WWW2020《Adversarial Attacks on Graph Neural Networks via Node Injections:分层增强学习方法》(NIPA)论文详解
论文链接:https://faculty.ist.psu.edu/vhonavar/Papers/www20.pdf
poisoning attack
1 Abstract and Introduction
本文考虑了一种针对图数据的节点注入中毒攻击(poisoning attack)的形式。对节点注入攻击的关键步骤进行建模,例如,通过马尔可夫决策过程(MDP)在注入的对抗节点和其他节点之间建立链接、选择注入节点的标签等。本文提出了一种针对节点注入中毒攻击(Node Injection Poisoning Attacks,NIPA)的增强学习方法,可以在不改变现有节点之间连接的情况下,顺序修改被注射节点的标签和链接。具体来说,引入一个分层的 Q-learning 网络来操作图中敌对节点的标签及其与其他节点的联系,并设计一个适当的奖励函数来引导强化学习 agent,以降低GNN的节点分类性能。
本文研究基于节点注入的中毒攻击问题。面临两个挑战:(ii)如何在注入的对抗(伪)节点与原始图中的现有节点或其他注入的对抗节点之间建立数学模型并有效建立联系。(ii)如何有效地解决图的离散和高度非线性的优化问题。采用 Q-learning 也自然地解决了离散优化的挑战,因为现在我们协调离散边缘添加过程作为强化学习框架的行动。为了减少搜索空间,NIPA 采用分级 Q-learning 网络对动作进行分解。为了应对图的高度非线性,NIPA 由深度 Q network 和基于 GNN 的状态表示方法组成。 这些组件可以学习图的语义结构并将离散图结构转换为潜在表示。
contributions:
一种新的图节点注入攻击方法。NIPA成功地解决了由此产生的强化学习问题所带来的几个重大挑战。在真实世界数据集的无目标攻击具有较好的效果(比当时之前的 SOTA 要好)。
2 Related Work
本文的研究属于对机器学习的数据中毒攻击的一般领域,其目的是破坏数据,从而对基于数据训练的预测模型的性能产生不利影响。很少有人关注如何毒害图结构数据。本文的重点是对这类基于图结构数据训练的分类器的攻击。
2.1 Adversarial Attack on GNN
2.2 Reinforcement Learning in Graph
与本文最相似的工作是 RL-S2V,它通过操纵已有节点之间的链接,采用增强学习的方法对图进行有目标规避攻击(targeted evasion attack)。RL-S2V 与本文所提出方法的不同之处在于:(1)攻击场景不同,本文是无目标中毒攻击,RL-S2V 是有目标规避攻击。(2)增强学习的 agent 有不同的任务:RL-S2V 学习通过修改原图内在结构来攻击图中特定的节点,本文提出的 agent 生成对抗连接,并为注入的伪节点设计标签。(3)本文设计了不同的奖励函数来驱动 agent。本文探讨了增强学习模型在新型无目标中毒攻击场景中的应用。
3 Node Injection Poisoning Attacks on Graph Data
3.1 Problem Definition
Definition 3.1(Semi-Supervised Node Classification)
属性图![]() ,节点集
,节点集![]() ,边集
,边集![]() ,节点特征
,节点特征![]() 。有标签节点集
。有标签节点集![]() ,无标签节点集
,无标签节点集![]() ,有标签节点集和无标签节点集组成所有节点
,有标签节点集和无标签节点集组成所有节点![]() 。半监督节点分类任务旨在用图分类器
。半监督节点分类任务旨在用图分类器 正确标注
正确标注![]() 中的无标签节点。
中的无标签节点。
在半监督节点分类任务中, 学习映射![]() 的图分类器
的图分类器![]() 旨在通过聚合结构和特征信息正确地将标签分配到节点
旨在通过聚合结构和特征信息正确地将标签分配到节点![]() 。分类器由 θ 参数化,表示为
。分类器由 θ 参数化,表示为![]() 。为简便起见,使用
