视觉SLAM十四讲CH11代码解析及课后习题详解
如果没有安装DBoW3,直接编译会报下面的错误:
fatal error: DBoW3/DBoW3.h: No such file or directory
#include "DBoW3/DBoW3.h"
^~~~~~~~~~~~~~~
compilation terminated.
CMakeFiles/gen_vocab.dir/build.make:82: recipe for target 'CMakeFiles/gen_vocab.dir/gen_vocab_large.cpp.o' failed
make[2]: *** [CMakeFiles/gen_vocab.dir/gen_vocab_large.cpp.o] Error 1
CMakeFiles/Makefile2:99: recipe for target 'CMakeFiles/gen_vocab.dir/all' failed
make[1]: *** [CMakeFiles/gen_vocab.dir/all] Error 2
Makefile:103: recipe for target 'all' failed
make: *** [all] Error 2
在进行编译程序前,先需要安装DBoW,第二版的安装文件下载链接如下所示:
https://github.com/rmsalinas/DBow3 https://github.com/rmsalinas/DBow3下载完成后,安装方法很简单,将文件存放在你想存放的文件夹里面,进入DBoW-master文件夹:
https://github.com/rmsalinas/DBow3下载完成后,安装方法很简单,将文件存放在你想存放的文件夹里面,进入DBoW-master文件夹:
mkdir buildcd buildcmake ..
make -j4sudo make install在编译CH11的时候,出现了下面的错误:
make[2]: *** No rule to make target '/usr/local/lib/libDBoW3.a', needed by 'loop_closure'. Stop.
make[1]: *** [CMakeFiles/Makefile2:80: CMakeFiles/loop_closure.dir/all] Error 2
make: *** [Makefile:84: all] Error 2问题是找不到libDBoW3.a这个文件,于是我用第一版的里面/home/liqiang/slambook/3rdparty中的DBow3.tar.gz来进行安装,下载链接如下所示:
GitHub - gaoxiang12/slambook
安装方法和上面是一样的。
feature_training.cpp
#include "DBoW3/DBoW3.h"//词袋支持头文件
#include //opencv核心模块
#include //gui模块
#include //特征点头文件
#include
#include
#include
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据data/目录下的十张图训练字典
* ************************************************/
int main( int argc, char** argv )
{
// read the image
cout<<"reading images... "< images; //图像
for ( int i=0; i<10; i++ )//遍历读取十张图像
{
string path = "./data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "< detector = ORB::create();
vector descriptors;//描述子
for ( Mat& image:images )
{
vector keypoints; //关键点
Mat descriptor;//描述子
detector->detectAndCompute( image, Mat(), keypoints, descriptor );//检测和计算
descriptors.push_back( descriptor );
}
// create vocabulary (创建字典)
cout<<"creating vocabulary ... "< CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++14 -O3" )
# opencv
find_package( OpenCV 3.1 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab gen_vocab_large.cpp )
target_link_libraries( gen_vocab ${OpenCV_LIBS} ${DBoW3_LIBS} )执行结果:
./feature_training ../data/reading images...
detecting ORB features ...
creating vocabulary ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 0
done这里出现了Number of words = 0,明显是错误的,通过检查程序,是读取data文件夹里面的数据路径有点小问题,修改:

在路径里面多加上一个 . 就可以了。
修改程序后执行结果如下所示:
reading images...
detecting ORB features ...
creating vocabulary ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 4981
done
其中weight是权重, Scoring指的是评分。
loop_closure.cpp
#include "DBoW3/DBoW3.h"//词袋支持头文件
#include //opencv核心模块
#include //gui模块
#include //特征点头文件
#include
#include
#include
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据前面训练的字典计算相似性评分
* ************************************************/
int main(int argc, char **argv) {
// read the images and database(读取图像和数据库)
cout << "reading database" << endl;//输出reading database(读取数据)
DBoW3::Vocabulary vocab("../vocabulary.yml.gz");//vocabulary.yml.gz路径
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;//输出Vocabulary does not exist
return 1;
}
cout << "reading images... " << endl;//输出reading images...
vector images;
for (int i = 0; i < 10; i++) {
string path = "../data/" + to_string(i + 1) + ".png";//图像读取路径
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit. 这里我们用它们生成的字典比较它们本身的相似性,这可能会产生过拟合
// detect ORB features
cout << "detecting ORB features ... " << endl;//输出detecting ORB features ...(正在检测ORB特征)
Ptr detector = ORB::create();//默认图像500个特征点
vector descriptors;//描述子 将10张图像提取ORB特征并存放在vector容器里
for (Mat &image:images) {
vector keypoints;//关键点
Mat descriptor;//描述子
detector->detectAndCompute(image, Mat(), keypoints, descriptor);//检测和计算
descriptors.push_back(descriptor);
}
// we can compare the images directly or we can compare one image to a database
// images :
cout << "comparing images with images " << endl;//输出comparing images with images
for (int i = 0; i < images.size(); i++)
{
DBoW3::BowVector v1;
//descriptors[i]表示图像i中所有的ORB描述子集合,函数transform()计算出用先前字典来描述的单词向量,每个向量中元素的值要么是0,表示图像i中没有这个单词;要么是该单词的权重
//BoW描述向量中含有每个单词的ID和权重,两者构成了整个稀疏的向量
//当比较两个向量时,DBoW3会为我们计算一个分数
vocab.transform(descriptors[i], v1);
for (int j = i; j < images.size(); j++)
{
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);//p296式(11.9)
cout << "image " << i << " vs image " << j << " : " << score << endl;//输出一幅图像与另外一幅图像之间的相似度评分
}
cout << endl;
}
// or with database
//在进行数据库查询时,DBoW对上面的分数进行排序,给出最相似的结果
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for (int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]);
cout << "database info: " << db << endl;//输出database info(数据库信息)为
for (int i = 0; i < descriptors.size(); i++)
{
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4); // max result=4
cout << "searching for image " << i << " returns " << ret << endl << endl;
}
cout << "done." << endl;
} CMakeLists.txt
和上面一样的。
执行结果:
在Ubuntu20.04执行的时候:
reading database
reading images...
detecting ORB features ...
