2021-03-04
架构学习
一,数据库类
1,SQL
-
简介
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能 -
功能
SQL具有数据定义、数据操纵和数据控制的功能。
1、SQL数据定义功能:能够定义数据库的三级模式结构,即
外模式
(外模式又称子模式或用户模式,对应于用户级。它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。外模式是从模式导出的一个子集,包含模式中允许特定用户使用的那部分数据。用户可以通过外模式描述语言来描述、定义对应于用户的数据记录(外模式),也可以利用数据操纵语言(Data Manipulation Language,DML)对这些数据记录进行操作。外模式反映了数据库系统的用户观。)、
概念模式
(概念模式又称模式或逻辑模式,对应于概念级。它是由数据库设计者综合所有用户的数据,按照统一的观点构造的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图(全局视图)。它是由数据库管理系统提供的数据模式描述语言(Data Description Language,DDL)来描述、定义的。概念模式反映了数据库系统的整体观。)
内模式结构
(内模式又称存储模式,对应于物理级。它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。内模式由内模式描述语言来描述、定义的。内模式反映了数据库系统的存储观。)。在SQL中,外模式又叫做视图(View),全局模式简称模式( Schema),内模式由系统根据数据库模式自动实现,一般无需用户过问。
2、SQL数据操纵功能:包括对基本表和视图的数据插入、删除和修改,特别是具有很强的数据查询功能。
3、SQL的数据控制功能:主要是对用户的访问权限加以控制,以保证系统的安全性。 -
特点
- SQL风格统一
SQL可以独立完成数据库生命周期中的全部活动,包括定义关系模式、录入数据、建立数据库、査询、更新、维护、数据库重构、数据库安全性控制等一系列操作,这就为数据库应用系统开发提供了良好的环境,在数据库投入运行后,还可根据需要随时逐步修改模式,且不影响数据库的运行,从而使系统具有良好的可扩充性。 - 高度非过程化
非关系数据模型的数据操纵语言是面向过程的语言,用其完成用户请求时,必须指定存取路径。而用SQL进行数据操作,用户只需提出“做什么”,而不必指明“怎么做”,因此用户无须了解存取路径,存取路径的选择以及SQL语句的操作过程由系统自动完成。这不但大大减轻了用户负担,而且有利于提高数据独立性。 - 面向集合的操作方式
SQL采用集合操作方式,不仅查找结果可以是元组的集合,而且一次插入、删除、更新操作的对象也可以是元组的集合。
以同一种语法结构提供两种使用方式
SQL既是自含式语言,又是嵌入式语言。作为自含式语言,它能够独立地用于联机交互的使用方式,用户可以在终端键盘上直接输入SQL命令对数据库进行操作。作为嵌入式语言,SQL语句能够嵌入到高级语言(如C、 C#、JAVA)程序中,供程序员设计程序时使用。而在两种不同的使用方式下,SQL的语法结构基本上是一致的。这种以统一的语法结构提供两种不同的操作方式,为用户提供了极大的灵活性与方便性。 - 语言简洁,易学易用
SQL功能极强,但由于设计巧妙,语言十分简洁,完成数据定义、数据操纵、数据控制的核心功能只用了9个动词: CREATE、 ALTER、DROP、 SELECT、 INSERT、 UPDATE、 DELETE、GRANT、 REVOKE。且SQL语言语法简单,接近英语口语,因此容易学习,也容易使用。
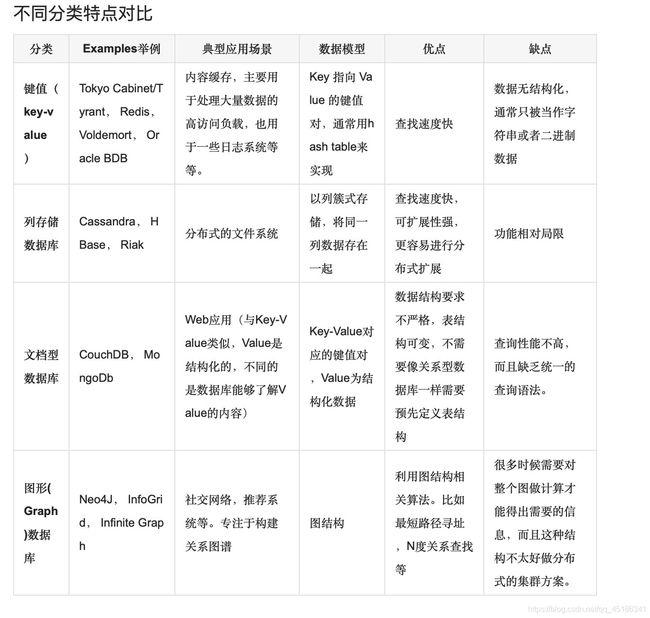
2,NOSQL
- 简介
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
-优点
NoSQL有如下优点:易扩展,NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间也在架构的层面上带来了可扩展的能力。大数据量,高性能,NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。 - 分类
-
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果数据库管理员(DBA)只对部分值进行查询或更新的时候,Key/value就显得效率低下了。举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。 -
列存储数据库
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak. -
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,在处理网页等复杂数据时,文档型数据库比传统键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。 -
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API如:Neo4J, InfoGrid, Infinite Graph。
- 体系框架
NoSQL框架体系NosoL整体框架分为四层,由下至上分为数据持久层(data persistence)、整体分布层(data distribution model)、数据逻辑模型层(data logical model)、和接口层(interface),层次之间相辅相成,协调工作。
数据持久层定义了数据的存储形式,主要包括基于内存、基于硬盘、内存和硬盘接口、订制可拔插四种形式。基于内存形式的数据存取速度最快,但可能会造成数据丢失。基于硬盘的数据存储可能保存很久,但存取速度较基于内存形式的慢。内存和硬盘相结合的形式,结合了前两种形式的优点,既保证了速度,又保证了数据不丢失。订制可拔插则保证了数据存取具有较高的灵活性。
数据分布层定义了数据是如何分布的,相对于关系型数据库,NoSQL可选的机制比较多,主要有三种形式:一是CAP支持,可用于水平扩展。二是多数据中心支持,可以保证在横跨多数据中心是也能够平稳运行。三是动态部署支持,可以在运行着的集群中动态地添加或删除节点。
数据逻辑层表述了数据的逻辑表现形式,与关系型数据库相比,NoSQL在逻辑表现形式上相当灵活,主要有四种形式:一是键值模型,这种模型在表现形式上比较单一,但却有很强的扩展性。二是列式模型,这种模型相比于键值模型能够支持较为复杂的数据,但扩展性相对较差。三是文档模型,这种模型对于复杂数据的支持和扩展性都有很大优势。四是图模型,这种模型的使用场景不多,通常是基于图数据结构的数据定制的。
