深度学习花朵识别系统的设计与实现
摘要:该项目是基于Keras的VGG16模型微调实现的深度学习花朵识别检测系统,使用Python语言中的cv2和numpy库对图像进行预处理,使用keras的ImageDataGenerator进行数据增强,采用Pyqt5实现功能的可视化,方便用户对图片进行检测。在实验过程中,发现当数据集较小,很难在一个新的网络结构上训练出具有很高准确率的模型,可以借助预训练网络模型(即已经训练好的网络模型,如VGG16)。我们利用自己的数据集来重新训练这些模型的分类层,就可以获得比较高的准确率。在此基础上该模型调参优化得到了98%以上的准确率验证了微调模型有助于训练小样本模型。
一、项目设计的意义
1.1 研究背景和意义
植物分类是植物科学研究领域和农林业生产经营中重要的基础性工作,植物分类学是一项具有长远意义的基础性研究,其主要的分类依据是植物的外观特征,包括叶、花、枝干、树皮、果实等。因此,花卉分类是植物分类学的重要部分,利用计算机进行花卉自动种类识别具有重要意义。本文从常见的观赏花卉入手,探索了基于花朵数字图像对花卉进行种类识别的方法。
本文构建了基于Keras的VGG16模型微调实现的深度学习花朵识别检测系统,并用十种花卉对系统进行了测试,达到了98%以上的识别准确率。实验结果表明,本文所实现的花卉种类识别系统具有较高的识别准确率和稳定性。
二、项目采用的原理
2.1卷积神经网络
彩色图像有RGB三个颜色通道,可以用二维数组来表示。比如一张160x60的彩色图片,可以用160*60*3的数组表示。

卷积操作可以提取图像特征。使用卷积核在每层像素矩阵上不断按步长扫描下去,每次扫到的数值和卷积核中对应位置的数进行相乘,然后相加求和,得到的值将会生成一个新的矩阵。卷积核的大小常用的是3x3,也有用5x5,不过前者的训练效果会更好。卷积核里面的每个值就是权重(训练模型过程中的神经元参数),开始设置随机的初始值,在训练的过程中,网络会通过后向传播不断更新这些参数值,直到寻找到最佳的参数值。这个最佳的参数值的评估是通过loss损失函数来评估。

Image为需要进行卷积的5x5大小的图片,而Convolved feature为卷积后得到的特征图;黄色矩阵为3x3大小的Filter(过滤器)在卷积的过程中,Filter与Image对应位置相乘再相加之和,得到此时中心位置的值然后填入Convolved Feature特征图的第一行第一列,然后在移动一个各自(stride=1),继续与下一个位置卷积,直至最后得到3x3x1的矩阵。
卷积后得到的Convolved feature的特征图的宽度(width)和高度(height)的计算:卷积后的Convolved feature的矩阵维度=(Image矩阵维数-Filter矩阵维数+2xpad)/2+1。
Width= (5-3+2x0)/1+1,Height=(5-3+2x0)/1+1
Padding操作可以更好的提取边界特征。在图像卷积的过程中,处于中间位置的数值容易被进行多次的提取,但是边界数值的特征提取次数相对较少。为了能更好的提取边界特征,可以给原始的数据矩阵的四周都补上一层0,这就是Padding操作。

对上述的例子进行padding填充,那么卷积后图片大小不会发生改变,如5x5的图像大小。
Padding=1变成为7x7,再用3x3的Filter进行卷积,那么卷积后的宽高为(7-3+2x1)/1+1=7
池化操作可以进行降维操作,有最大池化和平均池化,其中最大池化(Max Pooling)最为常用。
经过卷积操作后我们提取到的特征信息,相邻区域会有相似特征信息,这是可以相互替代的,如果全部保留这些特征信息会存在信息冗余,增加计算难度。可以通过池化层减小数据的空间大小,参数的数量和计算量会有相应的下降,在一定程度上也控制了过拟合。
最大池化(Max Pooling)就是Filter对应区域内最大像素值替代该像素点值,其作用是降维池化使用的滤波器都是2x2大小,因此池化后得到的图像大小为原来的1/2。

