Apache Tika源码研究(三)
上文我们基本知道Tika是通过SAXParser来解析XHTML文档的,下面我通过一个具体的解析类HtmlParser入手,来看看网页文件的解析过程。
首先看看HtmlParser类的继承层次,HtmlParser继承自抽象类AbstractParser,而AbstractParser实现了Parser接口
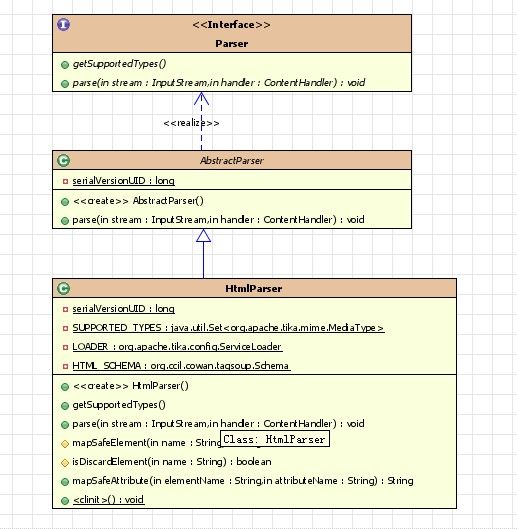
Parser接口声明的方法方法如下:
/** * Tika parser interface. */ public interface Parser extends Serializable { /** * Returns the set of media types supported by this parser when used * with the given parse context. * * @since Apache Tika 0.7 * @param context parse context * @return immutable set of media types */ Set<MediaType> getSupportedTypes(ParseContext context); /** * Parses a document stream into a sequence of XHTML SAX events. * Fills in related document metadata in the given metadata object. * <p> * The given document stream is consumed but not closed by this method. * The responsibility to close the stream remains on the caller. * <p> * Information about the parsing context can be passed in the context * parameter. See the parser implementations for the kinds of context * information they expect. * * @since Apache Tika 0.5 * @param stream the document stream (input) * @param handler handler for the XHTML SAX events (output) * @param metadata document metadata (input and output) * @param context parse context * @throws IOException if the document stream could not be read * @throws SAXException if the SAX events could not be processed * @throws TikaException if the document could not be parsed */ void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException; }
第一个方法返回支持的媒体类型集合
第二个方法为正式的解析方法
抽象类AbstractParser只对上面接口的void parse()方法进行了一层包装,类似于模板方法,方便其他类调用,其代码如下:
public abstract class AbstractParser implements Parser { /** * Serial version UID. */ private static final long serialVersionUID = 7186985395903074255L; /** * Calls the * {@link Parser#parse(InputStream, ContentHandler, Metadata, ParseContext)} * method with an empty {@link ParseContext}. This method exists as a * leftover from Tika 0.x when the three-argument parse() method still * existed in the {@link Parser} interface. No new code should call this * method anymore, it's only here for backwards compatibility. * * @deprecated use the {@link Parser#parse(InputStream, ContentHandler, Metadata, ParseContext)} method instead */ public void parse( InputStream stream, ContentHandler handler, Metadata metadata) throws IOException, SAXException, TikaException { parse(stream, handler, metadata, new ParseContext()); } }
下面来分析HtmlParser类的关键部分,HtmlParser的部分源码如下:
** * HTML parser. Uses TagSoup to turn the input document to HTML SAX events, * and post-processes the events to produce XHTML and metadata expected by * Tika clients. */ public class HtmlParser extends AbstractParser { /** Serial version UID */ private static final long serialVersionUID = 7895315240498733128L; private static final Set<MediaType> SUPPORTED_TYPES = Collections.unmodifiableSet(new HashSet<MediaType>(Arrays.asList( MediaType.text("html"), MediaType.application("xhtml+xml"), MediaType.application("vnd.wap.xhtml+xml"), MediaType.application("x-asp")))); private static final ServiceLoader LOADER = new ServiceLoader(HtmlParser.class.getClassLoader()); /** * HTML schema singleton used to amortise the heavy instantiation time. */ private static final Schema HTML_SCHEMA = new HTMLSchema(); public Set<MediaType> getSupportedTypes(ParseContext context) { return SUPPORTED_TYPES; } public void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException { // Automatically detect the character encoding AutoDetectReader reader = new AutoDetectReader( new CloseShieldInputStream(stream), metadata, LOADER); try { Charset charset = reader.getCharset(); String previous = metadata.get(Metadata.CONTENT_TYPE); if (previous == null || previous.startsWith("text/html")) { MediaType type = new MediaType(MediaType.TEXT_HTML, charset); metadata.set(Metadata.CONTENT_TYPE, type.toString()); } // deprecated, see TIKA-431 metadata.set(Metadata.CONTENT_ENCODING, charset.name()); // Get the HTML mapper from the parse context HtmlMapper mapper = context.get(HtmlMapper.class, new HtmlParserMapper()); // Parse the HTML document org.ccil.cowan.tagsoup.Parser parser = new org.ccil.cowan.tagsoup.Parser(); // TIKA-528: Reuse share schema to avoid heavy instantiation parser.setProperty( org.ccil.cowan.tagsoup.Parser.schemaProperty, HTML_SCHEMA); // TIKA-599: Shared schema is thread-safe only if bogons are ignored parser.setFeature( org.ccil.cowan.tagsoup.Parser.ignoreBogonsFeature, true); parser.setContentHandler(new XHTMLDowngradeHandler( new HtmlHandler(mapper, handler, metadata))); parser.parse(reader.asInputSource()); } finally { reader.close(); } } //其他方法略 }
该类的注释写得很清楚,这里用到了一个TagSoup组件,用来解析HTML的,转换为格式良好的XHTML结构