接口层为上层应用提供了方便的数据调用接口,提供的选择远多于关系型数据库。接口层提供了五种选择:Rest,Thrift,Map/Reduce,Get/Put,特定语言API,使得应用程序和数据库的交互更加方便。
NoSQL分层架构并不代表每个产品在每一层只有一种选择。相反,这种分层设计提供了很大的灵活性和兼容性,每种数据库在不同层面可以支持多种特性。
- 适用场景
NoSQL数据库在以下的这几种情况下比较适用:
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
MongoDB
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=“Sameer”,Address=“8 Gandhi Road”)来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
MongoDB安装简单。
3,Clickhouse
- 简介
Yandex在2016年6月15日开源了一个数据分析的数据库,名字叫做ClickHouse,这对保守俄罗斯人来说是个特大事。更让人惊讶的是,这个列式存储数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。如果你没有听过Vertica,那你一定听过 Michael Stonebraker,2014年图灵奖的获得者,PostgreSQL和Ingres发明者(Sybase和SQL Server都是继承 Ingres而来的), Paradigm4和SciDB的创办者。Michael Stonebraker于2005年创办Vertica公司,后来该公司被HP收购,HP Vertica成为MPP列式存储商业数据库的高性能代表,Facebook就购买了Vertica数据用于用户行为分析。
- Clikhouse支持的特性剖析
在看Clickhouse 运行场景之前要了解技术的功能特性以及弊端是一个技术架构以及开发人员所要了解的。只有”知己知彼”才可以”百战不殆”,接下来我们看一下Clickhouse的具体特点;
1.真正的面向列的DBMS
在一个真正的面向列的DBMS中,没有任何“垃圾”存储在值中。例如,必须支持定长数值,以避免在数值旁边存储长度“数字”。例如,十亿个UInt8类型的值实际上应该消耗大约1 GB的未压缩磁盘空间,否则这将强烈影响CPU的使用。由于解压缩的速度(CPU使用率)主要取决于未压缩的数据量,所以即使在未压缩的情况下,紧凑地存储数据(没有任何“垃圾”)也是非常重要的。
因为有些系统可以单独存储单独列的值,但由于其他场景的优化,无法有效处理分析查询。例如HBase,BigTable,Cassandra和HyperTable。在这些系统中,每秒钟可以获得大约十万行的吞吐量,但是每秒不会达到数亿行。
另外,ClickHouse是一个DBMS(数据库管理系统),而不是一个单一的数据库。ClickHouse允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器
2.数据压缩
一些面向列的DBMS(InfiniDB CE和MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
3.磁盘存储的数据
许多面向列的DBMS(SAP HANA和GooglePowerDrill)只能在内存中工作。但即使在数千台服务器上,内存也太小,无法在Yandex.Metrica中存储所有浏览量和会话。
4.多核并行处理
多核多节点并行化大型查询。
5.在多个服务器上分布式处理
上面列出的列式DBMS几乎都不支持分布式处理。在ClickHouse中,数据可以驻留在不同的分片上。每个分片可以是用于容错的一组副本。查询在所有分片上并行处理。这对用户来说是透明的。
6.SQL支持
如果你熟悉标准的SQL,我们不能真正谈论SQL的支持。NULL不支持。所有的函数都有不同的名字。JOIN支持。子查询在FROM,IN,JOIN子句中被支持;标量子查询支持。关联子查询不支持。
7.向量化引擎
数据不仅按列存储,而且由矢量 - 列的部分进行处理。这使我们能够实现高CPU性能。
8.实时数据更新
ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序。由于这个原因,数据可以不断地添加到表中。添加数据时无锁处理。
9.索引
例如,带有主键可以在特定的时间范围内为特定客户端(Metrica计数器)抽取数据,并且延迟时间小于几十毫秒。
10.支持在线查询
这让我们使用该系统作为Web界面的后端。低延迟意味着可以无延迟实时地处理查询,而Yandex.Metrica界面页面正在加载(在线模式)。
11.支持近似计算
1.系统包含用于近似计算各种值,中位数和分位数的集合函数。
2.支持基于部分(样本)数据运行查询并获得近似结果。在这种情况下,从磁盘检索比例较少的数据。
3.支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相对准确的结果,同时使用较少的资源。
12.数据复制和对数据完整性的支持。
使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复 - 应用场景
1.电信行业用于存储数据和统计数据使用。
2.新浪微博用于用户行为数据记录和分析工作。
3.用于广告网络和RTB,电子商务的用户行为分析。
4。信息安全里面的日志分析。
5.检测和遥感信息的挖掘。
6.商业智能。
7.网络游戏以及物联网的数据处理和价值数据分析。
8.最大的应用来自于Yandex的统计分析服务Yandex.Metrica,类似于谷歌Analytics(GA),或友盟统计,小米统计,帮助网站或移动应用进行数据分析和精细化运营工具,据称Yandex.Metrica为世界上第二大的网站分析平台。ClickHouse在这个应用中,部署了近四百台机器,每天支持200亿的事件和历史总记录超过13万亿条记录,这些记录都存有原始数据(非聚合数据),随时可以使用SQL查询和分析,生成用户报告 - ClickHouse和一些技术比较
1.商业OLAP数据库
例如:HP Vertica, Actian the Vector,
区别:ClickHouse是开源而且免费的
2.云解决方案
例如:亚马逊RedShift和谷歌的BigQuery