。为简便起见,使用![]() 作为对
作为对![]() 预测的分类器,
预测的分类器,![]() 作为
作为![]() 的真实标签。在训练过程中,目标是学习最优分类器,对应的参数
的真实标签。在训练过程中,目标是学习最优分类器,对应的参数![]() 定义如下:
定义如下:

![]() 是如交叉熵的损失函数。对分类器的攻击主要有两种攻击设置:中毒/训练时攻击和逃避/测试时攻击。在中毒攻击中,分类器使用毒化的图进行训练;在逃避攻击中,在干净图上进行训练后,测试样本中包含敌对样例。本文关注无目标图中毒攻击问题,攻击者
是如交叉熵的损失函数。对分类器的攻击主要有两种攻击设置:中毒/训练时攻击和逃避/测试时攻击。在中毒攻击中,分类器使用毒化的图进行训练;在逃避攻击中,在干净图上进行训练后,测试样本中包含敌对样例。本文关注无目标图中毒攻击问题,攻击者 在训练时间之前对图进行毒化,以降低图分类器对未标记节点集
在训练时间之前对图进行毒化,以降低图分类器对未标记节点集![]() 的性能。
的性能。
Definition 3.2(Graph non-Targeted Poisoning Attack)
给定属性图 ,有标签节点集
,有标签节点集![]() 、无标签节点集
、无标签节点集![]() 和图分类器
和图分类器![]() ,攻击者的目的是在预算(budget) ∆ 内修改图
,攻击者的目的是在预算(budget) ∆ 内修改图![]() ,以降低分类器对
,以降低分类器对![]() 的准确性。
的准确性。
由于攻击过程应该是不引人注意的,攻击者对![]() 允许的修改次数受限于预算 ∆。基于该问题,本文提出了节点注射中毒方法,将一组敌对节点
允许的修改次数受限于预算 ∆。基于该问题,本文提出了节点注射中毒方法,将一组敌对节点![]() 注入到节点集
注入到节点集![]() 中,对图进行无目标中毒攻击。
中,对图进行无目标中毒攻击。
Definition 3.3(Node Injection Posioning Attack)
给定属性图,攻击者把带有属性![]() 的对抗节点集
的对抗节点集![]() 和标签
和标签![]() 注入到干净节点集
注入到干净节点集![]() 。在注入
。在注入![]() 后,攻击者创造对抗边
后,攻击者创造对抗边![]() 来毒化
来毒化![]() 。
。![]() 是毒化后的图,其中
是毒化后的图,其中![]() ,
, 是追加操作,
是追加操作,![]() 是带标签集且
是带标签集且![]() 。 在中毒攻击中,将图分类器在毒化后的图
。 在中毒攻击中,将图分类器在毒化后的图![]() 上进行训练。
上进行训练。
根据以上定义和符号,定义无目标节点注入中毒攻击的目标函数为:
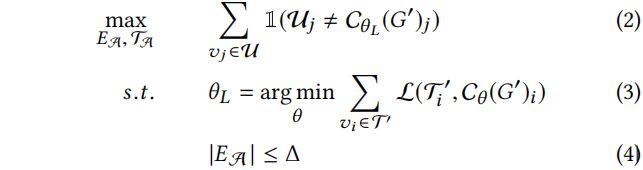
![]() 是指示函数,如果 s 为真,则
是指示函数,如果 s 为真,则![]() ,反之为 0。
,反之为 0。![]() 表示无标签节点
表示无标签节点![]() 的标签。 如果攻击者拥有无标签数据的真实值(本例中无标签的是终端用户),则
的标签。 如果攻击者拥有无标签数据的真实值(本例中无标签的是终端用户),则![]() 是真实标签。攻击者最大化如 Eq.(2) 中未标记节点
是真实标签。攻击者最大化如 Eq.(2) 中未标记节点![]() 的预测误差,受两个约束。约束(3)强制分类器是从被毒化的图
的预测误差,受两个约束。约束(3)强制分类器是从被毒化的图![]() 学习到的。 约束(4)限制攻击者在预算 ∆ 内对敌对边的修改。但是,如果攻击者没有访问真实值,攻击者就不能直接使用对象函数。有两种替代方案:一是最大化带标签(训练)节点上的损失;另一种是采用自学习,即使用这些预测的标签并计算在无标签节点上的模型损失。
学习到的。 约束(4)限制攻击者在预算 ∆ 内对敌对边的修改。但是,如果攻击者没有访问真实值,攻击者就不能直接使用对象函数。有两种替代方案:一是最大化带标签(训练)节点上的损失;另一种是采用自学习,即使用这些预测的标签并计算在无标签节点上的模型损失。
