Apache Tika源码研究(八)
本文主要分析tika的语言检测以及tika解决随机访问读取的问题,由于语言检测功能的实现设计一些算法,我这里就不贴出tika的源码了
tika的语言检测的相关接口和类的uml模型图如下
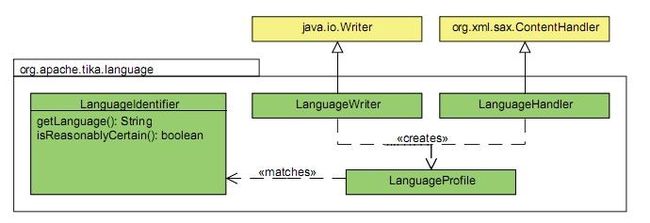
如果要获取文档内容和语言,我们可以新增DelegatingParser解析类,继承自DelegatingParser,代码如下:
public class LanguageDetectingParser extends DelegatingParser { /** * */ private static final long serialVersionUID = 1L; public void parse( InputStream stream, ContentHandler handler, final Metadata metadata, ParseContext context) throws SAXException, IOException, TikaException { ProfilingHandler profiler =new ProfilingHandler(); ContentHandler tee =new TeeContentHandler(handler, profiler); super.parse(stream, tee, metadata, context); LanguageIdentifier identifier = profiler.getLanguage(); if (identifier.isReasonablyCertain()) { metadata.set(Metadata.LANGUAGE, identifier.getLanguage()); } } protected Parser getDelegateParser(ParseContext context) { return context.get(Parser.class, new AutoDetectParser()); } }
关于tika里面InputStream输入流随机访问的封装,我们可以看到AutoDetectParser类的parser方法里面的TikaInputStream类
public void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException { TemporaryResources tmp = new TemporaryResources(); try { TikaInputStream tis = TikaInputStream.get(stream, tmp); // Automatically detect the MIME type of the document MediaType type = detector.detect(tis, metadata); metadata.set(Metadata.CONTENT_TYPE, type.toString()); // TIKA-216: Zip bomb prevention SecureContentHandler sch = new SecureContentHandler(handler, tis); try { // Parse the document super.parse(tis, sch, metadata, context); } catch (SAXException e) { // Convert zip bomb exceptions to TikaExceptions sch.throwIfCauseOf(e); throw e; } } finally { tmp.dispose(); } }
它的具体机制是将InputStream处理到临时文件,这里我不再贴出其源码
因为有时我们需要InputStream重复使用,这里tika封装对其进行了封装TikaInputStream类,典型的应用场景如我们先要根据InputStream检测文档的编码类型,然后还要进一步对该InputStream进行解析
public static void main(String[] args) throws IOException, TikaException { // TODO Auto-generated method stub File file=new File("E:\\watiao.htm"); InputStream stream=TikaInputStream.get(file); try { EncodingDetector detector=new UniversalEncodingDetector(); Charset charset = detector.detect(stream, new Metadata()); System.out.println("编码2:"+charset.name()); //进一步解析 } finally { if (stream != null) stream.close(); } }
本系列tika源码解析的文章系本人原创,本人参考了《Tika in Action》英文版,以后如有心得再继续补充。
转载请注明出处 博客园 刺猬的温驯
本文链接 http://www.cnblogs.com/chenying99/archive/2013/03/11/2953365.html