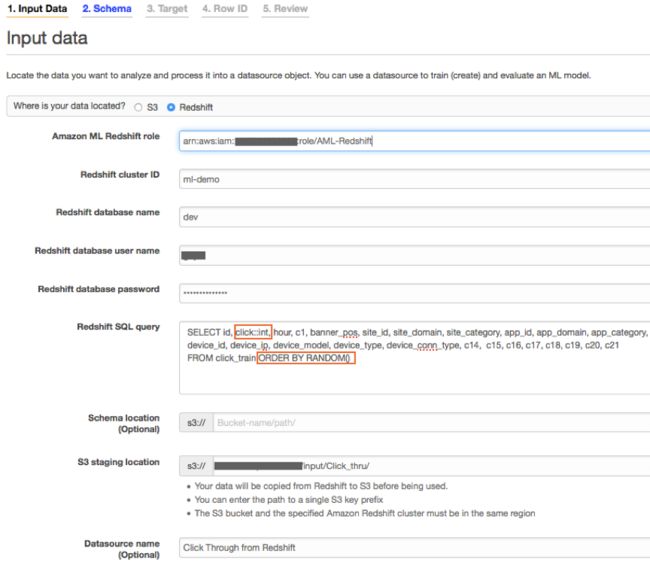
在SQL查询当中,大家需要将二进制目标“点击”作为一个整数值(0或者1),而非false或者true,从而将其转换为int。我们还建议大家利用ORDER BY RANDOM()对记录进行混排,从而避免数据内容的次序影响。
SELECT id, -- target field as 0/1 instead of f/t click::int, hour, c1, banner_pos, site_id, site_domain, site_category, app_id, app_domain, app_category, device_id, device_ip, device_model, device_type, device_conn_type, c14, c15, c16, c17, c18, c19, c20, c21 FROM click_train -- Shuffle the records ORDER BY RANDOM();
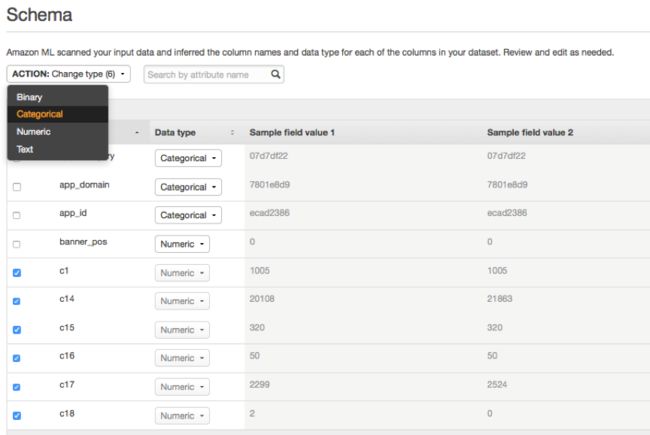
在Amazon ML向导中的Schema页面内,大家可以看到Amazon已经自动从数据内识别出了其模式定义。在这一阶段,我们最好审查各项属性的建议值,同时将用于显示类别ID的数字值变更为“Categorical”。
在Target页面当中,选中“click”项作为目标。
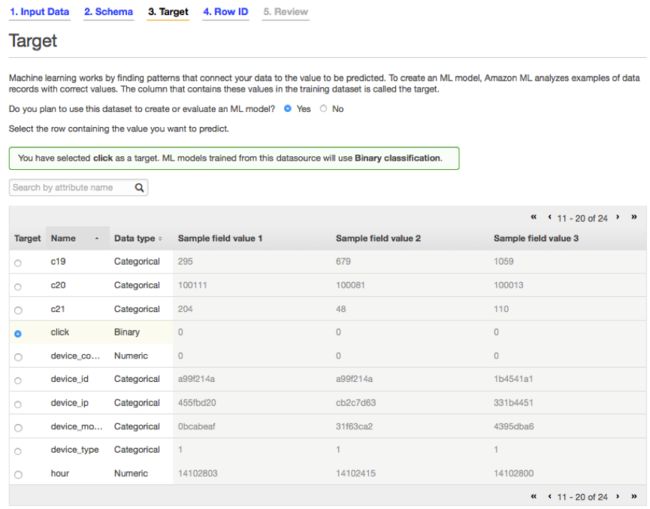
遵循向导继续下一步,定义行ID(id字段)。当进行到Review页面时,选定默认设定以创建这套机器学习模型。在默认情况下,Amazon ML会对数据进行拆分,其中70%被作为模型训练内容、另外30%则被用于模型评估。
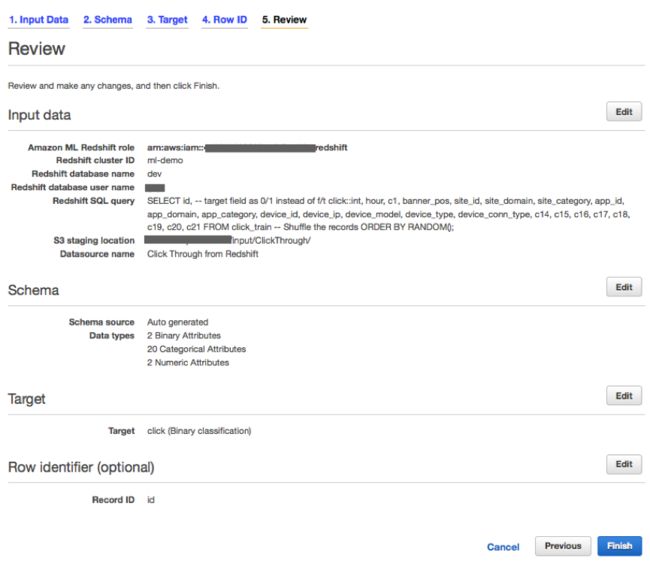
由于存在大量记录需要处理,因此创建数据源、ML模型以及评估的过程可能需要一段时间。大家可以在Amazon ML仪表板当中监控其处理进度。