comparing images with images
image 0 vs image 0 : 1
image 0 vs image 1 : 0.0322942
image 0 vs image 2 : 0.0348326
image 0 vs image 3 : 0.0292106
image 0 vs image 4 : 0.0307606
image 0 vs image 5 : 0.0386504
image 0 vs image 6 : 0.0267389
image 0 vs image 7 : 0.0254779
image 0 vs image 8 : 0.041301
image 0 vs image 9 : 0.0501515
image 1 vs image 1 : 1
image 1 vs image 2 : 0.041587
image 1 vs image 3 : 0.034046
image 1 vs image 4 : 0.0318553
image 1 vs image 5 : 0.0354084
image 1 vs image 6 : 0.0221539
image 1 vs image 7 : 0.0296462
image 1 vs image 8 : 0.0397894
image 1 vs image 9 : 0.0306703
image 2 vs image 2 : 1
image 2 vs image 3 : 0.0322172
image 2 vs image 4 : 0.0371113
image 2 vs image 5 : 0.0338423
image 2 vs image 6 : 0.0360772
image 2 vs image 7 : 0.044198
image 2 vs image 8 : 0.0354693
image 2 vs image 9 : 0.0351865
image 3 vs image 3 : 1
image 3 vs image 4 : 0.0278296
image 3 vs image 5 : 0.0338019
image 3 vs image 6 : 0.0349277
image 3 vs image 7 : 0.0294855
image 3 vs image 8 : 0.0299692
image 3 vs image 9 : 0.0469051
image 4 vs image 4 : 1
image 4 vs image 5 : 0.0630388
image 4 vs image 6 : 0.0355424
image 4 vs image 7 : 0.0294301
image 4 vs image 8 : 0.0295447
image 4 vs image 9 : 0.026492
image 5 vs image 5 : 1
image 5 vs image 6 : 0.0365682
image 5 vs image 7 : 0.0275375
image 5 vs image 8 : 0.0309867
image 5 vs image 9 : 0.0337013
image 6 vs image 6 : 1
image 6 vs image 7 : 0.0297398
image 6 vs image 8 : 0.0345615
image 6 vs image 9 : 0.0337139
image 7 vs image 7 : 1
image 7 vs image 8 : 0.0182667
image 7 vs image 9 : 0.0225071
image 8 vs image 8 : 1
image 8 vs image 9 : 0.0432488
image 9 vs image 9 : 1
出现了下面的这个报错,也不知道是为什么,换了台电脑,Ubuntu18.04就可以了,完全一样的代码(暂时未想明白)
comparing images with database
terminate called after throwing an instance of 'std::length_error'
what(): cannot create std::vector larger than max_size()
Aborted (core dumped)
下面是Ubuntu18.04上得出的结果:
./loop_closure
reading database
reading images...
detecting ORB features ...
comparing images with images
image 0 vs image 0 : 1
image 0 vs image 1 : 0.0322942
image 0 vs image 2 : 0.0348326
image 0 vs image 3 : 0.0292106
image 0 vs image 4 : 0.0307606
image 0 vs image 5 : 0.0386504
image 0 vs image 6 : 0.0267389
image 0 vs image 7 : 0.0254779
image 0 vs image 8 : 0.041301
image 0 vs image 9 : 0.0501515
image 1 vs image 1 : 1
image 1 vs image 2 : 0.041587
image 1 vs image 3 : 0.034046
image 1 vs image 4 : 0.0318553
image 1 vs image 5 : 0.0354084
image 1 vs image 6 : 0.0221539
image 1 vs image 7 : 0.0296462
image 1 vs image 8 : 0.0397894
image 1 vs image 9 : 0.0306703
image 2 vs image 2 : 1
image 2 vs image 3 : 0.0322172
image 2 vs image 4 : 0.0371113
image 2 vs image 5 : 0.0338423
image 2 vs image 6 : 0.0360772
image 2 vs image 7 : 0.044198
image 2 vs image 8 : 0.0354693
image 2 vs image 9 : 0.0351865
image 3 vs image 3 : 1
image 3 vs image 4 : 0.0278296
image 3 vs image 5 : 0.0338019
image 3 vs image 6 : 0.0349277
image 3 vs image 7 : 0.0294855
image 3 vs image 8 : 0.0299692
image 3 vs image 9 : 0.0469051
image 4 vs image 4 : 1
image 4 vs image 5 : 0.0630388
image 4 vs image 6 : 0.0355424
image 4 vs image 7 : 0.0294301
image 4 vs image 8 : 0.0295447
image 4 vs image 9 : 0.026492
image 5 vs image 5 : 1
image 5 vs image 6 : 0.0365682
image 5 vs image 7 : 0.0275375
image 5 vs image 8 : 0.0309867
image 5 vs image 9 : 0.0337013
image 6 vs image 6 : 1
image 6 vs image 7 : 0.0297398
image 6 vs image 8 : 0.0345615
image 6 vs image 9 : 0.0337139
image 7 vs image 7 : 1
image 7 vs image 8 : 0.0182667
image 7 vs image 9 : 0.0225071
image 8 vs image 8 : 1
image 8 vs image 9 : 0.0432488
image 9 vs image 9 : 1
comparing images with database
database info: Database: Entries = 10, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 4983
searching for image 0 returns 4 results:
searching for image 1 returns 4 results:
searching for image 2 returns 4 results:
searching for image 3 returns 4 results:
searching for image 4 returns 4 results:
searching for image 5 returns 4 results:
searching for image 6 returns 4 results:
searching for image 7 returns 4 results:
searching for image 8 returns 4 results:
searching for image 9 returns 4 results:
done. gen_vocab_large.cpp
书上的代码执行时,会报下面的错误,代码里面所描述的txt文件在文件夹下面也没有,具体是什么地方有问题也不太清楚。

terminate called after throwing an instance of 'std::logic_error'
what(): basic_string::_M_construct null not valid
Aborted (core dumped)
对代码进行一点修改:
#include "DBoW3/DBoW3.h"//词袋支持头文件
#include //opencv核心模块
#include //gui模块
#include //特征点头文件
#include
#include
#include
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
String directoryPath = "/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb";//图像路径
vector imagesPath;
glob(directoryPath, imagesPath);
// string dataset_dir = argv[1];
// ifstream fin ( dataset_dir+"/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb" );
// if ( !fin )
// {
// cout<<"please generate the associate file called associate.txt!"< rgb_files, depth_files;
// vector rgb_times, depth_times;
// while ( !fin.eof() )
// {
// string rgb_time, rgb_file, depth_time, depth_file;
// fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
// rgb_times.push_back ( atof ( rgb_time.c_str() ) );
// depth_times.push_back ( atof ( depth_time.c_str() ) );
// rgb_files.push_back ( dataset_dir+"/"+rgb_file );
// depth_files.push_back ( dataset_dir+"/"+depth_file );
// if ( fin.good() == false )
// break;
// }
// fin.close();
cout<<"generating features ... "< descriptors;//描述子
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( String path : imagesPath )
{
Mat image = imread(path);
vector keypoints; //关键点
Mat descriptor;//描述子
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ < 其中,图像路径那里需要下载数据集,下载地址如下:
Computer Vision Group - Dataset Download

CMakeLists.txt
和上面一样。
执行结果:
./gen_vocab
generating features ...