Set<MediaType> getSupportedTypes(ParseContext context)方法返回支持的媒体类型集合
void parse(InputStream stream, ContentHandler handler,Metadata metadata, ParseContext context)方法即为具体的解析HTML文档的方法
编码识别类AutoDetectReader
AutoDetectReader reader = new AutoDetectReader(new CloseShieldInputStream(stream), metadata, LOADER);
该类继承自BufferedReader,封装了输入流stream,AutoDetectReader类的源码如下:
/** * An input stream reader that automatically detects the character encoding * to be used for converting bytes to characters. * * @since Apache Tika 1.2 */ public class AutoDetectReader extends BufferedReader { private static final ServiceLoader DEFAULT_LOADER = new ServiceLoader(AutoDetectReader.class.getClassLoader()); private static Charset detect( InputStream input, Metadata metadata, List<EncodingDetector> detectors) throws IOException, TikaException { // Ask all given detectors for the character encoding for (EncodingDetector detector : detectors) { Charset charset = detector.detect(input, metadata); if (charset != null) { return charset; } } // Try determining the encoding based on hints in document metadata MediaType type = MediaType.parse(metadata.get(Metadata.CONTENT_TYPE)); if (type != null) { String charset = type.getParameters().get("charset"); if (charset != null) { try { return CharsetUtils.forName(charset); } catch (Exception e) { // ignore } } } throw new TikaException( "Failed to detect the character encoding of a document"); } private final Charset charset; private AutoDetectReader(InputStream stream, Charset charset) throws IOException { super(new InputStreamReader(stream, charset)); this.charset = charset; // TIKA-240: Drop the BOM if present mark(1); if (read() != '\ufeff') { // zero-width no-break space reset(); } } private AutoDetectReader( BufferedInputStream stream, Metadata metadata, List<EncodingDetector> detectors) throws IOException, TikaException { this(stream, detect(stream, metadata, detectors)); } public AutoDetectReader( InputStream stream, Metadata metadata, ServiceLoader loader) throws IOException, TikaException { this(new BufferedInputStream(stream), metadata, loader.loadServiceProviders(EncodingDetector.class)); } public AutoDetectReader(InputStream stream, Metadata metadata) throws IOException, TikaException { this(new BufferedInputStream(stream), metadata, DEFAULT_LOADER); } public AutoDetectReader(InputStream stream) throws IOException, TikaException { this(stream, new Metadata()); } public Charset getCharset() { return charset; } public InputSource asInputSource() { InputSource source = new InputSource(this); source.setEncoding(charset.name()); return source; } }
这里最关键的方法是
static Charset detect(InputStream input, Metadata metadata,List<EncodingDetector> detectors)
通过该方法获取文档的编码类型
List<EncodingDetector>即为编码识别类的集合,源自loader.loadServiceProviders(EncodingDetector.class)方法,加载编码识别类列表
接下来分析ServiceLoader类的源码:
/** * Internal utility class that Tika uses to look up service providers. * * @since Apache Tika 0.9 */ public class ServiceLoader { /** * The default context class loader to use for all threads, or * <code>null</code> to automatically select the context class loader. */ private static volatile ClassLoader contextClassLoader = null; /** * The dynamic set of services available in an OSGi environment. * Managed by the {@link TikaActivator} class and used as an additional * source of service instances in the {@link #loadServiceProviders(Class)} * method. */ private static final Map<Object, Object> services = new HashMap<Object, Object>(); /** * Returns the context class loader of the current thread. If such * a class loader is not available, then the loader of this class or * finally the system class loader is returned. * * @see <a href="https://issues.apache.org/jira/browse/TIKA-441">TIKA-441</a> * @return context class loader, or <code>null</code> if no loader * is available */ static ClassLoader getContextClassLoader() { ClassLoader loader = contextClassLoader; if (loader == null) { loader = ServiceLoader.class.getClassLoader(); } if (loader == null) { loader = ClassLoader.getSystemClassLoader(); } return loader; } /** * Sets the context class loader to use for all threads that access * this class. Used for example in an OSGi environment to avoid problems * with the default context class loader. * * @param loader default context class loader, * or <code>null</code> to automatically pick the loader */ public static void setContextClassLoader(ClassLoader loader) { contextClassLoader = loader; } static void addService(Object reference, Object service) { synchronized (services) { services.put(reference, service); } } static Object removeService(Object reference) { synchronized (services) { return services.remove(reference); } } private final ClassLoader loader; private final LoadErrorHandler handler; private final boolean dynamic; public ServiceLoader( ClassLoader loader, LoadErrorHandler handler, boolean dynamic) { this.loader = loader; this.handler = handler; this.dynamic = dynamic; } public ServiceLoader(ClassLoader loader, LoadErrorHandler handler) { this(loader, handler, false); } public ServiceLoader(ClassLoader loader) { this(loader, LoadErrorHandler.IGNORE); } public ServiceLoader() { this(getContextClassLoader(), LoadErrorHandler.IGNORE, true); } /** * Returns an input stream for reading the specified resource from the * configured class loader. * * @param name resource name * @return input stream, or <code>null</code> if the resource was not found * @see ClassLoader#getResourceAsStream(String) * @since Apache Tika 1.1 */ public InputStream getResourceAsStream(String name) { if (loader != null) { return loader.getResourceAsStream(name); } else { return null; } } /** * Loads and returns the named service class that's expected to implement * the given interface. * * @param iface service interface * @param name service class name * @return service class * @throws ClassNotFoundException if the service class can not be found * or does not implement the given interface * @see Class#forName(String, boolean, ClassLoader) * @since Apache Tika 1.1 */ @SuppressWarnings("unchecked") public <T> Class<? extends T> getServiceClass(Class<T> iface, String name) throws ClassNotFoundException { if (loader == null) { throw new ClassNotFoundException( "Service class " + name + " is not available"); } Class<?> klass = Class.forName(name, true, loader); if (klass.isInterface()) { throw new ClassNotFoundException( "Service class " + name + " is an interface"); } else if (!iface.isAssignableFrom(klass)) { throw new ClassNotFoundException( "Service class " + name + " does not implement " + iface.getName()); } else { return (Class<? extends T>) klass; } } /** * Returns all the available service resources matching the * given pattern, such as all instances of tika-mimetypes.xml * on the classpath, or all org.apache.tika.parser.Parser * service files. */ public Enumeration<URL> findServiceResources(String filePattern) { try { Enumeration<URL> resources = loader.getResources(filePattern); return resources; } catch (IOException ignore) { // We couldn't get the list of service resource files List<URL> empty = Collections.emptyList(); return Collections.enumeration( empty ); } } /** * Returns all the available service providers of the given type. * * @param iface service provider interface * @return available service providers */ public <T> List<T> loadServiceProviders(Class<T> iface) { List<T> providers = new ArrayList<T>(); providers.addAll(loadDynamicServiceProviders(iface)); providers.addAll(loadStaticServiceProviders(iface)); return providers; } /** * Returns the available dynamic service providers of the given type. * The returned list is newly allocated and may be freely modified * by the caller. * * @since Apache Tika 1.2 * @param iface service provider interface * @return dynamic service providers */ @SuppressWarnings("unchecked") public <T> List<T> loadDynamicServiceProviders(Class<T> iface) { List<T> providers = new ArrayList<T>(); if (dynamic) { synchronized (services) { for (Object service : services.values()) { if (iface.isAssignableFrom(service.getClass())) { providers.add((T) service); } } } } return providers; } /** * Returns the available static service providers of the