Apache Tika源码研究(六)
上文还没有来得及分析Apache Tika是怎样检测文档的mime类型的,以及怎样根据mime类型找到相应的Parser解析类的,下面接着说
在tika-parsers.jar路径文件META-INF/services/org.apache.tika.detect.Detector记录了tika提供的mime类型检测类,当然tika还有部分mime类型检测类该文件并没有记录,后面我通过分析源码可以获知。
该文件包含的检测类我们先睹为快:
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. org.apache.tika.parser.microsoft.POIFSContainerDetector org.apache.tika.parser.pkg.ZipContainerDetector
注意还有vorbis-java-tika-X.jar的同名路径下也存在该文件,tika都会加载进来,所以共包含了三个实现类
org.apache.tika.parser.microsoft.POIFSContainerDetector
org.apache.tika.parser.pkg.ZipContainerDetector
org.gagravarr.tika.OggDetector
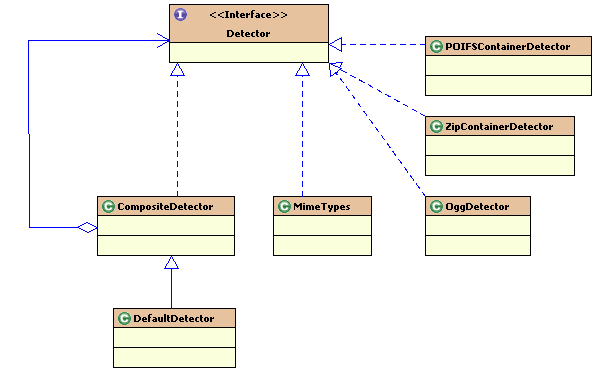
这些tika文档mime类型检测类共同实现了Detector接口:
最重要的文件的mime类型检测相关接口和类的UML图如下:
Detector接口源码:
/** * Content type detector. Implementations of this interface use various * heuristics to detect the content type of a document based on given * input metadata or the first few bytes of the document stream. * * @since Apache Tika 0.3 */ public interface Detector extends Serializable { /** * Detects the content type of the given input document. Returns * <code>application/octet-stream</code> if the type of the document * can not be detected. * <p> * If the document input stream is not available, then the first * argument may be <code>null</code>. Otherwise the detector may * read bytes from the start of the stream to help in type detection. * The given stream is guaranteed to support the * {@link InputStream#markSupported() mark feature} and the detector * is expected to {@link InputStream#mark(int) mark} the stream before * reading any bytes from it, and to {@link InputStream#reset() reset} * the stream before returning. The stream must not be closed by the * detector. * <p> * The given input metadata is only read, not modified, by the detector. * * @param input document input stream, or <code>null</code> * @param metadata input metadata for the document * @return detected media type, or <code>application/octet-stream</code> * @throws IOException if the document input stream could not be read */ MediaType detect(InputStream input, Metadata metadata) throws IOException; }
实现该接口的最重要的类是CompositeDetector,该类并不提供具体的mime类型检测,而是调用其他的实现类进行mime类型检测,供tika其他类调用
/** * Content type detector that combines multiple different detection mechanisms. */ public class CompositeDetector implements Detector { /** * Serial version UID */ private static final long serialVersionUID = 5980683158436430252L; private final MediaTypeRegistry registry; private final List<Detector> detectors; public CompositeDetector( MediaTypeRegistry registry, List<Detector> detectors) { this.registry = registry; this.detectors = detectors; } public CompositeDetector(List<Detector> detectors) { this(new MediaTypeRegistry(), detectors); } public CompositeDetector(Detector... detectors) { this(Arrays.asList(detectors)); } public MediaType detect(InputStream input, Metadata metadata) throws IOException { MediaType type = MediaType.OCTET_STREAM; for (Detector detector : getDetectors()) { MediaType detected = detector.detect(input, metadata); if (registry.isSpecializationOf(detected, type)) { type = detected; } } return type; } /** * Returns the component detectors. */ public List<Detector> getDetectors() { return Collections.unmodifiableList(detectors); } }