Notes:Eq.(2) 尽量使在注入节点后无标签节点的标签与真实标签不同。其限制 Eq.(3)、Eq.(4) 为使得有标签数据预测的准确同时修改的边要满足预算 Δ。
3.2 Graph Convolution Network
![]()
4 Proposed Framework
为了进行无目标节点注入中毒攻击,本文提出通过深度强化学习求解 Eq.(2) 中的优化问题。与传统的矩阵优化技术直接优化邻接矩阵相比,采用深度强化学习具有两方面的优势:(i)添加边和设计伪节点的标签是自然的顺序决策过程。(ii)图的底层结构通常是高度非线性的,这增加了决策过程的非线性。Q network 的深度非线性神经网络可以更好地捕捉图的非线性,学习图的语义,从而做出更好的决策。
如图 2 所示,本文提出的框架的关键思想是训练深度强化学习 agent,它可以迭代地执行动作来毒害图。这些操作包括添加对抗性边和修改被注入节点的标签。更具体地说,该 agent 需要从注入的节点集![]() 中提取一个节点,并从被毒化的节点集
中提取一个节点,并从被毒化的节点集![]() 中选择另一个节点以添加对抗性的边缘,并修改注入节点的标签来攻击分类器。为此,本文设计了强化学习环境,并根据优化函数进行奖励。
中选择另一个节点以添加对抗性的边缘,并修改注入节点的标签来攻击分类器。为此,本文设计了强化学习环境,并根据优化函数进行奖励。

4.1 Attacking Environment
将所提出的中毒攻击过程建模为有限水平马尔可夫决策过程(Finite Horizon Markov Decision Process)![]() 。MDP 的定义包含状态空间 S、动作集 A、转移概率 P、奖励R、折扣因子 γ。
。MDP 的定义包含状态空间 S、动作集 A、转移概率 P、奖励R、折扣因子 γ。
4.1.1 State. 状态![]() 包含中间毒化的图
包含中间毒化的图![]() 和注入节点在时刻 t 的标签信息
和注入节点在时刻 t 的标签信息![]() 。为了捕捉毒化图
。为了捕捉毒化图![]() 的高度非线性信息和非欧式结构,通过设计图神经网络把
的高度非线性信息和非欧式结构,通过设计图神经网络把![]() 嵌入到聚合图结构信息的
嵌入到聚合图结构信息的![]() 中。
中。![]() 使用神经网络对对抗性标签信息
使用神经网络对对抗性标签信息![]() 进行编码。由于在注入中毒环境中,节点集
进行编码。由于在注入中毒环境中,节点集![]() 保持相同,因此 DRL(Deep Reinforcement Learning)agent 实际上在边集
保持相同,因此 DRL(Deep Reinforcement Learning)agent 实际上在边集![]() 上执行毒化。
上执行毒化。
4.1.2 Action. 在中毒攻击环境中,允许 agent 在(1)被注入的节点![]() 内部或被注入的节点与干净的节点之间添加对抗性边;(2)设计注入节点的对抗标签。但是,直接增加一条对抗边有
内部或被注入的节点与干净的节点之间添加对抗性边;(2)设计注入节点的对抗标签。但是,直接增加一条对抗边有![]() 种可能的选择且修改一个注入节点的标签需要
种可能的选择且修改一个注入节点的标签需要![]() 空间,其中
空间,其中![]() 是标签类别的数量。因此,执行同时包含添加敌对边和更改节点标签的操作时,搜索空间为
是标签类别的数量。因此,执行同时包含添加敌对边和更改节点标签的操作时,搜索空间为![]() ,这是极其昂贵,尤其是在大型图中。因此,本文采用分层次的 action 来分解这种 action,减少行为空间。
,这是极其昂贵,尤其是在大型图中。因此,本文采用分层次的 action 来分解这种 action,减少行为空间。
如图 2 所示,在 NIPA 中,在时刻 t,agent 首先执行行为![]() 来从
来从![]() 中选择注入节点。然后 agent 通过
中选择注入节点。然后 agent 通过![]() 从整个节点集
从整个节点集![]() 中选择另一个节点。在执行
中选择另一个节点。在执行 ![]() 和
和![]() 后,agent 连接两个选择的节点来构造图 2 中虚线所表示的对抗边。最后,agent 通过行为
