Logistic回归及其python代码实现
导录:
-
- 引言
- 引入sigmoid函数
- 二元逻辑回归的损失函数
- 梯度下降法求损失函数极小值
- python实现logistics回归
- 逻辑回归的正则化
- 逻辑回归的优点和缺点
- 小结
- 参考
引言
逻辑回归从名字上看起来是回归问题, 但其是机器学习中的一种分类模型。
之所以叫Logistic回归, 是因为它的算法和线性回归基本上是完全一致的,不同之处在于Logistic回归在线性回归的最后一步的基础上引入了激活函数—sigmoid函数 ,将回归问题变成了0-1的分类问题。
是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
引入sigmoid函数

其函数 图像为:
 )
)
函数的定义域为全体实数,值域在[0,1]之间,x轴在0点对应的结果为0.5。
在执行的时候:g(x)的值大于0.5可以认为是1类问题,反之是0类问题,而刚好是0.5,则可以划分至0类或1类(看个人喜好将其分为哪一类)。
它有一个非常好的性质,即当z趋于正无穷时,g(z)趋于1,而当z趋于负无穷时,g(z)趋于0,这非常适合于我们的分类概率模型。另外,它还有一个很好的导数性质:
g′(z)=g(z)(1−g(z))
如果我们令g(z)中的z为:z=xθ,这样就得到了二元逻辑回归模型的一般形式:
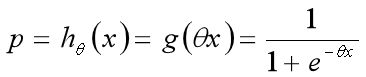
公式中的z=xθ, 我们可以理解为线性回归, 这也就是上面描述的, 在线性回归最后一步引入sigmoid函数, 将回归问题转为分类问题。
其中hθ(X)为模型输出,为 m x1的维度。X为样本特征矩阵,为m x n的维度。θ为分类的模型系数,为n x1的向量。
理解了二元分类回归的模型,接着我们就要看模型的损失函数了,我们的目标是极小化损失函数来得到对应的模型系数θ。
二元逻辑回归的损失函数
对于0-1型二分布变量,
y=1的概率分布公式定义:P(y=0)=p
y=0的概率分布公式定义:P(y=1)=1-p
那么我们有:
P(y=1|x,θ)=hθ(x)
P(y=0|x,θ)=1−hθ(x)
把这两个式子写成一个式子,就是:
P(y|x,θ)=hθ(x)y(1−hθ(x))1-y
其中y的取值只能是0或者1。
得到了y的概率分布函数表达式,我们就可以用似然函数最大化来求解我们需要的模型系数θ。
似然函数的代数表达式为:

其中: 其中m为样本的个数
为了方便求解,这里我们用极大似然法,对数似然函数取反即为我们的损失函数J(θ)。
对似然函数对数化取反的表达式,即损失函数表达式为:

损失函数用矩阵法表达更加简洁:
![]()
其中E为全1向量,●为内积。
梯度下降法求损失函数极小值
对于二元逻辑回归的损失函数极小化,有比较多的方法,最常见的有梯度下降法,坐标轴下降法,等牛顿法等。
这里使用梯度下降法来求解。
这里给出矩阵法推导二元逻辑回归梯度的过程。
我们用J(θ)对θ向量求导可得:


于是得到梯度更新:
![]()
其中,α为梯度下降法的步长, 也可称为学习率。
python实现logistics回归
这是自己写的python实现logistics回归的代码:
import numpy as np
from sklearn.preprocessing import OneHotEncoder
class Logistic:
def __init__(self, max_depth=5000):
self.sep = 0.01
self.onehot = OneHotEncoder()
self.max_depth = max_depth
def fit(self, train_x, train_y):
self.train_x = np.mat(train_x)
m, n = self.train_x.shape
# print(m,n)
self.simple = m # 样本数量
self.W = np.ones((n, 1)) # 初始权重
self.train_y = np.mat(train_y)
if self.train_y.shape[0] == 1:
self.train_y = np.mat(self.train_y.reshape((m, 1)))
self.W = self.Grade() # 最优权重
# 提取训练数据训练特征
def fit_transform(self, train_List, train_y=None):
x = np.array(train_List).T
y = np.array(train_y).T
train_x = self.onehot.fit_transform(x, y)
return train_x, y
def transform(self, test_x):
test_x = np.array(test_x)
return self.onehot.transform(test_x)
# sigmod 函数
def sigmod(self, X):
return 1/(1 + np.exp(-X))
# 梯度下降, 得到最优权重w
def Grade(self):
X = self.train_x
Y = self.train_y
for i in range(self.max_depth):
grad = X.T*(X * self.W - Y) # 梯度
self.W = self.W - self.sep * grad
# print(self.W)
return self.W
def predict(self, test_x):
data_y = self.sigmod(test_x * self.W)
# print(data_y)
predict_y = []
for y in data_y:
if y > 0.5:
predict_y.append(1)
else:
predict_y.append(-1)
return predict_y
if __name__ == '__main__':
train_List = [[1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3],
['S', 'M', 'M', 'S', 'S', 'S', 'M', 'M', 'L', 'L', 'L', 'M', 'M', 'L', 'L', 'L']
]
train_y = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
test_data = [[1, "S"], [2, "S"], [3, "S"]]
Logic = Logistic()
train_x, train_y = Logic.fit_transform(train_List, train_y)
train_x = train_x.toarray() # train_x为稀疏矩阵,转化为array格式
Logic.fit(train_x, train_y)
test_x = Logic.transform(test_data) # test_x为稀疏矩阵,转化为array格式
test_x = test_x.toarray()
print("测试数据为:{}, 预测类别为:{}".format(test_data, Logic.predict(np.mat(test_x))))
运行结果为:
D:\Anacoda\python.exe "D:/python project/python project/机器学习/回归模型/逻辑回归伪代码.py"
测试数据为:[[1, 'S'], [2, 'S'], [3, 'S']], 预测类别为:[-1, -1, -1]
当然, 我们也可以直接调用sklearn中已有的logistics库:
from sklearn.linear_model import LogisticRegression
学习时推荐自己使用python实现一次logistics回归代码,理解执行过程后再调用已有库!
逻辑回归的正则化
二元逻辑回归的L1正则化损失函数表达式如下:
![]()
其中||θ||1为θ的L1范数
逻辑回归的L1正则化损失函数的优化方法常用的有坐标轴下降法和最小角回归法。
二元逻辑回归的L2正则化损失函数表达式如下:
![]()
其中||θ||2为θ的L2范数。
逻辑回归的L2正则化损失函数的优化方法和普通的逻辑回归类似
逻辑回归的优点和缺点
优点:
1)预测结果是介于0和1之间的概率;
2)可以适用于连续性和类别性自变量;
3)容易使用和解释。
缺点:
1)对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
2)预测结果呈“S”型,因此从log(odds)向概率转化的过程是非线性的,在两端随着log(odds)值的变化,概率变化很小,边际值太小,slope太小,而中间概率的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,无法确定阀值。
小结
logistics回归, 是根据线性回归模型, 引入了sigmoid激活函数, 采用极大释然法和梯度下降法来求解参数。
参考
https://www.cnblogs.com/pinard/p/6029432.html