extracting features from image 1
extracting features from image 2
extracting features from image 3
extracting features from image 4
extracting features from image 5
extracting features from image 6
extracting features from image 7
extracting features from image 8
extracting features from image 9
extracting features from image 10
.....
extracting features from image 634
extracting features from image 635
extracting features from image 636
extracting features from image 637
extracting features from image 638
extracting features from image 639
extracting features from image 640
extract total 320000 features.
creating vocabulary, please wait ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 89315
done
执行完毕后,会在build文件夹下面生成一个vocab_larger.yml.gz,然后可以使用这个词典再执行loop_closure.cpp,只需要将loop_closure.cpp内容中词典内容修改一下就ok了。
再次执行loop_closure.cpp,得到的执行结果如下所示:
reading database
reading images...
detecting ORB features ...
comparing images with images
image 0 vs image 0 : 1
image 0 vs image 1 : 0.00401522
image 0 vs image 2 : 0.00575911
image 0 vs image 3 : 0.0057625
image 0 vs image 4 : 0.00516026
image 0 vs image 5 : 0.00289918
image 0 vs image 6 : 0.00280098
image 0 vs image 7 : 0.00329088
image 0 vs image 8 : 0.00869696
image 0 vs image 9 : 0.0304572
image 1 vs image 1 : 1
image 1 vs image 2 : 0.0241793
image 1 vs image 3 : 0.00553848
image 1 vs image 4 : 0.00522892
image 1 vs image 5 : 0.00702649
image 1 vs image 6 : 0.00331991
image 1 vs image 7 : 0.0035423
image 1 vs image 8 : 0.00950168
image 1 vs image 9 : 0.00598861
image 2 vs image 2 : 1
image 2 vs image 3 : 0.00634031
image 2 vs image 4 : 0.00541992
image 2 vs image 5 : 0.0149133
image 2 vs image 6 : 0.00789202
image 2 vs image 7 : 0.00498983
image 2 vs image 8 : 0.00329779
image 2 vs image 9 : 0.00490939
image 3 vs image 3 : 1
image 3 vs image 4 : 0.00195016
image 3 vs image 5 : 0.0150889
image 3 vs image 6 : 0.0073025
image 3 vs image 7 : 0.00476159
image 3 vs image 8 : 0.0110854
image 3 vs image 9 : 0.00516915
image 4 vs image 4 : 1
image 4 vs image 5 : 0.0105219
image 4 vs image 6 : 0.00596558
image 4 vs image 7 : 0.00467202
image 4 vs image 8 : -0
image 4 vs image 9 : 0.00676682
image 5 vs image 5 : 1
image 5 vs image 6 : 0.0015908
image 5 vs image 7 : 0.00508986
image 5 vs image 8 : 0.00442575
image 5 vs image 9 : 0.00177321
image 6 vs image 6 : 1
image 6 vs image 7 : 0.00579406
image 6 vs image 8 : 0.0069873
image 6 vs image 9 : 0.00166793
image 7 vs image 7 : 1
image 7 vs image 8 : 0.00720273
image 7 vs image 9 : 0.00174475
image 8 vs image 8 : 1
image 8 vs image 9 : 0.00937256
image 9 vs image 9 : 1
comparing images with database
database info: Database: Entries = 10, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 99566
searching for image 0 returns 4 results:
searching for image 1 returns 4 results:
searching for image 2 returns 4 results:
searching for image 3 returns 4 results:
searching for image 4 returns 4 results:
searching for image 5 returns 4 results:
searching for image 6 returns 4 results:
searching for image 7 returns 4 results:
searching for image 8 returns 4 results:
searching for image 9 returns 4 results:
done.
