视觉SLAM十四讲之回环检测(第二版)
视觉SLAM十四讲之回环检测(第二版)
文章目录
- 视觉SLAM十四讲之回环检测(第二版)
-
- 1、SLAM框架:前端、后端、回环检测
- 2、回环检测的关键:如何有效解决相机经过同一个地方。
- 3、回环检测的作用:
- 4、回环检测的方法
- 5、基于外观的回环检测方法:核心计算图像的相似性
- **6、评价基于外观的回环检测方法:准确率和召回率**
- 7、词袋模型(Bag-of-Words,BOW)
- 8、字典
- 9、如何创建字典
- 10、相似度计算:(理论+实践)
- 11、后期处理
1、SLAM框架:前端、后端、回环检测
前端:提供特征点的提取和轨迹、地图的初值
后端:主要是优化问题
回环检测:解决累积误差
2、回环检测的关键:如何有效解决相机经过同一个地方。
3、回环检测的作用:
a、估计轨迹和地图在长时间的准确性;
b、提供当前数据与历史数据的关联,利用回环检测进行重定位
4、回环检测的方法
a、基于里程计的方法(Odometry based):假设存在回环,在累积误差较大时很难work
b、基于外观的方法(Appearance based):基于图像的相似性,视觉SLAM的主流方法。
//工程应用:对于室外的情况:可以使用GPS进行回环检测
5、基于外观的回环检测方法:核心计算图像的相似性
5.1直接让两副图像表示的矩阵相减,由于光照和相机曝光的影响,不能很好的反映图像的相似性
评价判断图像的相似性好与不好的问题:引入感知偏差和感知变异的问题
6、评价基于外观的回环检测方法:准确率和召回率
回环检测的结果分类:
| 算法/事实 | 是回环 | 不是回环 |
|---|---|---|
| 是回环 | 真阳性(TP) | 假阳性(FP)感知偏差 |
| 不是回环 | 假阴性(FN):感知变异 | 真阴性(TN) |
准确率:precision=TP/(TP+FP):所有回环中确实是真实回环的概率
召回率:recall=TP/(TP+FN):在所有回环中被正确检测出来的概率
SLAM要求:对准确率要求的比较高,对召回相对宽容(没有检测出来的再加上回环验证的方法可以避免)
7、词袋模型(Bag-of-Words,BOW)
强调的是单词的有无,而不关心顺序。
对两个向量通过计算的方法确定图像的相似性。
计算公式:
s(a,b)=1-1/w||a-b||(L1泛数)
8、字典
字典生成问题类似于聚类问题。(无监督机器学习)
K-means算法主要步骤:
1、随机选取K个样本中心点c1,c2,...,ck
2、对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类。
3、重新计算每个类的中心点,如果每个中心点变化都很小,则算法收敛,退出,否则返回第二步。
K叉树来表达字典(类似于层次聚类,K-means的直接扩展):构建深度为d,每次分叉为K的树。
容纳的单词个数为:k的d此方
具体做法:
1、在根节点,用K-means把所有样本聚成K类(实际中为保证聚类可以使用K-means++),这样得到第一层。
2、对第一层的每个节点,把属于该节点的样本再聚成K类,得到下一层。
3、依次类推,最后得到叶子层,叶子层即为所谓的Words.
9、如何创建字典
需要使用的库:DBoW3
github连接:git clone https://github.com/rmsalinas/DBow3.git
使用cmake编译即可,最后执行sudo make install
CmakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++11 -O3" )
# opencv
find_package( OpenCV 3.1 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
#set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )默认为这种的,实际上编译产生的是.so文件
#当然你也可以用.a文件,那就需要更改DBoW3的CmakeLists文件。把共享库改成静态库即可。
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.so" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab gen_vocab_large.cpp )
target_link_libraries( gen_vocab ${OpenCV_LIBS} ${DBoW3_LIBS} )
feature_training.cpp
#include "DBoW3/DBoW3.h"
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据data/目录下的十张图训练字典
* ************************************************/
int main( int argc, char** argv )
{
// read the image
cout<<"reading images... "< images;
for ( int i=0; i<10; i++ )
{
string path = "./data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "< detector = ORB::create();//提取ORB特征
vector descriptors;//定义描述子
for ( Mat& image:images )
{
vector keypoints; //关键点
Mat descriptor;//描述子
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
}
// create vocabulary
cout<<"creating vocabulary ... "< 编译结果:
reading images...
detecting ORB features ...
[ INFO:0] Initialize OpenCL runtime...
creating vocabulary ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 4970
done
Weighting指的是权重,Scoring指的是评分
10、相似度计算:(理论+实践)
TF-IDF(Term Frequency-Inverse Document Frequency):文本检索中常用的一种加权方式
TF:某一个单词在一副图像中经常出现,它的区分度就越高。
IDF:某一个在字典中出现的频率越低,则区分度越高。
IDF:统计某一个叶子节点Wi中的特征数量相对于所有特征数量的比例,作为IDF部分。
IDFi=log(n/ni):wi数量为ni;所有特征数量为n
TF:某一个特征在单副图像中出现的频率。
TFi=ni/n
Wi的权重为
bi=TFi*IDFi
对于每一幅图像,它的特征点对应到许多个单词,组成BoW
A={(w1,b1),(w2,b2),...,(wn,bn)}==va
对于两幅图像给定va,vb,如何计算它们的相似性

实践:
#include "DBoW3/DBoW3.h"
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据前面训练的字典计算相似性评分
* ************************************************/
int main(int argc, char **argv) {
// read the images and database
cout << "reading database" << endl;
DBoW3::Vocabulary vocab("./vocabulary.yml.gz");
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;
return 1;
}
cout << "reading images... " << endl;
vector images;
for (int i = 0; i < 10; i++) {
string path = "./data/" + to_string(i + 1) + ".png";
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit.
// detect ORB features
cout << "detecting ORB features ... " << endl;
Ptr detector = ORB::create();
vector descriptors;
for (Mat &image:images) {
vector keypoints;
Mat descriptor;
detector->detectAndCompute(image, Mat(), keypoints, descriptor);
cout<<"Keypoints"< 注意:
当增加数据库的规模时,无关图像的相似性减小。
机器学习领域:当算法没问题而结果不满意,可以增加数据样本,网络结构以及层数的深度
11、后期处理
相似性评分的处理
关键帧的处理
回环之后的验证
11.1相似性评分的处理
取一个先验相似度,都参照这个值进行归一化处理,除数作为参照值。避免引入绝对的相似性阈值,使得算法可以更加鲁棒。
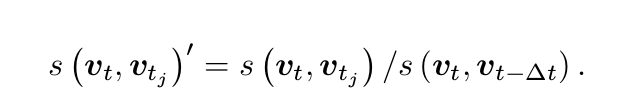
11.2关键帧的处理
用于回环检测的帧最好稀疏,彼此之间不太相同,又可以涵盖整个环境。
把相近的回环聚合成一类,使得算法不要反复检测同一类的回环。
11.3回环之后的验证方法
a.设立回环的缓存机制:单次检测到的回环不足以构成良好的约束,一段时间中检测得到的回环才认为是正确的回环
b.空间上的一致性检测:对回环检测到的两个帧进行特征匹配,估计相机的运动,把运动放到之前的pose graph中,检查与之前的估计是否有出入。
总结与未来
词袋方法在物体识别问题上已经明显不如神经网络,回环检测是一个相似的问题。