区别:ClickHouse可以使用自己机器部署,无需为云付费
3.Hadoop生态软件
例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill
区别:
ClickHouse支持实时的高并发系统
ClickHouse不依赖于Hadoop生态软件和基础
ClickHouse支持分布式机房的部署
4.开源OLAP数据库
例如:InfiniDB, MonetDB, LucidDB
区别:这些项目的应用的规模较小,并没有应用在大型的互联网服务当中,相比之下,ClickHouse的成熟度和稳定性远远超过这些软件。
5.开源分析,非关系型数据库
例如:Druid , Apache Kylin
区别:ClickHouse可以支持从原始数据的直接查询,ClickHouse支持类SQL语言,提供了传统关系型数据的便利。
4,HBase
-
简介
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。 -
特点
1 大:一个表可以有上亿行,上百万列
2 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
3 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。 -
访问接口
- Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
- HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
- Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
- REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
- Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
- Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase

- Hbase系统架构
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
1 Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题,见下文描述
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
- 管理用户对Table的增、删、改、查操作
- 管理HRegionServer的负载均衡,调整Region分布
- 在Region Split后,负责新Region的分配
- 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
在理解了上述HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
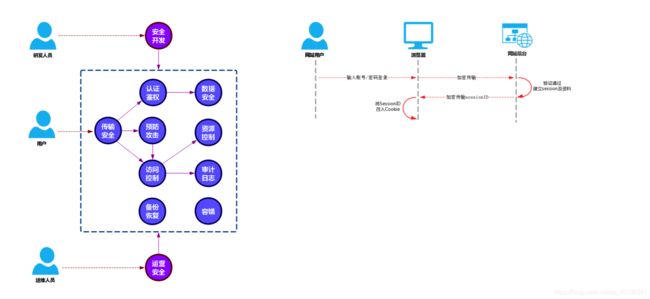
2,缓存
1,redis
-
简介
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助
*定义
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。 [1]
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
redis的官网地址,非常好记,是redis.io。(域名后缀io属于国家域名,是british Indian Ocean territory,即英属印度洋领地),Vmware在资助着redis项目的开发和维护。 -
支持语言

-
数据结构



dict中table为dictEntry指针的数组,数组中每个成员为hash值相同元素的单向链表。set是在dict的基础上实现的,指定了key的比较函数为dictEncObjKeyCompare,若key相等则不再插入。

- 存储
redis使用了两种文件格式:全量数据和增量请求。
全量数据格式是把内存中的数据写入磁盘,便于下次读取文件进行加载;
增量请求文件则是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据,序列化的操作包括SET、RPUSH、SADD、ZADD。
redis的存储分为内存存储、磁盘存储和log文件三部分,配置文件中有三个参数对其进行配置。
save seconds updates,save配置,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件。这个可以多个条件配合,比如默认配置文件中的设置,就设置了三个条件。
appendonly yes/no ,appendonly配置,指出是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。
appendfsync no/always/everysec ,appendfsync配置,no表示等操作系统进行数据缓存同步到磁盘,always表示每次更新操作后手动调用fsync()将数据写到磁盘,everysec表示每秒同步一次。
####3,redis雪崩,缓存击穿,异地缓存等
- 一,缓存穿透
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
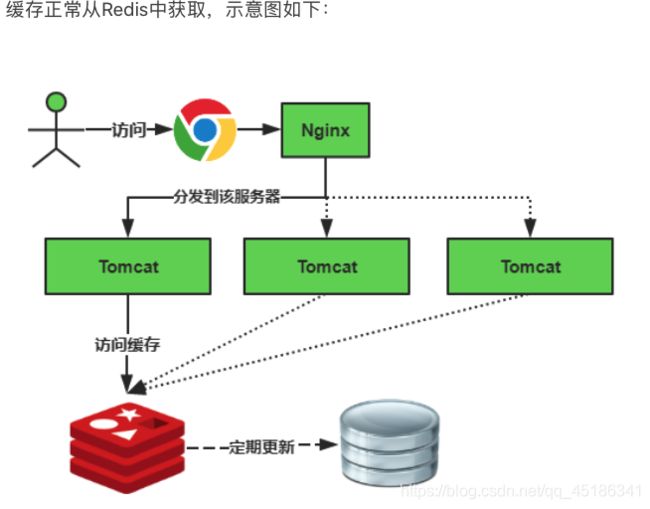

缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。还有一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。

 解释说明:
解释说明:
1、缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
2、缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
关于缓存崩溃的解决方法,这里提出了三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一各被称为“二级缓存”的解决方法,有兴趣的读者可以自行研究。
- 二,缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴!