后,agent 连接两个选择的节点来构造图 2 中虚线所表示的对抗边。最后,agent 通过行为![]() 设计选择的伪节点的标签。通过这样的分层行为
设计选择的伪节点的标签。通过这样的分层行为![]() ,行为空间由
,行为空间由![]() 减少为
减少为![]() 。通过层次行为
。通过层次行为![]() ,所提出的 MDP 的轨迹为
,所提出的 MDP 的轨迹为![]() 。
。
4.1.3 Policy Network. 之前的研究及本文初步实验都表明 Q-learning 比其他诸如 Advantage Actor Critic 的策略优化方法要稳定,本文专注于用 Q-learning 建模策略网络。Q-learning 找到了一个最优策略,它从当前状态开始,在任何和所有连续步骤中最大化总奖励的期望值。Q-learning 是一个 off-policy 优化,它拟合 Bellman 优化方程为:
![]()
Notes:当前的 Q value 可以分解为当前状态产生行为的 reward 与当前状态到下一状态 Q value 的折扣。(MDP)
对![]() 选择动作的贪婪策略是:
选择动作的贪婪策略是:
![]()
4.14 Reward. 需要设计新的奖励函数而不是使用广泛采用的二元稀疏奖励的原因有两个方面:(1)由于在攻击环境中的轨迹通常很长,所以需要中间奖励来反馈 RL agent 在每个状态下如何提高其性能;(2)与所知道的对目标节点的攻击是否成功的有目标攻击不同,这里在图上执行无目标攻击,因此精度不是二元的。为了解决这两个挑战,根据 Eq.(2) 所示的中毒目标函数设计了 agent 当前状态和行为的奖励。对于每个状态![]() ,首先定义攻击成功率
,首先定义攻击成功率![]() 为:
为:
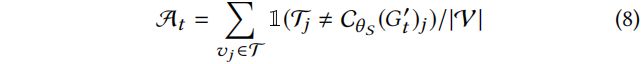

这里![]() 是如讨论的 Eq.(2) 用于计算奖励的训练集。
是如讨论的 Eq.(2) 用于计算奖励的训练集。![]() 不是由终端用户评估最终分类准确度的图分类器。由于攻击者通常不知道终端用户使用的模型,所以它代表了攻击者为获取状态和动作奖励而设计的模拟图分类器。直接使用分类准确率
不是由终端用户评估最终分类准确度的图分类器。由于攻击者通常不知道终端用户使用的模型,所以它代表了攻击者为获取状态和动作奖励而设计的模拟图分类器。直接使用分类准确率![]() 作为奖励会增加训练过程的不稳定性,因为对于两个连续的状态,精度可能不会有很大的不同。在这种情况下,如果行为
作为奖励会增加训练过程的不稳定性,因为对于两个连续的状态,精度可能不会有很大的不同。在这种情况下,如果行为![]() 可以在时刻 t 降低攻击者的模拟图分类器
可以在时刻 t 降低攻击者的模拟图分类器![]() 的准确性,我们将指导性二元奖励
的准确性,我们将指导性二元奖励 设计为 1 ,反之则设置为-1。所提出的指导性奖励定义如下:
设计为 1 ,反之则设置为-1。所提出的指导性奖励定义如下: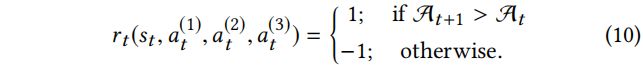
初步实验结果表明,这种引导奖励在本案例中是有效的。
4.1.5 Terminal. 在中毒攻击问题中,对于不明显的考虑,允许添加的对抗性边的数量由预算 ∆ 约束。因此,在中毒强化学习环境中,一旦 agent 添加预算边数(T = Δ),它就会停止采取行动。在终止状态![]() ,毒化的图
,毒化的图![]() 比干净图
比干净图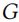 多 T 个对抗边。
多 T 个对抗边。
4.2 State Representation
当 Q function 对毒化的图![]() 中的节点进行评分时,探索状态的高度非线性结构是很重要的。为了表示带有向量
中的节点进行评分时,探索状态的高度非线性结构是很重要的。为了表示带有向量![]() 的毒化的图
的毒化的图![]() 的非欧式结构,
的非欧式结构,![]() 中每个节点
中每个节点![]() 的潜在 embedding
的潜在 embedding ![]() 首先由 struct2vec 使用判别信息来学习。然后状态向量表示