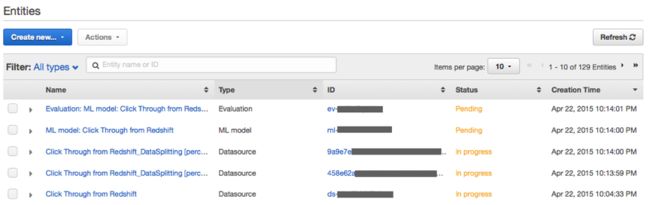
在仪表板当中,大家可以看到我们之前创建的原始数据源已经处于“In progress”即“进行中”状态。该数据源中的70%内容会被作为训练素材,而另外30%则用于模型评估。ML模型创建与评估的当前状态则为“Pending”,即待处理,也就是等待数据源创建工作完成。在整个流程结束后,检查模型评估结果。
评估机器学习模型的准确度
在之前的文章当中,我们曾经探讨过Amazon ML如何通过预测精度指标(单一数字)与图形来报告对应模型的精确程度。
在这一次的二进制分类示例中,预测精度指标被称为AUC(即Area-Under-the-Curve,曲线下面积)。大家可以 点击此处 查看Amazon ML说明文档,从而了解这一临界分值的具体含义。在本次示例中,我们这套方案的得分为0.74: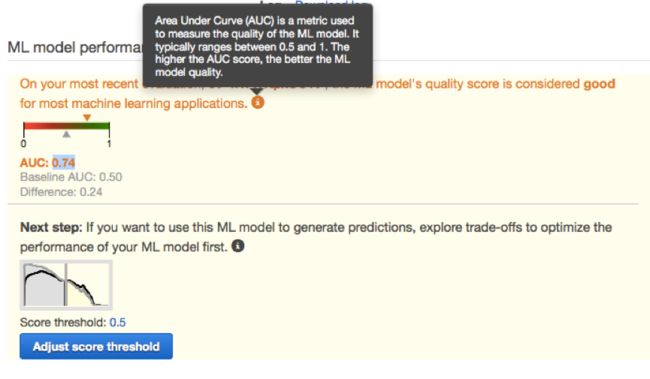
要进一步了解其含义,大家可以点击此处查看Amazon提供的评估结果可视化说明。直接选择总体临界值数字显然更便于大家理解。每条记录的预测临界值都是一个介于0到1之间的数字值。越是接近1,就代表其越可能得到“是”的答案,而相反则代表其更可能得到“否”的答案。结合这一总体临界值数字,对应记录的评估结果可能分为以下四种类别:
· 真阳性(简称TP) – 被正确分类为“是”
· 真阴性(简称TN) – 被正确分类为“否”
· 假阳性(简称FP) – 被错误分类为“是”
· 假阴性(简称FN) – 被错误分类为“否”
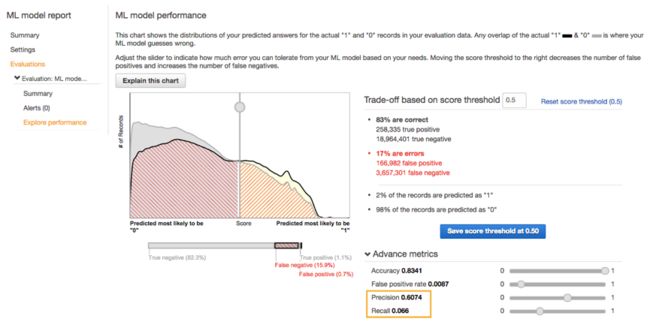
如果大家所获得的整体临界值越接近于1,那就代表着被错误分类为“否”的记录越少,但与此同时被错误分类为“是”的记录可能也就越多。这时候,我们就需要利用该临界值作出商业决策了。如果每一项被错误分类为“是”的记录会产生1美元的成本(假设显示一条广告需要花费1美元),那么显然应该调高该值以避免成本高企。然而如果每条被错误分类为“否”的记录会让我们错失一笔大订单(例如金额达1000美元的豪车购买佣金),那么调高该值显然更加明智。