-
三,缓存预热
-
缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载; -
四,缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
五,缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
3,WEB框架
1,sparkjava
- 简介
sparkjava是一个受Sinatra启发的微型Web框架,用于采用Java快速快速创建Web应用。
Spark(注意不要同Apache Spark混淆)的设计初衷是,可以简单容易地创建REST API或Web应用程序。它是一个灵活、简洁的框架,大小只有1MB。Spark允许用户自己选择设计应用程序的模板引擎以及选择最适合他们项目的库,比如,HTML解析功能就有Freemarker、Mustaches、Velocity、Jade、Handlebars、Pebble或Water等选项可供选择,而且很少需要配置或样板文件。不过,灵活简单的代价是,用户可选的功能减少。总之,Spark剔除了许多Java的臃肿之物,提供了一个最小化的、灵活的Web框架。但由于精简程度较高,它缺少了一些功能,不适合用于大型Web应用程序的开发。 - spark中的组件
Routes
在Spark程序中,其请求的处理都是由Route来完成的,一个Route由三部分组成:
1)一个动词,比如get,post,delete,trace等等
2)一个路径,比如前面的例子中的“/hello”
3)回调函数,比如前面的例子中的handle
另外需要注意的一点是,Spark在处理请求进行路径匹配的时候是优先匹配先出现的Route,也就是如果你的请求匹配到了多个Route,那么Spark会调用先出现的那个来处理请求。
Filters
除了Routes之外,Spark中另一个重要的组件就是Filter,filter分为before filter和after filter,两者分别可以在请求被Routes处理之前和被Routes处理之后获取Request或者对Response进行修改,
4,中间件
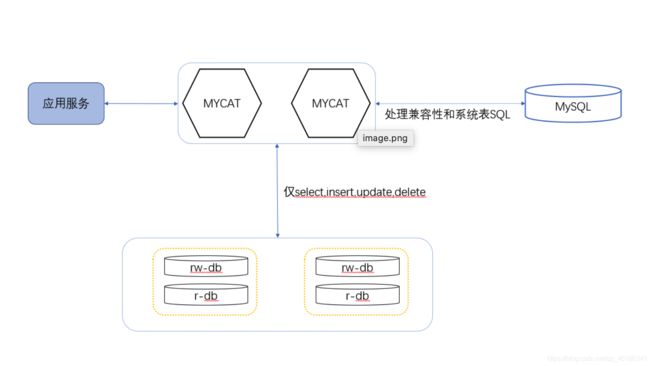
1,mycat
- 简介
MyCat 是目前最流行的基于== java 语言编写的数据库中间件==,是一个实现了 MySQL 协议 的服务器,前端用户可以把它看作是一个数据库代理,用== MySQL 客户端工具和命令行访问==,而其后端可以用 MySQL 原生协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分库分表。配合数据库的主从模式还可实现读写分离。MyCat 是基于阿里开源的 Cobar 产品而研发,Cobar 的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得 MyCat 变得非常的强大。
MyCat 发展到目前的版本,已经不是一个单纯的 MySQL 代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库,也支持 MongoDB 这种新型NoSQL 方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在 MyCat 里,都是一个传统的数据库表,支持标准的 SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
简单来说MyCat就是实现数据库集群的,对海量数据的数据存储的一种解决方案,因为很多数据库不想Oracle一样自带集群的配置,那么在进行海量数据存储的时候就要使用到MyCat进行数据库的管理了。


2,myBatis
-
简介
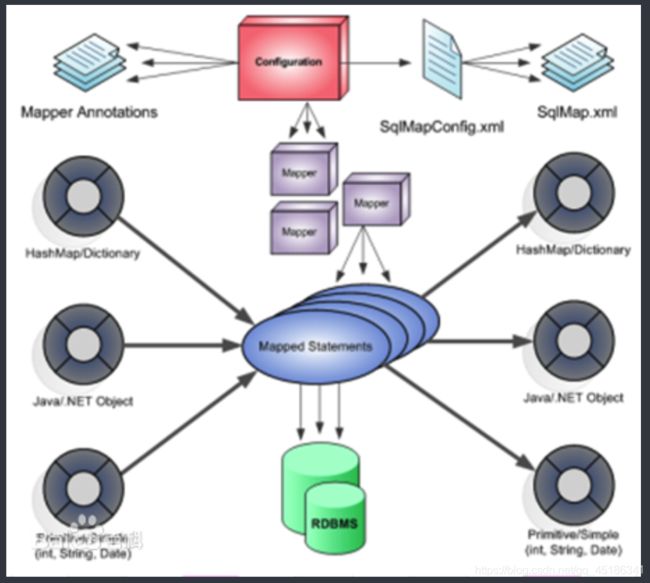
MyBatis是一款优秀的持久层框架,它支持定制化 SQL,存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的== XML== 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。
每个MyBatis应用程序主要都是使用SqlSessionFactory实例的,一个SqlSessionFactory实例可以通过SqlSessionFactoryBuilder获得。SqlSessionFactoryBuilder可以从一个xml配置文件或者一个预定义的配置类的实例获得。