首先由 struct2vec 使用判别信息来学习。然后状态向量表示![]() 通过聚合节点的 embedding 来得到:
通过聚合节点的 embedding 来得到:
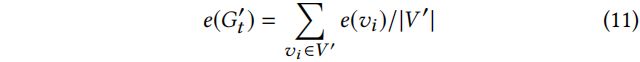
Notes:整个对抗图的 embedding 是由每个节点经过聚合后的 embedding 求和得到的。
为了表示注入伪节点的标签,使用两层神经网络解码节点标签![]() 的 one-hot embedding 为:
的 one-hot embedding 为:
![]()
![]() 表示标签
表示标签![]() 的 one-hot embedding,
的 one-hot embedding,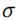 是非线性激活函数,
是非线性激活函数,![]() 是神经网络的参数。
是神经网络的参数。
实际上,更复杂的图 embedding 和标签 embedding 方法可以替代本文所述的模块,探索可行的图 embedding 和标签 embedding 方法是未来的方向。注意,在接下来的内容中,为了符号紧凑和一致性考虑,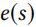 表示状态的 embedding,
表示状态的 embedding,![]() 和
和![]() 分别是行为 a 选择的节点和选择的标签的 embedding。
分别是行为 a 选择的节点和选择的标签的 embedding。
4.3 Hierarchical Q Network
在 Q learning 过程中,给定状态![]() 和行为
和行为![]() ,行为-值(action-value)函数
,行为-值(action-value)函数![]() 应该给出当前状态和所选动作的分数,来指导 RL agent。然而,考虑到效率搜索,由于行为 a 被分解为三层行为
应该给出当前状态和所选动作的分数,来指导 RL agent。然而,考虑到效率搜索,由于行为 a 被分解为三层行为![]() ,就很难直接设计
,就很难直接设计![]() 并应用一个策略网络选择分层动作。
并应用一个策略网络选择分层动作。
为了克服该问题,采用分层 deep Q networks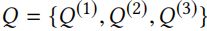 ,其整合三个 DQNs 来对行为上的 Q value 建模。图 2 阐述了所提出的 NIPA 在时刻 t 时行为
,其整合三个 DQNs 来对行为上的 Q value 建模。图 2 阐述了所提出的 NIPA 在时刻 t 时行为![]() 的选择。在获得状态表示
的选择。在获得状态表示![]() 后,第一个 DQN
后,第一个 DQN![]() 指导策略从注入节点集
指导策略从注入节点集![]() 选择一个节点。基于
选择一个节点。基于![]() ,第二个
,第二个![]() 学习策略来从节点集
学习策略来从节点集![]() 中选择第二个节点。第三个
中选择第二个节点。第三个![]() 学习策略来设置第一个选择注入的伪节点的标签。
学习策略来设置第一个选择注入的伪节点的标签。
agent 首先从注入节点集![]() 选择一个节点并基于 action-value 函数
选择一个节点并基于 action-value 函数![]() 计算 Q value:
计算 Q value:
![]()
其中![]() 表示第一个 DQN 的可训练参数,
表示第一个 DQN 的可训练参数,![]() 是连接操作。给定状态表示
是连接操作。给定状态表示![]() 和行为 embedding
和行为 embedding ![]() , action-value 函数
, action-value 函数![]() 评估每个注入节点的 Q value。
评估每个注入节点的 Q value。
基于 Eq.(13) 的最优action-value 函数![]() 的选择行为
的选择行为![]() 的贪婪策略定义为:
的贪婪策略定义为:
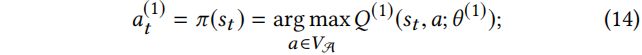