课后习题
1. 请书写计算PR 曲线的小程序。用MATLAB 或Python 可能更加简便一些,因为它们擅长作图。
进行测试前需要安装scikit-learn以及matplotlib:
安装scikit-learn:Installing scikit-learn — scikit-learn 1.0.1 documentation
pip3 install -U scikit-learnmatplotlib:
pip install matplotlib
下面的代码转载于:三分钟带你理解ROC曲线和PR曲线_Guo_Python的博客-CSDN博客_roc曲线和pr曲线
pr.py:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve,roc_curve
def draw_pr(confidence_scores, data_labels):
plt.figure()
plt.title('PR Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid()
#精确率,召回率,阈值
precision,recall,thresholds = precision_recall_curve(data_labels,confidence_scores)
from sklearn.metrics import average_precision_score
AP = average_precision_score(data_labels, confidence_scores) # 计算AP
plt.plot(recall, precision, label = 'pr_curve(AP=%0.2f)' % AP)
plt.legend()
plt.show()
def draw_roc(confidence_scores, data_labels):
#真正率,假正率
fpr, tpr, thresholds = roc_curve(data_labels, confidence_scores)
plt.figure()
plt.grid()
plt.title('Roc Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
from sklearn.metrics import auc
auc=auc(fpr, tpr) #AUC计算
plt.plot(fpr,tpr,label = 'roc_curve(AUC=%0.2f)' % auc)
plt.legend()
plt.show()
if __name__ == '__main__':
# 正样本的置信度,即模型识别成1的概率
confidence_scores = np.array([0.9, 0.78, 0.6, 0.46, 0.4, 0.37, 0.2, 0.16])
# 真实标签
data_labels = np.array([1,1,0,1,0,0,1,1])
draw_pr(confidence_scores, data_labels)
draw_roc(confidence_scores, data_labels)
在Ubuntu下面执行时候,我把python文件放在ch11文件夹下面:
python pr.py执行结果:

转载于:
Roc曲线和PR曲线的理解与简单的代码实现_JMU-HZH的博客-CSDN博客_pr曲线实现
pr1.py:
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve,roc_curve
plt.figure()
plt.title('PR Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid()
#只是理解两种曲线的含义,所以数据简单的构造
confidence_scores = np.array([0.9,0.46,0.78,0.37,0.6,0.4,0.2,0.16])
confidence_scores=sorted(confidence_scores,reverse=True)#置信度从大到小排列
print(confidence_scores)
data_labels = np.array([1,1,0,1,0,0 ,1,1])#置信度所对应的标签
#精确率,召回率,阈值
precision,recall,thresholds = precision_recall_curve(data_labels,confidence_scores)
print(precision)
print(recall)
print(thresholds)
plt.plot(recall,precision)
plt.show()
#真正率,假正率
fpr, tpr, thresholds = roc_curve(data_labels, confidence_scores)
#print(fpr)
#print(tpr)
plt.figure()
plt.grid()
plt.title('Roc Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
from sklearn.metrics import auc
auc=auc(fpr, tpr)#AUC计算
plt.plot(fpr,tpr,label='roc_curve(AUC=%0.2f)'%auc)
plt.legend()
plt.show()
执行结果:
python pr1.py
[0.9, 0.78, 0.6, 0.46, 0.4, 0.37, 0.2, 0.16]
[0.625 0.57142857 0.5 0.6 0.75 0.66666667
1. 1. 1. ]
[1. 0.8 0.6 0.6 0.6 0.4 0.4 0.2 0. ]
[0.16 0.2 0.37 0.4 0.46 0.6 0.78 0.9 ]

2. 验证回环检测算法,需要有人工标记回环的数据集,例如[103]。然而人工标记回环是很不方便的,我们会考虑根据标准轨迹计算回环。即,如果轨迹中有两个帧的位姿非常相近,就认为它们是回环。请你根据TUM 数据集给出的标准轨迹,计算出一个数据集中的回环。这些回环的图像真的相似吗?
转载于:视觉SLAM十四讲(第二版)第11讲习题解答 - 知乎
#include
#include
#include
#include
using namespace std;
using namespace Eigen;
// path to groundtruth file
string groundtruth_file = "/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg2_rpy/groundtruth.txt";
// 设置检测的间隔,使得检测具有稀疏性的同时覆盖整个环境
int delta = 50;
// 齐次变换矩阵差的范数
// 小于该值时认为位姿非常接近
double threshold = 0.4;
int main(int argc, char **argv) {
vector> poses;
vector times;
ifstream fin(groundtruth_file);
if (!fin) {
cout << "cannot find trajectory file at " << groundtruth_file << endl;
return 1;
}
int num = 0;
while (!fin.eof())
{
string time_s;
double tx, ty, tz, qx, qy, qz, qw;
fin >> time_s >> tx >> ty >> tz >> qx >> qy >> qz >> qw;
Isometry3d Twr(Quaterniond(qw, qx, qy, qz));
Twr.pretranslate(Vector3d(tx, ty, tz));
// 相当于从第150个位姿开始,这是因为标准轨迹的记录早于照片拍摄(前120个位姿均无对应照片)
if (num > 120 && num % delta == 0){
times.push_back(time_s);
poses.push_back(Twr);
}
num++;
}
cout << "read total " << num << " pose entries" << endl;
cout << "selected total " << poses.size() << " pose entries" << endl;
//设置检测到回环后重新开始检测图片间隔数量
cout << "**************************************************" << endl;
cout << "Detection Start!!!" << endl;
cout << "**************************************************" << endl;
for (size_t i = 0 ; i < poses.size() - delta; i += delta){
for (size_t j = i + delta ; j < poses.size() ; j++){
Matrix4d Error = (poses[i].inverse() * poses[j]).matrix() - Matrix4d::Identity();
if (Error.norm() < threshold){
cout << "第" << i << "张照片与第" << j << "张照片构成回环" << endl;
cout << "位姿误差为" << Error.norm() << endl;
cout << "第" << i << "张照片的时间戳为" << endl << times[i] << endl;
cout << "第" << j << "张照片的时间戳为" << endl << times[j] << endl;
cout << "**************************************************" << endl;
break;
}
}
}
cout << "Detection Finish!!!" << endl;
cout << "**************************************************" << endl;
return 0;
} 我试了一下这个代码,没跑通,报错提示killed,我也没搞懂是什么意思,有可能内存不够或者计算量太大,有想试试的去跑一跑。
3. 学习DBoW3 或DBoW2 库,自己寻找几张图片,看能否从中正确检测出回环。
我所使用的数据集是:Computer Vision Group - Dataset Download

然后在ch11下面建立一个新的文件夹data1,挑选了21张图片放进去。

然后修改图像路径:

gen_vocab_large3.cpp
#include "DBoW3/DBoW3.h"//词袋支持头文件
#include //opencv核心模块
#include //gui模块
#include //特征点头文件
#include
#include
#include
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
String directoryPath = "/home/liqiang/slambook2/ch11/data1";//图像路径
vector imagesPath;
glob(directoryPath, imagesPath);
// string dataset_dir = argv[1];
// ifstream fin ( dataset_dir+"/home/liqiang/slambook2/ch11/rgbd_dataset_freiburg1_desk2/rgb" );
// if ( !fin )
// {
// cout<<"please generate the associate file called associate.txt!"< rgb_files, depth_files;
// vector rgb_times, depth_times;
// while ( !fin.eof() )
// {
// string rgb_time, rgb_file, depth_time, depth_file;
// fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