用xml文件构建SqlSessionFactory实例是非常简单的事情。推荐在这个配置中使用类路径资源(classpath resource),但你可以使用任何Reader实例,包括用文件路径或file://开头的url创建的实例。MyBatis有一个实用类----Resources,它有很多方法,可以方便地从类路径及其它位置加载资源。 -
总体流程
(1)加载配置并初始化
触发条件:加载配置文件
处理过程:将SQL的配置信息加载成为一个个MappedStatement对象(包括了传入参数映射配置、执行的SQL语句、结果映射配置),存储在内存中。
(2)接收调用请求
触发条件:调用Mybatis提供的API
传入参数:为SQL的ID和传入参数对象
处理过程:将请求传递给下层的请求处理层进行处理。
(3)处理操作请求
触发条件:API接口层传递请求过来
传入参数:为SQL的ID和传入参数对象
处理过程:
(A)根据SQL的ID查找对应的MappedStatement对象。
(B)根据传入参数对象解析MappedStatement对象,得到最终要执行的SQL和执行传入参数。
©获取数据库连接,根据得到的最终SQL语句和执行传入参数到数据库执行,并得到执行结果。
(D)根据MappedStatement对象中的结果映射配置对得到的执行结果进行转换处理,并得到最终的处理结果。
(E)释放连接资源。
(4)返回处理结果将最终的处理结果返回。 -
功能架构
(1)API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
(2)数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
(3)基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
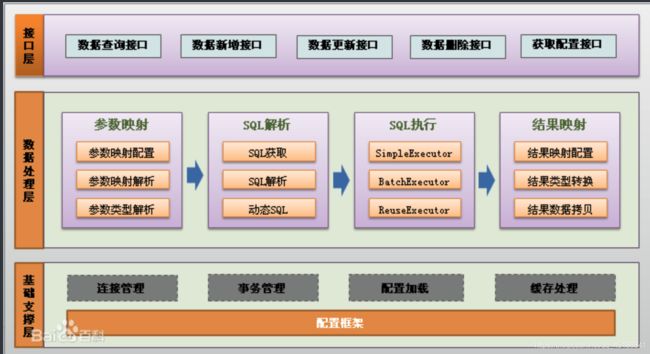
-
框架架构
1)加载配置:配置来源于两个地方,一处是配置文件,一处是Java代码的注解,将SQL的配置信息加载成为一个个MappedStatement对象(包括了传入参数映射配置、执行的SQL语句、结果映射配置),存储在内存中。
(2)SQL解析:当API接口层接收到调用请求时,会接收到传入SQL的ID和传入对象(可以是Map、JavaBean或者基本数据类型),Mybatis会根据SQL的ID找到对应的MappedStatement,然后根据传入参数对象对MappedStatement进行解析,解析后可以得到最终要执行的SQL语句和参数。
(3)SQL执行:将最终得到的SQL和参数拿到数据库进行执行,得到操作数据库的结果。
(4)结果映射:将操作数据库的结果按照映射的配置进行转换,可以转换成HashMap、JavaBean或者基本数据类型,并将最终结果返回。
-
动态SQL
MyBatis 最强大的特性之一就是它的动态语句功能。如果您以前有使用JDBC或者类似框架的经历,您就会明白把SQL语句条件连接在一起是多么的痛苦,要确保不能忘记空格或者不要在columns列后面省略一个逗号等。动态语句能够完全解决掉这些痛苦。
尽管与动态SQL一起工作不是在开一个party,但是MyBatis确实能通过在任何映射SQL语句中使用强大的动态SQL来改进这些状况。动态SQL元素对于任何使用过JSTL或者类似于XML之类的文本处理器的人来说,都是非常熟悉的。在上一版本中,需要了解和学习非常多的元素,但在MyBatis 3 中有了许多的改进,现在只剩下差不多二分之一的元素。MyBatis使用了基于强大的OGNL表达式来消除了大部分元素。
3, Hibernate
- 简介
Hibernate作为数据库与界面之间的桥梁,需要面向对象思想操纵对象。对象可能是普通JavaBeans/POJO。应用程序通过抽象将应用从底层事务隔离开。使用底层的API或Transaction对象完成轻量级框架提供一级缓存和二级缓存。Hibernate直接提供相关支持,底层驱动可以随意切换数据库,快速简洁。使业务层与具体数据库分开,只针对Hibernate 进行开发,完成数据和对象的持久化。针对不同的数据库形成不同的SQL 查询语句,降低数据库之间迁移的成本。Hibernate支持多种缓存机制,Hibernate适配MS SQLSERVER、ORACLE、SQL、H2、Access和Mysql等多种数据库。