构造函数CompositeDetector(MediaTypeRegistry registry, List<Detector> detectors)用于初始化成员变量MediaTypeRegistry registry和List<Detector> detectors
MediaTypeRegistry registry成员注册了系统提供的mime类型,List<Detector> detectors成员为系统的Detector实现类集合
MediaType detect(InputStream input, Metadata metadata)方法遍历Detector集合检测InputStream input的mime类型
CompositeDetector还有一个派生类DefaultDetector,用于初始化CompositeDetector的成员变量
public class DefaultDetector extends CompositeDetector { /** Serial version UID */ private static final long serialVersionUID = -8170114575326908027L; /** * Finds all statically loadable detectors and sort the list by name, * rather than discovery order. Detectors are used in the given order, * so put the Tika parsers last so that non-Tika (user supplied) * parsers can take precedence. * * @param loader service loader * @return ordered list of statically loadable detectors */ private static List<Detector> getDefaultDetectors( MimeTypes types, ServiceLoader loader) { List<Detector> detectors = loader.loadStaticServiceProviders(Detector.class); Collections.sort(detectors, new Comparator<Detector>() { public int compare(Detector d1, Detector d2) { String n1 = d1.getClass().getName(); String n2 = d2.getClass().getName(); boolean t1 = n1.startsWith("org.apache.tika."); boolean t2 = n2.startsWith("org.apache.tika."); if (t1 == t2) { return n1.compareTo(n2); } else if (t1) { return 1; } else { return -1; } } }); // Finally the Tika MimeTypes as a fallback detectors.add(types); return detectors; } private transient final ServiceLoader loader; public DefaultDetector(MimeTypes types, ServiceLoader loader) { super(types.getMediaTypeRegistry(), getDefaultDetectors(types, loader)); this.loader = loader; } public DefaultDetector(MimeTypes types, ClassLoader loader) { this(types, new ServiceLoader(loader)); } public DefaultDetector(ClassLoader loader) { this(MimeTypes.getDefaultMimeTypes(), loader); } public DefaultDetector(MimeTypes types) { this(types, new ServiceLoader()); } public DefaultDetector() { this(MimeTypes.getDefaultMimeTypes()); } @Override public List<Detector> getDetectors() { if (loader != null) { List<Detector> detectors = loader.loadDynamicServiceProviders(Detector.class); detectors.addAll(super.getDetectors()); return detectors; } else { return super.getDetectors(); } } }
List<Detector> getDefaultDetectors(MimeTypes types, ServiceLoader loader)方法加载静态的Detector实现类,而List<Detector> getDetectors()方法加载动态的Detector实现类并包含父类的Detector实现类集合
我们这里注意到,前者额外调用了detectors.add(types),将MimeTypes types对象也添加到集合里面,因为MimeTypes类是实现了Detector接口的,前面文章我已经提到过。
所以实际用到的解析类包括四个
org.apache.tika.parser.microsoft.POIFSContainerDetector
org.apache.tika.parser.pkg.ZipContainerDetector
org.gagravarr.tika.OggDetector
org.apache.tika.mime.MimeTypes
现在我们该如何调用呢,
public static void main(String[] args) throws IOException { // TODO Auto-generated method stub ServiceLoader loader = new ServiceLoader(); MimeTypes mimeTypes = MimeTypes.getDefaultMimeTypes(); Detector detector=new DefaultDetector(mimeTypes, loader); File file=new File("[文件路径]"); InputStream stream = null; try { stream=new BufferedInputStream(new FileInputStream(file)); MediaType type =detector.detect(stream, new Metadata()); System.out.println("mime类型:"+type.toString()); } finally { if (stream != null) stream.close(); } }
现在还有tika怎样加载Parser实现类的,怎样根据文档的mime类型调用相应的Parser实现类的还没有进行分析,不过这些都相对容易分析了,下文再继续吧。