大家可以如上图所示向左或向右移动滑块来调整这一临界值。向左侧滑动意味着降低该值,这会降低被错误判断为“是”的情况的出现机率,但同时也会造成更多被错误判断为“否”的情况。向右侧滑动以增加该临界值则会导致相反的结果。大家也可以图形下方Advance metrics(高级指标)内的四个滑块对临界值进行全方位控制。不过正所谓“天下没有免费的午餐”,修改其中一项的数值,也会导致其它三项数值出现变化。
· 准确度(Accuracy) –这一指标反映了所有分类预测结果的整体准确比例。提高准确度意味着在两类错误之间寻找平衡点。
· 假阴性比率(FalsePositive Rate) –在全部阴性结果当中,实际为阴性但被错误分类为阳性情况的出现比率。
· 精度(Precision) –全部阳性预测结果当中被正确分类为阳性情况的比率。我们通常利用它来避免预测结果为“是”的记录过多的情况(这可能会造成资金浪费或者让用户对频繁的无关弹窗心生反感)。换句话来说,精度的作用在于衡量大家在决定向某人发送宣传内容时的精确程度,或者当前市场营销预算的花费方式是否合理。感兴趣的朋友可以点击此处查看维基百科当中针对精度与召回提供的说明信息及图片(例如下图)。
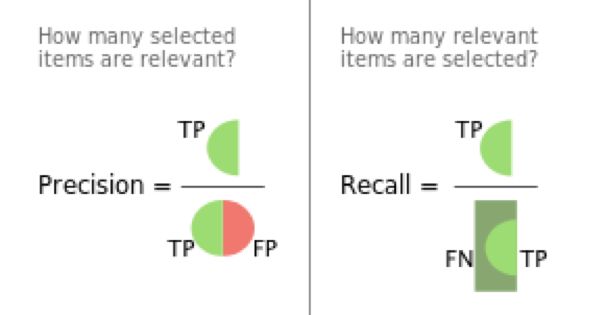
· 召回(Recall) –全部阳性记录当中被正确分别为阳性情况的比率。我们通常利用它来避免预测结果为“否”的记录过多的情况(这可能会导致企业错失销售机会)。换句话来说,它代表着我们能够通过广告宣传实际召回多少可能对内容感兴趣的对象。在以上示例中召回数值为0.06,这意味着只有6%的用户属于我们预期当中的宣传受众(因为他们会实际点击广告内容)。
举例来说,如果我们将召回值设定为0.5,则相当于希望确保看到每条广告的人群当中至少有50%属于既定宣传受众。在这种情况下,结果会如何呢?