Hibernate用反射机制实现持久化对象操作,实现与IDE(Integrated Development Environment)的耦合度。Hibernate使用数据库和配置信息为应用程序提供持久化服务。从配置文件中读取数据库相关参数,将持久化类和数据表对应使用。用Hibernate API对象持久化,利用映像信息将持久化操作翻译为SQL语句进行查询。
Hibernate框架技术最关键是数据持久化v,是将数据保存到持久层的过程。持久层的数据在掉电后也不会丢失的数据。持久层是基于Hibernate技术的检索系统开发的基本。系统结构的层次模型有三个阶段。
整个过程首先实现应用层和数据层。数据层保存持久化数据,应用层接收输入的数据。然后通过MVC 模式实现业务逻辑与表示层的分开。表示层和用户实现交互,业务逻辑层处理数据持久化操作。将第二阶段业务逻辑层的功能部署拆分后,业务逻辑层完成核心业务逻辑处理,持久层完成对象持久化。降低业务逻辑层复杂度的同时将数据持久化让其他组件完成。 - 语言特点
将对数据库的操作转换为对Java对象的操作,从而简化开发。通过修改一个==“持久化”对象的属性从而修改数据库表中对应的记录数据==。
提供线程和进程两个级别的缓存提升应用程序性能。
有丰富的映射方式将Java对象之间的关系转换为数据库表之间的关系。
屏蔽不同数据库实现之间的差异。在Hibernate中只需要通过“方言”的形式指定当前使用的数据库,就可以根据底层数据库的实际情况生成适合的SQL语句。
非侵入式:Hibernate不要求持久化类实现任何接口或继承任何类,POJO即可。 - 核心API
Hibernate的API一共有6个,分别为:Session、SessionFactory、Transaction、Query、Criteria和Configuration。通过这些接口,可以对持久化对象进行存取、事务控制。
Session
Session接口负责执行被持久化对象的CRUD操作(CRUD的任务是完成与数据库的交流,包含了很多常见的SQL语句)。但需要注意的是Session对象是非线程安全的。同时,Hibernate的session不同于JSP应用中的HttpSession。这里当使用session这个术语时,其实指的是Hibernate中的session,而以后会将HttpSession对象称为用户session。
SessionFactory
SessionFactory接口负责初始化Hibernate。它充当数据存储源的代理,并负责创建Session对象。这里用到了工厂模式。需要注意的是SessionFactory并不是轻量级的,因为一般情况下,一个项目通常只需要一个SessionFactory就够,当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
Transaction
Transaction 接口是一个可选的API,可以选择不使用这个接口,取而代之的是Hibernate 的设计者自己写的底层事务处理代码。 Transaction 接口是对实际事务实现的一个抽象,这些实现包括JDBC的事务、JTA 中的UserTransaction、甚至可以是CORBA 事务。之所以这样设计是能让开发者能够使用一个统一事务的操作界面,使得自己的项目可以在不同的环境和容器之间方便地移植。
Query
Query接口让你方便地对数据库及持久对象进行查询,它可以有两种表达方式:HQL语言或本地数据库的SQL语句。Query经常被用来绑定查询参数、限制查询记录数量,并最终执行查询操作。
Criteria
Criteria接口与Query接口非常类似,允许创建并执行面向对象的标准化查询。值得注意的是Criteria接口也是轻量级的,它不能在Session之外使用。
Configuration
Configuration 类的作用是对Hibernate 进行配置,以及对它进行启动。在Hibernate 的启动过程中,Configuration 类的实例首先定位映射文档的位置,读取这些配置,然后创建一个SessionFactory对象。虽然Configuration 类在整个Hibernate 项目中只扮演着一个很小的角色,但它是启动hibernate 时所遇到的第一个对象。
4, Spring Cloud生态系统概述
1,dubbo
-
Dubbo(读音[ˈdʌbəʊ])是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和== Spring框架无缝集成==。
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。 -
主要核心部件
Remoting: 网络通信框架,实现了 sync-over-async和request-response消息机制.