// rgb_times.push_back ( atof ( rgb_time.c_str() ) );
// depth_times.push_back ( atof ( depth_time.c_str() ) );
// rgb_files.push_back ( dataset_dir+"/"+rgb_file );
// depth_files.push_back ( dataset_dir+"/"+depth_file );
// if ( fin.good() == false )
// break;
// }
// fin.close();
cout<<"generating features ... "< descriptors;//描述子
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( String path : imagesPath )
{
Mat image = imread(path);
vector keypoints; //关键点
Mat descriptor;//描述子
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ < CMakeLists.txt
cmake_minimum_required( VERSION 2.8 )
project( loop_closure )
set( CMAKE_BUILD_TYPE "Release" )
set( CMAKE_CXX_FLAGS "-std=c++14 -O3" )
# opencv
find_package( OpenCV 3.1 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
# 添加Pangolin依赖
find_package( Pangolin )
include_directories( ${Pangolin_INCLUDE_DIRS} )
# 添加Eigen头文件
include_directories("/usr/include/eigen3")
add_executable( 2 2.cpp )
target_link_libraries( 2 ${OpenCV_LIBS} ${DBoW3_LIBS} ${Pangolin_LIBRARIES} )
# dbow3
# dbow3 is a simple lib so I assume you installed it in default directory
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable( feature_training feature_training.cpp )
target_link_libraries( feature_training ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure loop_closure.cpp )
target_link_libraries( loop_closure ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure1 loop_closure1.cpp )
target_link_libraries( loop_closure1 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( loop_closure3 loop_closure3.cpp )
target_link_libraries( loop_closure3 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab gen_vocab_large.cpp )
target_link_libraries( gen_vocab ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab1 gen_vocab_large1.cpp )
target_link_libraries( gen_vocab1 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab2 gen_vocab_large2.cpp )
target_link_libraries( gen_vocab2 ${OpenCV_LIBS} ${DBoW3_LIBS} )
add_executable( gen_vocab3 gen_vocab_large3.cpp )
target_link_libraries( gen_vocab3 ${OpenCV_LIBS} ${DBoW3_LIBS} )执行结果:
./gen_vocab3generating features ...
extracting features from image 1
extracting features from image 2
extracting features from image 3
extracting features from image 4
extracting features from image 5
extracting features from image 6
extracting features from image 7
extracting features from image 8
extracting features from image 9
extracting features from image 10
extracting features from image 11
extracting features from image 12
extracting features from image 13
extracting features from image 14
extracting features from image 15
extracting features from image 16
extracting features from image 17
extracting features from image 18
extracting features from image 19
extracting features from image 20
extracting features from image 21
extract total 10500 features.
creating vocabulary, please wait ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 10381
done
执行完毕后会在build文件夹里生成一个vocab_larger3.yml.gz压缩包,最后将该压缩包放在ch11下面,执行loop_closure3。
修改下面两个地方:


loop_closure3.cpp
#include "DBoW3/DBoW3.h"//词袋支持头文件
#include //opencv核心模块
#include //gui模块
#include //特征点头文件
#include
#include
#include
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据前面训练的字典计算相似性评分
* ************************************************/
int main(int argc, char **argv) {
// read the images and database(读取图像和数据库)
cout << "reading database" << endl;//输出reading database(读取数据)
DBoW3::Vocabulary vocab("../vocab_larger3.yml.gz");//vocabulary.yml.gz路径
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;//输出Vocabulary does not exist
return 1;
}
cout << "reading images... " << endl;//输出reading images...
vector images;
for (int i = 0; i < 21; i++) {
string path = "../data1/" + to_string(i + 1) + ".png";//图像读取路径
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit. 这里我们用它们生成的字典比较它们本身的相似性,这可能会产生过拟合
// detect ORB features
cout << "detecting ORB features ... " << endl;//输出detecting ORB features ...(正在检测ORB特征)
Ptr detector = ORB::create();//默认图像500个特征点
vector descriptors;//描述子 将10张图像提取ORB特征并存放在vector容器里
for (Mat &image:images) {
vector keypoints;//关键点
Mat descriptor;//描述子
detector->detectAndCompute(image, Mat(), keypoints, descriptor);//检测和计算
descriptors.push_back(descriptor);
}
// we can compare the images directly or we can compare one image to a database
// images :
cout << "comparing images with images " << endl;//输出comparing images with images
for (int i = 0; i < images.size(); i++)
{
DBoW3::BowVector v1;
//descriptors[i]表示图像i中所有的ORB描述子集合,函数transform()计算出用先前字典来描述的单词向量,每个向量中元素的值要么是0,表示图像i中没有这个单词;要么是该单词的权重
//BoW描述向量中含有每个单词的ID和权重,两者构成了整个稀疏的向量
//当比较两个向量时,DBoW3会为我们计算一个分数
vocab.transform(descriptors[i], v1);
for (int j = i; j < images.size(); j++)
{
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);//p296式(11.9)
cout << "image " << i << " vs image " << j << " : " << score << endl;//输出一幅图像与另外一幅图像之间的相似度评分
}
cout << endl;
}
// or with database
//在进行数据库查询时,DBoW对上面的分数进行排序,给出最相似的结果
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for (int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]);
cout << "database info: " << db << endl;//输出database info(数据库信息)为
for (int i = 0; i < descriptors.size(); i++)
{
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4); // max result=4
cout << "searching for image " << i << " returns " << ret << endl << endl;
}
cout << "done." << endl;
}
CMakeLists.txt
参考上面的,上面的CMakeLists.txt 已经添加了相关的cpp执行文件。
./loop_closure3reading database
reading images...
detecting ORB features ...