选择第一个动作![]() 后,agent 根据
后,agent 根据![]() 逐级选择第二个动作
逐级选择第二个动作![]() 为:
为:
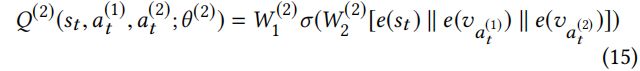
其中 是可训练权重。action value 函数
是可训练权重。action value 函数![]() 基于状态
基于状态![]() 和选择的行为
和选择的行为![]() 对第二个节点评分。贪婪策略通过 Eq.(15) 中的最优
对第二个节点评分。贪婪策略通过 Eq.(15) 中的最优![]() 进行第二个行为
进行第二个行为![]() 的定义为:
的定义为:
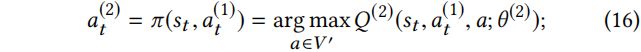
注意到 agent 只修改选择的注入的伪节点![]() 的标签,因此第三个行为的 action-value 函数并不直接与行为
的标签,因此第三个行为的 action-value 函数并不直接与行为![]() 相关。为注入的伪节点标签设计进行评分的 action-value 函数
相关。为注入的伪节点标签设计进行评分的 action-value 函数![]() 定义为:
定义为:
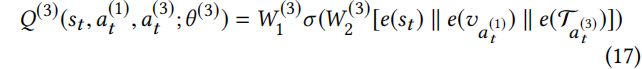
在 Eq.(17) 中,![]() 表示
表示![]() 中的可训练参数。action value 函数对注入节点
中的可训练参数。action value 函数对注入节点 改变标签的评分进行建模。这种行为的贪婪策略定义如下:
改变标签的评分进行建模。这种行为的贪婪策略定义如下:
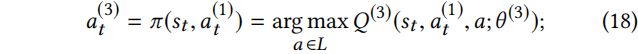
利用 Eq.(13),Eq(15) 和 Eq.(17) 所提出的 deep Q network ![]() ,NIPA 集成了分层 action value 函数,以对分层行为
,NIPA 集成了分层 action value 函数,以对分层行为![]() 的 Q value 建模。
的 Q value 建模。
4.4 Training Algorithm
为了训练分层![]() 和状态表示方法中的参数,采用了具有一定大小的内存缓冲区
和状态表示方法中的参数,采用了具有一定大小的内存缓冲区![]() 的 experience replay technique。使用 experience replay 的高层次思想是为了减少样本间相关性造成的偏差。模拟选择过程,生成训练数据并存储在内存缓冲区
的 experience replay technique。使用 experience replay 的高层次思想是为了减少样本间相关性造成的偏差。模拟选择过程,生成训练数据并存储在内存缓冲区![]() 中。在训练阶段,从存储的内存缓冲区
中。在训练阶段,从存储的内存缓冲区![]() 中均匀随机抽取一批经验
中均匀随机抽取一批经验![]() ,其中
,其中![]() 。Q-learning 损失函数定义为:
。Q-learning 损失函数定义为:
![]()
其中,![]() 表示目标 action-value 函数且其参数
表示目标 action-value 函数且其参数![]() 每 C 步用 θ 更新。为了提高算法的稳定性,将误差项限制在 -1 到 +1 之间。agent 采用 ε-greedy policy,以概率 ε 选择随即行为。整体算法框架总结在算法 1。
每 C 步用 θ 更新。为了提高算法的稳定性,将误差项限制在 -1 到 +1 之间。agent 采用 ε-greedy policy,以概率 ε 选择随即行为。整体算法框架总结在算法 1。
在该模型中,使用两层多层感知机实现 action value 函数![]() 和 structure2vec 中的所有参数 θ。实际上,更复杂的深度神经网络可以取代这里概述的模型。
和 structure2vec 中的所有参数 θ。实际上,更复杂的深度神经网络可以取代这里概述的模型。

思考:
采用 RL 的 paper 都有固定的模式,都是 state action reward,具体的细小部分不同。
欢迎讨论和指教。