RPC: 一个远程过程调用的 抽象,支持负载均衡容灾和集群功能
Registry: 服务目录框架用于服务的注册和服务事件发布和订阅 -
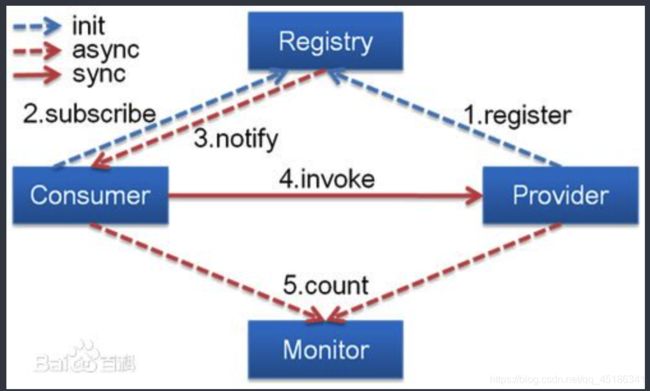
工作原理
Provider
暴露服务方 称之为“服务提供者”。
Consumer
调用远程服务方称之为“服务消费者”。
Registry
服务注册与发现的中心目录服务称之为“服务注册中心”。
Monitor
统计服务的调用次数和调用时间的日志服务称之为“服务监控中心”。
(1) 连通性:
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
(2) 健壮性:
监控中心宕掉不影响使用,只是丢失部分采样数据
数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕掉后,将自动切换到另一台
注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
(3) 伸缩性:
注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者




2,nacos
- 简介
Nacos 致力于帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是==构建以“服务”==为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。 - 关键特性
服务发现和服务健康监测
Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用 原生SDK、OpenAPI、或一个独立的Agent TODO注册 Service 后,服务消费者可以使用DNS TODO 或HTTP&API查找和发现服务。
Nacos 提供对服务的实时的健康检查,阻止向不健康的主机或服务实例发送请求。Nacos 支持传输层 (PING 或 TCP)和应用层 (如 HTTP、MySQL、用户自定义)的健康检查。 对于复杂的云环境和网络拓扑环境中(如 VPC、边缘网络等)服务的健康检查,Nacos 提供了agent 上报模式和服务端主动检测2种健康检查模式。Nacos 还提供了统一的健康检查仪表盘,帮助您根据健康状态管理服务的可用性及流量。
动态配置服务
动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。
动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。
配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
Nacos 提供了一个简洁易用的UI (控制台样例 Demo) 帮助您管理所有的服务和应用的配置。Nacos 还提供包括配置版本跟踪、金丝雀发布、一键回滚配置以及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助您更安全地在生产环境中管理配置变更和降低配置变更带来的风险。
动态 DNS 服务
动态 DNS 服务支持权重路由,让您更容易地实现中间层负载均衡、更灵活的路由策略、流量控制以及数据中心内网的简单DNS解析服务。动态DNS服务还能让您更容易地实现以 DNS 协议为基础的服务发现,以帮助您消除耦合到厂商私有服务发现 API 上的风险。
Nacos 提供了一些简单的 DNS APIs TODO 帮助您管理服务的关联域名和可用的 IP:PORT 列表.
服务及其元数据管理
Nacos 能让您从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的 SLA 以及最首要的 metrics 统计数据。

特性大图:要从功能特性,非功能特性,全面介绍我们要解的问题域的特性诉求
架构大图:通过清晰架构,让您快速进入 Nacos 世界
业务大图:利用当前特性可以支持的业务场景,及其最佳实践
生态大图:系统梳理 Nacos 和主流技术生态的关系
优势大图:展示 Nacos 核心竞争力
战略大图:要从战略到战术层面讲 Nacos 的宏观优势

3,服务发现
- 什么事服务发现
假设我们写的代码会调用 REST API 或者 Thrift API 的服务。为了完成一次请求,代码需要知道服务实例的网络位置(IP 地址和端口)。
运行在物理硬件上的传统应用中,服务实例的网络位置是相对固定的,代码能从一个偶尔更新的配置文件中读取网络位置。
对于基于云端的、现代化的微服务应用而言,这却是一大难题。将容器应用部署到集群时,其服务地址是由集群系统动态分配的。那么,当我们需要访问这个服务时,如何确定它的地址呢?这时就需要服务发现(Service Discovery)了。
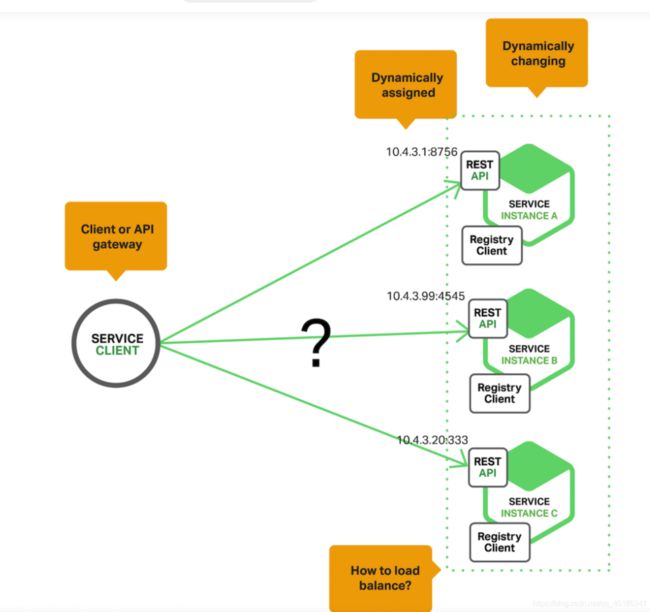
服务发现有两大模式:客户端发现模式和服务端发现模式。
客户端发现模式
使用客户端发现模式时,客户端决定相应服务实例的网络位置,并且对请求实现负载均衡。客户端查询服务注册表,后者是一个可用服务实例的数据库;然后使用负载均衡算法从中选择一个实例,并发出请求。