comparing images with images
image 0 vs image 0 : 1
image 0 vs image 1 : 0.0179514
image 0 vs image 2 : 0.0257712
image 0 vs image 3 : 0.0248006
image 0 vs image 4 : 0.0215647
image 0 vs image 5 : 0.00544075
image 0 vs image 6 : 0.0224883
image 0 vs image 7 : 0.0172719
image 0 vs image 8 : 0.0177548
image 0 vs image 9 : 0.0362582
image 0 vs image 10 : 0.0162675
image 0 vs image 11 : 0.0222014
image 0 vs image 12 : 0.0204588
image 0 vs image 13 : 0.0170047
image 0 vs image 14 : 0.0165957
image 0 vs image 15 : 0.0241384
image 0 vs image 16 : 0.0131228
image 0 vs image 17 : 0.0231237
image 0 vs image 18 : 0.0126125
image 0 vs image 19 : 0.0264222
image 0 vs image 20 : 0.0319604
image 1 vs image 1 : 1
image 1 vs image 2 : 0.0225294
image 1 vs image 3 : 0.0291438
image 1 vs image 4 : 0.024401
image 1 vs image 5 : 0.0427242
image 1 vs image 6 : 0.00947695
image 1 vs image 7 : 0.0336035
image 1 vs image 8 : 0.0554665
image 1 vs image 9 : 0.0313537
image 1 vs image 10 : 0.0127257
image 1 vs image 11 : 0.0170929
image 1 vs image 12 : 0.024939
image 1 vs image 13 : 0.0188714
image 1 vs image 14 : 0.0191085
image 1 vs image 15 : 0.0482948
image 1 vs image 16 : 0.0242885
image 1 vs image 17 : 0.0134153
image 1 vs image 18 : 0.017274
image 1 vs image 19 : 0.0283448
image 1 vs image 20 : 0.00922942
image 2 vs image 2 : 1
image 2 vs image 3 : 0.0159252
image 2 vs image 4 : 0.0253237
image 2 vs image 5 : 0.0118317
image 2 vs image 6 : 0.0571594
image 2 vs image 7 : 0.0189714
image 2 vs image 8 : 0.0155815
image 2 vs image 9 : 0.0195412
image 2 vs image 10 : 0.0184117
image 2 vs image 11 : 0.0152941
image 2 vs image 12 : 0.0178018
image 2 vs image 13 : 0.0233106
image 2 vs image 14 : 0.0168851
image 2 vs image 15 : 0.0137194
image 2 vs image 16 : 0.0498792
image 2 vs image 17 : 0.0240186
image 2 vs image 18 : 0.0219548
image 2 vs image 19 : 0.0209176
image 2 vs image 20 : 0.0140803
image 3 vs image 3 : 1
image 3 vs image 4 : 0.0234056
image 3 vs image 5 : 0.0284397
image 3 vs image 6 : 0.02011
image 3 vs image 7 : 0.0216389
image 3 vs image 8 : 0.0176086
image 3 vs image 9 : 0.0155744
image 3 vs image 10 : 0.0170962
image 3 vs image 11 : 0.0225567
image 3 vs image 12 : 0.0234662
image 3 vs image 13 : 0.0182703
image 3 vs image 14 : 0.01482
image 3 vs image 15 : 0.020363
image 3 vs image 16 : 0.0176234
image 3 vs image 17 : 0.0233771
image 3 vs image 18 : 0.0155559
image 3 vs image 19 : 0.016011
image 3 vs image 20 : 0.0177395
image 4 vs image 4 : 1
image 4 vs image 5 : 0.0119718
image 4 vs image 6 : 0.0274229
image 4 vs image 7 : 0.0149015
image 4 vs image 8 : 0.0252062
image 4 vs image 9 : 0.0127473
image 4 vs image 10 : 0.0123496
image 4 vs image 11 : 0.0234471
image 4 vs image 12 : 0.0255185
image 4 vs image 13 : 0.018047
image 4 vs image 14 : 0.0397562
image 4 vs image 15 : 0.0105365
image 4 vs image 16 : 0.0148716
image 4 vs image 17 : 0.0347258
image 4 vs image 18 : 0.0131217
image 4 vs image 19 : 0.0191835
image 4 vs image 20 : 0.0211236
image 5 vs image 5 : 1
image 5 vs image 6 : 0.0141552
image 5 vs image 7 : 0.0205087
image 5 vs image 8 : 0.023158
image 5 vs image 9 : 0.0193337
image 5 vs image 10 : 0.0187104
image 5 vs image 11 : 0.025994
image 5 vs image 12 : 0.0196689
image 5 vs image 13 : 0.0257136
image 5 vs image 14 : 0.0124622
image 5 vs image 15 : 0.0692064
image 5 vs image 16 : 0.0210536
image 5 vs image 17 : 0.0252288
image 5 vs image 18 : 0.0119623
image 5 vs image 19 : 0.0251428
image 5 vs image 20 : 0.0231639
image 6 vs image 6 : 1
image 6 vs image 7 : 0.0176295
image 6 vs image 8 : 0.0157532
image 6 vs image 9 : 0.0177508
image 6 vs image 10 : 0.0141089
image 6 vs image 11 : 0.0116931
image 6 vs image 12 : 0.0177043
image 6 vs image 13 : 0.0113189
image 6 vs image 14 : 0.0165114
image 6 vs image 15 : 0.0238359
image 6 vs image 16 : 0.0286878
image 6 vs image 17 : 0.0242205
image 6 vs image 18 : 0.0238473
image 6 vs image 19 : 0.0183829
image 6 vs image 20 : 0.0160894
image 7 vs image 7 : 1
image 7 vs image 8 : 0.0484327
image 7 vs image 9 : 0.0799389
image 7 vs image 10 : 0.0140699
image 7 vs image 11 : 0.0353015
image 7 vs image 12 : 0.0162742
image 7 vs image 13 : 0.0123849
image 7 vs image 14 : 0.0155762
image 7 vs image 15 : 0.0236286
image 7 vs image 16 : 0.021078
image 7 vs image 17 : 0.00994403
image 7 vs image 18 : 0.0104469