given type. * The providers are loaded using the service provider mechanism using * the configured class loader (if any). The returned list is newly * allocated and may be freely modified by the caller. * * @since Apache Tika 1.2 * @param iface service provider interface * @return static service providers */ @SuppressWarnings("unchecked") public <T> List<T> loadStaticServiceProviders(Class<T> iface) { List<T> providers = new ArrayList<T>(); if (loader != null) { List<String> names = new ArrayList<String>(); String serviceName = iface.getName(); Enumeration<URL> resources = findServiceResources("META-INF/services/" + serviceName); for (URL resource : Collections.list(resources)) { try { collectServiceClassNames(resource, names); } catch (IOException e) { handler.handleLoadError(serviceName, e); } } for (String name : names) { try { Class<?> klass = loader.loadClass(name); if (iface.isAssignableFrom(klass)) { providers.add((T) klass.newInstance()); } } catch (Throwable t) { handler.handleLoadError(name, t); } } } return providers; } private static final Pattern COMMENT = Pattern.compile("#.*"); private static final Pattern WHITESPACE = Pattern.compile("\\s+"); private void collectServiceClassNames(URL resource, Collection<String> names) throws IOException { InputStream stream = resource.openStream(); try { BufferedReader reader = new BufferedReader(new InputStreamReader(stream, "UTF-8")); String line = reader.readLine(); while (line != null) { line = COMMENT.matcher(line).replaceFirst(""); line = WHITESPACE.matcher(line).replaceAll(""); if (line.length() > 0) { names.add(line); } line = reader.readLine(); } } finally { stream.close(); } } }
ServiceLoader类的主要功能是加载服务类,分为动态加载服务类和静态加载服务类,分别对应List<T> loadDynamicServiceProviders(Class<T> iface)方法和List<T> loadStaticServiceProviders(Class<T> iface)方法
HtmlParser类的私有成员static final ServiceLoader LOADER =new ServiceLoader(HtmlParser.class.getClassLoader())是只调用静态加载方法
List<T> loadStaticServiceProviders(Class<T> iface)方法(this.dynamic值为false)
加载jar文件里面路径为META-INF/services/org.apache.tika.detect.EncodingDetector的文件
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. org.apache.tika.parser.html.HtmlEncodingDetector org.apache.tika.parser.txt.UniversalEncodingDetector org.apache.tika.parser.txt.Icu4jEncodingDetector
通过加载该文件获取编码识别类列表,最后AutoDetectReader类调用static Charset detect(InputStream input, Metadata metadata,List<EncodingDetector> detectors)方法获取文档的编码类型
至于TagSoup组件我这里转载一篇博文供参考:
TagSoup开发指南
http://cactus-jing.iteye.com/blog/1070620
对于TagSoup可能有些人会比较陌生,TagSoup是Java语言开发的,通过SAX引擎解析结构糟糕、令人抓狂的不规范HTML文档的小工具。TagSoup可以将一个HTML文档转换为结构良好的XML文档(近似于XHTML),方便开发人员对获取的HTML文档进行解析等操作。同时TagSoup提供了命令行程序,可以运行TagSoup来对HTML文档进行解析。
但是TagSoup的缺陷就是,官方网站( http://home.ccil.org/~cowan/XML/tagsoup/)上不提供API文档的链接,同时也不提供开发指南,只提供了一个40页的幻灯片( http://home.ccil.org/~cowan/XML/tagsoup/),是其在Extreme Markup Languages 2004上的演讲。这对于将TagSoup整合到自己的应用程序中还是遇到了很大的挑战!
使用TagSoup的开发流程:
由于个人能力有限,这几句话把我直接搞懵了,所以决定仔细研究下。
TagSoup包含2个包、16个类文件(文件数目还是比较少的,但是功能很强大!)。其中核心类包括Parser、PYXScanner、XMLWriter。
但是TagSoup的缺陷就是,官方网站( http://home.ccil.org/~cowan/XML/tagsoup/)上不提供API文档的链接,同时也不提供开发指南,只提供了一个40页的幻灯片( http://home.ccil.org/~cowan/XML/tagsoup/),是其在Extreme Markup Languages 2004上的演讲。这对于将TagSoup整合到自己的应用程序中还是遇到了很大的挑战!
使用TagSoup的开发流程:
- 创建Parser实例;
- 提供自己的SAX2内容处理器
- 提供只想需要解析的HTML的InputSource实例;
- 开始parse()!
由于个人能力有限,这几句话把我直接搞懵了,所以决定仔细研究下。
TagSoup包含2个包、16个类文件(文件数目还是比较少的,但是功能很强大!)。其中核心类包括Parser、PYXScanner、XMLWriter。
- org.ccil.cowan.tagsoup.Parser,该类继承自org.xml.sax.helpers.DefaultHandler,可知该类是一个SAX型的解析器;
- org.ccil.cowan.tagsoup.PYXScanner,该类实现了Scanner接口,用于读取解析后的内容;
- org.ccil.cowan.tagsoup.XMLWriter,该类继承自org.xml.sax.helpers.XMLFilterImpl,同时实现org.xml.sax.ContentHandler接口(这个是最主要的),也就是说XMLWriter是TagSoup为我们提供的HTML解析成XML文档的默认实现。
StringReader xmlReader = new StringReader(""); StringReader sr = new StringReader(html); InputSource src = new InputSource(sr);//构建InputSource实例 Parser parser = new Parser();//实例化Parse XMLWriter writer = new XMLWriter();//实例化XMLWriter,即SAX内容处理器 parser.setContentHandler(writer);//设置内容处理器 parser.parse(src);//解析 Scanner scan = new PYXScanner(); scan.scan(xmlReader, parser);//通过xmlReader读取解析后的结果 char[] buff = new char[1024]; while(xmlReader.read(buff) != -1) { System.out.println(new String(buff));//打印解析后的结构良好的HTML文档 }
tagsoup-1.2.jar (87.9 KB)