服务实例的网络位置在启动时被记录到服务注册表,等实例终止时被删除。服务实例的注册信息通常使用心跳机制来定期刷新。
客户端发现模式优缺点兼有。
这一模式相对直接,除了服务注册外,其它部分无需变动。此外,由于客户端知晓可用的服务实例,能针对特定应用实现智能负载均衡,比如使用哈希一致性。
这种模式的一大缺点就是客户端与服务注册绑定,要针对服务端用到的每个编程语言和框架,实现客户端的服务发现逻辑。
服务端发现模式
客户端通过负载均衡器向某个服务提出请求,负载均衡器查询服务注册表d,并将请求转发到可用的服务实例。
Kubernetes 和 Marathon 这样的部署环境会在每个集群上运行一个代理,将代理用作服务端发现的负载均衡器。客户端使用主机 IP 地址和分配的端口通过代理将请求路由出去,向服务发送请求。代理将请求透明地转发到集群中可用的服务实例。
服务端发现模式兼具优缺点。
它最大的优点是客户端无需关注发现的细节,只需要简单地向负载均衡器发送请求,这减少了编程语言框架需要完成的发现逻辑。并且如上文所述,某些部署环境免费提供这一功能。
这种模式也有缺点。除非负载均衡器由部署环境提供,否则会成为一个需要配置和管理的高可用系统组件。
4,服务降级
- 简介
什么是服务降级?当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
如果还是不理解,那么可以举个例子:假如目前有很多人想要给我付钱,但我的服务器除了正在运行支付的服务之外,还有一些其它的服务在运行,比如搜索、定时任务和详情等等。然而这些不重要的服务就占用了JVM的不少内存与CPU资源,为了能把钱都收下来(钱才是目标),我设计了一个动态开关,把这些不重要的服务直接在最外层拒掉,这样处理后的后端处理收钱的服务就有更多的资源来收钱了(收钱速度更快了),这就是一个简单的服务降级的使用场景。 - 使用场景
服务降级主要用于什么场景呢?当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些不重要或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
超时降级 —— 主要配置好超时时间和超时重试次数和机制,并使用异步机制探测恢复情况
失败次数降级 —— 主要是一些不稳定的API,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
故障降级 —— 如要调用的远程服务挂掉了(网络故障、DNS故障、HTTP服务返回错误的状态码和RPC服务抛出异常),则可以直接降级
限流降级 —— 当触发了限流超额时,可以使用暂时屏蔽的方式来进行短暂的屏蔽
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
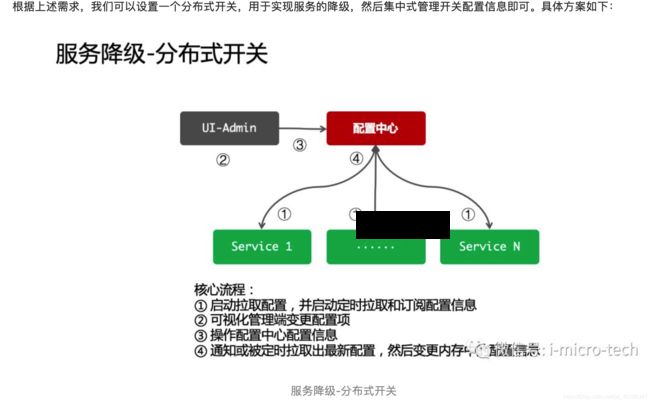
- 配置
微服务降级的配置信息是集中式的管理,然后通过可视化界面进行友好型的操作。配置中心和应用之间需要网络通信,因此可能会因网络闪断或网络重启等因素,导致配置推送信息丢失、重启或网络恢复后不能再接受、变更不及时等等情况,因此服务降级的配置中心需要实现以下几点特性,从而尽可能的保证配置变更即使达到:

启动主动拉取配置 —— 用于初始化配置(减少第一次定时拉取周期)
发布订阅配置 —— 用于实现配置及时变更(可以解决90%左右的配置变更)
定时拉取配置 —— 用于解决发布订阅失效或消失丢失的情况(可以解决9%左右的发布订阅失效的消息变更)
离线文件缓存配置 —— 用于临时解决重启后连接不上配置中心的问题
可编辑式配置文档 ——用于直接编辑文档的方式来实现配置的定义
提供Telnet命令变更配置 ——用于解决配置中心失效而不能变更配置的常见
- 处理策略
当触发服务降级后,新的交易再次到达时,我们该如何来处理这些请求呢?从微服务架构全局的视角来看,我们通常有以下是几种常用的降级处理方案:
页面降级 —— 可视化界面禁用点击按钮、调整静态页面
延迟服务 —— 如定时任务延迟处理、消息入MQ后延迟处理
写降级 —— 直接禁止相关写操作的服务请求
读降级 —— 直接禁止相关度的服务请求
缓存降级 ——== 使用缓存方式来降级部分读频繁的服务接口==
针对后端代码层面的降级处理策略,则我们通常使用以下几种处理措施进行降级处理:
抛异常
返回NULL
调用Mock数据
调用Fallback处理逻辑
- 服务监控
服务监控是要实现对平台的服务运行情况进行监控。
要求支持组件进程监控;如NameNode、DataNode、NodeManager、ResourceManager 等;
支持hadoop监控如下指标:空间的使用率、读块总次数、读块平均时间、正在运行的map数;
支持kafka组件进程监控;支持监控如下指标:主题的生产情况、主题的消费情况;
支持redis组件进程监控;支持监控如下指标:连接客户端数量、阻塞连接数量、占用内存情况、内存峰值情况;
支持Elastic-search组件进程监控;支持监控如下指标:每秒索引请求、搜索时间、每秒取数据请求、取数据时间;
平台接口监控支持服务进程监控;支持监控如下指标:吞吐量信息。
5,安全