image 7 vs image 19 : 0.00981495
image 7 vs image 20 : 0.0793399
image 8 vs image 8 : 1
image 8 vs image 9 : 0.0242055
image 8 vs image 10 : 0.0144976
image 8 vs image 11 : 0.0289231
image 8 vs image 12 : 0.0134452
image 8 vs image 13 : 0.0107451
image 8 vs image 14 : 0.013121
image 8 vs image 15 : 0.0440592
image 8 vs image 16 : 0.023649
image 8 vs image 17 : 0.0226309
image 8 vs image 18 : 0.0167086
image 8 vs image 19 : 0.0163815
image 8 vs image 20 : 0.019543
image 9 vs image 9 : 1
image 9 vs image 10 : 0.0196453
image 9 vs image 11 : 0.0360537
image 9 vs image 12 : 0.0216228
image 9 vs image 13 : 0.00905572
image 9 vs image 14 : 0.0117925
image 9 vs image 15 : 0.0203327
image 9 vs image 16 : 0.0124184
image 9 vs image 17 : 0.014915
image 9 vs image 18 : 0.0190471
image 9 vs image 19 : 0.0135781
image 9 vs image 20 : 0.136697
image 10 vs image 10 : 1
image 10 vs image 11 : 0.0150776
image 10 vs image 12 : 0.0147019
image 10 vs image 13 : 0.0437288
image 10 vs image 14 : 0.0212159
image 10 vs image 15 : 0.0175276
image 10 vs image 16 : 0.0244171
image 10 vs image 17 : 0.0173673
image 10 vs image 18 : 0.0180583
image 10 vs image 19 : 0.0198632
image 10 vs image 20 : 0.0186188
image 11 vs image 11 : 1
image 11 vs image 12 : 0.0145951
image 11 vs image 13 : 0.00686832
image 11 vs image 14 : 0.0105737
image 11 vs image 15 : 0.0193443
image 11 vs image 16 : 0.0145832
image 11 vs image 17 : 0.0164647
image 11 vs image 18 : 0.0173467
image 11 vs image 19 : 0.0160974
image 11 vs image 20 : 0.0500313
image 12 vs image 12 : 1
image 12 vs image 13 : 0.00650131
image 12 vs image 14 : 0.0809155
image 12 vs image 15 : 0.0164976
image 12 vs image 16 : 0.0315461
image 12 vs image 17 : 0.0174517
image 12 vs image 18 : 0.029972
image 12 vs image 19 : 0.0157822
image 12 vs image 20 : 0.0115077
image 13 vs image 13 : 1
image 13 vs image 14 : 0.0190167
image 13 vs image 15 : 0.0269287
image 13 vs image 16 : 0.0171848
image 13 vs image 17 : 0.0151769
image 13 vs image 18 : 0.0242274
image 13 vs image 19 : 0.00725557
image 13 vs image 20 : 0.00889539
image 14 vs image 14 : 1
image 14 vs image 15 : 0.0181876
image 14 vs image 16 : 0.03296
image 14 vs image 17 : 0.0200591
image 14 vs image 18 : 0.0362168
image 14 vs image 19 : 0.0128257
image 14 vs image 20 : 0.0160966
image 15 vs image 15 : 1
image 15 vs image 16 : 0.0233746
image 15 vs image 17 : 0.0147329
image 15 vs image 18 : 0.0240136
image 15 vs image 19 : 0.0301395
image 15 vs image 20 : 0.0211014
image 16 vs image 16 : 1
image 16 vs image 17 : 0.0128384
image 16 vs image 18 : 0.0139085
image 16 vs image 19 : 0.0200746
image 16 vs image 20 : 0.0090532
image 17 vs image 17 : 1
image 17 vs image 18 : 0.018697
image 17 vs image 19 : 0.017062
image 17 vs image 20 : 0.0147481
image 18 vs image 18 : 1
image 18 vs image 19 : 0.0196678
image 18 vs image 20 : 0.0187427
image 19 vs image 19 : 1
image 19 vs image 20 : 0.0131965
image 20 vs image 20 : 1
comparing images with database
database info: Database: Entries = 21, Using direct index = no. Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 10381
searching for image 0 returns 4 results:
searching for image 1 returns 4 results:
searching for image 2 returns 4 results:
searching for image 3 returns 4 results:
searching for image 4 returns 4 results:
searching for image 5 returns 4 results:
searching for image 6 returns 4 results:
searching for image 7 returns 4 results:
searching for image 8 returns 4 results:
searching for image 9 returns 4 results:
searching for image 10 returns 4 results:
searching for image 11 returns 4 results:
searching for image 12 returns 4 results:
searching for image 13 returns 4 results:
searching for image 14 returns 4 results:
searching for image 15 returns 4 results:
searching for image 16 returns 4 results:
searching for image 17 returns 4 results:
searching for image 18 returns 4 results:
searching for image 19 returns 4 results:
searching for image 20 returns 4 results:
done.
挑出几个 匹配分数较高的
(注意执行程序里的图片序号和data1文件夹下面的不一样:9对应的是png里面10,20对应的是21,这里学过c++基本语法的大家应该都能够理解)
第一组:构成回环
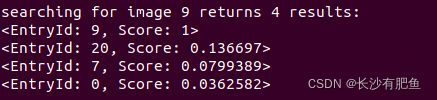


10.png 21.png
第二组:构成回环



15.png 13.png
第三组:构成回环



8.png 10.png
第四组:构成回环



3.png 7.png
总结:由于我图片是随便选择的,基本上匹配分数高的都构成回环,但是有时候会出现检测错误的,如果电脑性能较好,可以试试整个数据集,或者从里面选出较多的图像来进行回环检测。
4. 调研相似性评分的常用度量方式,哪些比较常用?