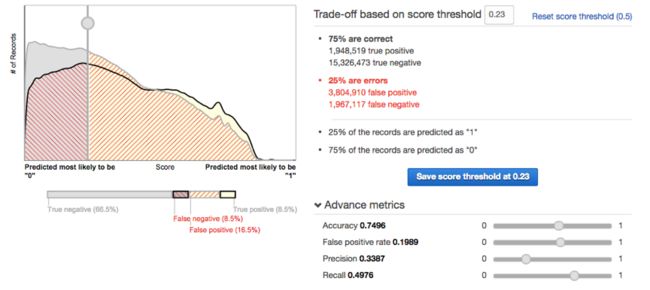
如大家所见,准确度的下降趋势并不明显(则0.83下降到了0.74),但精度则出现了大幅跳水(由0.6递减至0.33),这意味着现在每三位广告接收者中只有一位会实际点击查看——而在原本的设定中,每三位广告接收者中将有两位实际点击查看。这些变更完全来源于临界值的具体调整,而不会影响或者改进模型本身。
大家可以创建更多来自Amazon Redshift的新数据源来改进机器学习模型,例如在数据内包含更多其它相关信息,包括基于客户工作日及时间安排的IP地址变化(这部分信息在Kaggle数据集中并不存在,但在实际生活中往往不难获取),或者每天早、中、晚时段用户的IP地址轮替。下面我们再来看几段示例SELECT查询,了解如何通过修改最大程度利用来自Amazon Redshift数据源的数据:SELECT
id,
click::int,
-- Calculating the date of the week from the Hour string
date_part(dow, TO_DATE (hour, 'YYMMDDHH')) as dow,
-- Creating bins of the hours of the day based on common behaviour
case
when RIGHT(Hour,2) >= '00' and RIGHT (Hour,2) <= '05' then 'Night'
when RIGHT(Hour,2) >= '06' and RIGHT (Hour,2) <= '11' then 'Morning'
when RIGHT(Hour,2) >= '12' and RIGHT (Hour,2) <= '17' then 'Afternoon'
when RIGHT(Hour,2) >= '18' and RIGHT (Hour,2) <= '23' then 'Evening'
else 'Unknown'
end
as day_period
...
要将包含有用户其它类型信息的数据引入这一点击率分析模型,例如性别或者年龄,大家可以对来自Amazon Redshift数据仓库内其它表的数据使用JOIN语句。
总结
在今天的文章中,大家了解了何时以及如何使用由Amazon ML提供的二进制分类机器学习模型。此外,我们也探讨了如何利用Amazon Redshift作为训练数据的数据源、如何选定数据、将目标数据类型转化为int以触发二进制分类、以及如何利用RANDOM函数对数据内容进行混排。
与此同时,大家也接触到了实现二进制分类模型评分所需要的各项指标,包括准确度、精度以及召回等。这些知识将帮助大家顺利构建、评估并修改自己的二进制分类模型,从而切实解决商业运营中的具体问题。
如果大家还有其它问题或者建议,请在评论栏中畅所欲言。
原文链接:
https://blogs.aws.amazon.com/bigdata/post/TxGVITXN9DT5V6/Building-a-Binary-Classification-Model-with-Amazon-Machine-Learning-and-Amazon-R
核子可乐译