具体的常用度量方法请参考下面的文章:
机器学习中的相似性度量 - 知乎描述样本之间相似度的方法有很多种,一般来说常用的有相关系数和欧式距离。本文对机器学习中常用的相似性度量方法进行了总结。 在做分类时,常常需要估算不同样本之间的相似性度量(Similarity Measurement),这… https://zhuanlan.zhihu.com/p/55493039数据科学中常见的9种距离度量方法,内含欧氏距离、切比雪夫距离等 - 知乎在数据挖掘中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。在本文中,数据科学家 Maarten Grootendorst 向我们介绍了 9 种距离度量方法,其中包括欧氏距离、余弦相似度等。选自towardsda…https://zhuanlan.zhihu.com/p/350744027
https://zhuanlan.zhihu.com/p/55493039数据科学中常见的9种距离度量方法,内含欧氏距离、切比雪夫距离等 - 知乎在数据挖掘中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。在本文中,数据科学家 Maarten Grootendorst 向我们介绍了 9 种距离度量方法,其中包括欧氏距离、余弦相似度等。选自towardsda…https://zhuanlan.zhihu.com/p/350744027
(1)欧式距离
matlab程序如下:
转载于:【数据挖掘】MATLAB实现欧氏距离计算_小羊咩咩的博客-CSDN博客_matlab计算欧式距离
% 方法1
function dist = dist_E(x,y)
dist = [];
if(length(x)~=length(y))
disp('length of input vectors must agree') % disp函数会直接将内容输出在Matlab命令窗口中
else
z =(x-y).*(x-y);
dist = sqrt(sum(z));
end
end
% 方法2:公式法
function dist = dist_E(x,y)
[m,n] = size(x);
dist = 0;
for i=1:max(m,n)
dist = dist+(x(i)-y(i))^2;
end
dist = sqrt(dist);
end% 方法3:采用pdist函数
function dist = dist_E(x,y)
dist = [x;y];
dist = pdist(dist); % 计算各行向量之间的欧式距离
end在命令行输入:
x=[1,3,0,2];
y=[2,3,2,0];
dist=dist_E(x,y)按回车键,然后就可以算出两个向量之间的欧氏距离。

(2)曼哈顿距离
import numpy as np
a=[8,2]
b=[5,10]
a_np = np.array(a)
b_np = np.array(b)
dist3 = np.sum(np.abs(a_np-b_np))
print(f"Manhattan Distance = {dist3}\n")
python manhatta.py Manhattan Distance = 11以下代码转载于:[369]python各类距离公式实现_周小董-CSDN博客_python 欧氏距离
(3)切比雪夫距离
# -*- coding: utf-8 -*-
from numpy import *
vector1 = mat([1,2,3])
vector2 = mat([4,7,5])
print (abs(vector1-vector2).max())
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
#方法一:根据公式求解
d1=np.max(np.abs(x-y))
print('d1:',d1)
#方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=pdist(X,'chebyshev')[0]
print('d2:',d2)
python Chebyshev.py
5
d1: 0.7956039912699736
d2: 0.7956039912699736(3)汉明距离
# -*- coding: utf-8 -*-
from numpy import *
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
smstr = nonzero(matV[0]-matV[1])
print(shape(smstr[0])[0])
import numpy as np
from scipy.spatial.distance import pdist
x=np.random.random(10)>0.5
y=np.random.random(10)>0.5
x=np.asarray(x,np.int32)
y=np.asarray(y,np.int32)
#方法一:根据公式求解
d1=np.mean(x!=y)
print('d1:', d1)
#方法二:根据scipy库求解
X=np.vstack([x,y])
d2=pdist(X,'hamming')[0]
print('d2:', d2)
python hamming.py
6
d1: 0.4
d2: 0.4
(4)标准化欧氏距离
# -*- coding: utf-8 -*-
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
X=np.vstack([x,y])
#方法一:根据公式求解
sk=np.var(X,axis=0,ddof=1)
d1=np.sqrt(((x - y) ** 2 /sk).sum())
print('d1:',d1)
#方法二:根据scipy库求解
from scipy.spatial.distance import pdist
d2=pdist(X,'seuclidean')[0]
print('d2:',d2)
python Standardized_Euclidean.py d1: 4.47213595499958
d2: 4.47213595499958(5)夹角余弦
# -*- coding: utf-8 -*-
import numpy as np
from scipy.spatial.distance import pdist
'''
x: [0.05627679 0.80556938 0.48002662 0.24378563 0.75763754 0.15353348
0.54491664 0.1775408 0.50011986 0.55041845]
y: [0.50068882 0.12200178 0.79041352 0.07332715 0.017892 0.57880032
0.56707591 0.48390753 0.631051 0.20035466]
'''
x = np.random.random(10)
y = np.random.random(10)
# solution1
dist1 = 1 - np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
# solution2
dist2 = pdist(np.vstack([x, y]), 'cosine')[0]
print('x', x)
print('y', y)
print('dist1:', dist1)
print('dist2:', dist2)
python Cosine.py x [0.59758063 0.40859383 0.98186786 0.01670254 0.33830128 0.06095993
0.80674537 0.90611795 0.08119071 0.24229608]
y [0.43176033 0.2846342 0.41233185 0.37309159 0.24177945 0.68055469
0.36115457 0.3278653 0.57811011 0.13355709]
dist1: 0.31572330152121986
dist2: 0.31572330152121975
(6)杰卡德距离&杰卡德相似系数
# -*- coding: utf-8 -*-
from numpy import *
from scipy.spatial.distance import pdist # 导入scipy距离公式
matV = mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
print ("dist.jaccard:", pdist(matV,'jaccard'))
import numpy as np
from scipy.spatial.distance import pdist
x = np.random.random(10) > 0.5
y = np.random.random(10) > 0.5
x = np.asarray(x, np.int32)
y = np.asarray(y, np.int32)
# 方法一:根据公式求解
up = np.double(np.bitwise_and((x != y), np.bitwise_or(x != 0, y != 0)).sum())
down = np.double(np.bitwise_or(x != 0, y != 0).sum())
d1 = (up / down)
print('d1:', d1)
# 方法二:根据scipy库求解
X = np.vstack([x, y])
d2 = pdist(X, 'jaccard')[0]
print('d2:', d2)
python Jaccard.py
dist.jaccard: [0.75]
d1: 1.0
d2: 1.0(7)相关系数&相关距离
# -*- coding: utf-8 -*-
import numpy as np
x=np.random.random(10)
y=np.random.random(10)
#方法一:根据公式求解
x_=x-np.mean(x)
y_=y-np.mean(y)
d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))
print('d1:', d1)
#方法二:根据numpy库求解
X=np.vstack([x,y])
d2=np.corrcoef(X)[0][1]
print('d2:', d2)
python correlation.py
d1: 0.2479989126873464
d2: 0.247998912687346425. Chow-Liu 树是什么原理?它是如何被用于构建字典和回环检测的?
参考下面这篇文章:毕业论文整理(二):用依赖树近似离散概率分布 | 文章 | BEWINDOWEB
6. 阅读[118],除了词袋模型,还有哪些用于回环检测的方法?
参考下面两篇文章:
视觉SLAM十四讲(第二版)第11讲习题解答 - 知乎
综述 | SLAM回环检测方法