Flatten可以将池化后的数据变成一维向量,方便输入到全连接网络。
全连接层是第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权。
Dropout可以按照一定的比例将网络中的神经元进行丢弃,防止模型在训练过程中出现过拟合的情况。
2.2卷积神经网络VGG16详解
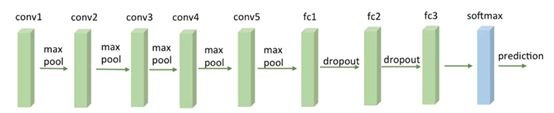
由上图所知,VGG16一共有五段卷积,每段卷积之后紧接着最大池化层,最后几层使用三层全连接层,最终接一个softmax。网络的输入是224x224大小的图像,输出的是图像分类结果。
VGG详细的分析,首先VGG是基于Alexnet网络,在此基础上对深度神经网络在深度和宽度上做了更多深入的研究。业界普遍认为更深的网络比浅的网络更强的表达能力,更能刻画显示,完成更复杂的任务,但更深的网络意味着更多的参数,训练更加困难。为了更好的探究深度对网络的影响,必须要解决参数量的问题。
在VGG中取消了Alexnet的LRN层,采用3x3卷积核,相比于采用7x7卷积核的Alexnet而言,参数量更少。池化核变小,VGG的池化核是2x2,stride为2,Alexnet池化核是3x3,步长为2。
由于卷积神经网络的特性,3x3大小的卷积核足以捕捉到横、竖以及斜对角像素的变化。使用大卷积核会带来参数量的爆炸不说,而且图像中会存在一些部分被多次卷积,可能会给特征提取带来困难,所以在VGG中,普遍使用3x3的卷积。
在VGG网络的最后三层全连接层的参数在VGG的整体参数中占据了很大一部分,为了减少参数量,后几层的全连接网络都被全局平均池化和卷积操作代替了,但是全局平均池化也有很大的优点。
VGG是一个良好的特征提取器,其与训练好的模型也经常被用来做其他事情,比如计算Perceptual loss(风格迁移和超分辨率任务中),尽管现在Resnet和Inception网络等等具有很高的精度和更加简便的网络结构,但是在特征提取上,VGG一直是一个很好的网络,所以说,当你的某些任务上Resnet或者Inception等表现并不好时,不妨试一下VGG,或许会有意想不到的结果。
VGG对于Alexnet来说,改进并不是很大,主要改进就在于使用了小卷积核,网络是分段卷积网络,通过maxpooling过度,同时网络更深更宽。
基本概念理解之后,现在就可以进入到理解VGG16的网络模型了。
1.从Input到Conv_1:由于224不太好计算,使用input图片大小300x300x3举例:

首先两个黄色的是卷积层,是VGG16网络结构十六层当中的第一层(Conv1_1)和第二层(Conv1_2),合称为Conv_1。3x3x3的卷积核(Filter),卷积核得到的图像为298x298x1(此处没有进行padding,步长为1),但是经过填充一圈的矩阵,所以得到的结果为300x300x1,在这层中有64个卷积核,那么原来的300x300x1就变成了300x300x64。
2.从Conv_1到Conv_2之间的过渡:

Pooling使用Filter是2x2x64,且步长为2,得到的矩阵维数刚好为原来的一半,第三个维度64不改变,因为那个指的是Filter的个数。
3.Conv_2到Conv_3:
Input为300x300x3的图片,经过第一层(里面由64个卷积核)。之后变成150x150x64。第二层里面由128个卷积核,由上述的规律可以推出第二层得到75x75x128。
4.Conv_3到Conv_4:
第二层里面由256个卷积核,由上述的规律可以推出第二层得到75x75x256。
VGG16的网络模型参数图表
| Layer (type) Output Shape Param # |
| conv2d_1 (Conv2D) (None, 224, 224, 64) 1792 |
| conv2d_2 (Conv2D) (None, 224, 224, 64) 36928 |
| max_pooling2d_1 (MaxPooling2 (None, 112, 112, 64) 0 |
| conv2d_3 (Conv2D) (None, 112, 112, 128) 73856 |
| conv2d_4 (Conv2D) (None, 112, 112, 128) 147584 |
| max_pooling2d_2 (MaxPooling2 (None, 56, 56, 128) 0 |
| conv2d_5 (Conv2D) (None, 56, 56, 256) 295168 |
| conv2d_6 (Conv2D) (None, 56, 56, 256) 590080 |
| conv2d_7 (Conv2D) (None, 56, 56, 256) 590080 |
| max_pooling2d_3 (MaxPooling2 (None, 28, 28, 256) 0 |
| conv2d_8 (Conv2D) (None, 28, 28, 512) 1180160 |
| conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808 |
| conv2d_10 (Conv2D) (None, 28, 28, 512) 2359808 |
| max_pooling2d_4 (MaxPooling2 (None, 14, 14, 512) 0 |
| conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808 |
| conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808 |
| conv2d_13 (Conv2D) (None, 14, 14, 512) 2359808 |
| max_pooling2d_5 (MaxPooling2 (None, 7, 7, 512) 0 |
| flatten_1 (Flatten) (None, 25088) 0 |
| dense_1 (Dense) (None, 4096) 102764544 |
| dropout_1 (Dropout) (None, 4096) 0 |
| dense_2 (Dense) (None, 4096) 16781312 |
| dropout_2 (Dropout) (None, 4096) 0 |
| dense_3 (Dense) (None, 1000) 4097000 |
| Total params: 138,357,544 |
| Trainable params: 138,357,544 |
| Non-trainable params: 0 |
三、项目设计方案
3.1关于数据的处理和分析
3.1.1基本概念
训练集:顾名思义指的是用于训练的样本集合,主要用来训练神经网络中的参数。
验证集:从字面意思理解即为用于验证模型性能的样本集合。不同神经网络在训练集上训练结束后,通过验证集来比较判断各个模型的性能.这里的不同模型主要是指对应不同超参数的神经网络,也可以指完全不同结构的神经网络。
测试集:对于训练完成的神经网络,测试集用于客观的评价神经网络的性能。

数据增强:数据增强也称为数据扩增,在不增加实质性的增加数据的情况下,让有限的数据产生等价更多数据的价值。数据增强的本质是为了获得更好的多样性。数据增强可以分为有监督的数据增强和无监督的数据增强方法。本次实验使用的是有监督的训练方法,所以着重介绍有监督的数据增强的介绍。
有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法。有监督数据增强,即采用预设的数据变换规则,在已有数据的基础上进行数据的扩增,包含单样本数据增强和多样本数据增强,其中单样本又包括几何操作类,颜色变换类。几何操作类包括翻转,旋转,裁剪,变形,缩放等各类操作。颜色变换类包括噪声、模糊、颜色变换、擦除、填充等各类操作。
这里我们在网上找了10类花朵的数据,将数据进行分类,放在各个文件夹,文件名是花朵的标签,然后对图片大小统一为100*100。将数据集分成训练集(train)、验证集(validation)、测试集(test)。分别为训练集4076张,验证集811张,测试集157张,训练集需要进行数据增强,验证集和测试集不需要。

微调模型:广泛使用的模型复用方法是模型微调(fine-tuning),与特征提取互为补充。对于用于特征提取的冻结的模型基,微调是指将其顶部的几层“解冻”。并且将这解冻的几层和新增加的部分(本例中是全连接分类器)联合训练。之所以叫微调,是因为它只是略微调整了所复用的模型中更加抽象的表示,以便让这些表示与手头的问题更加相关。
冻结VGG16的卷积基是为了能够在上面训练一个随机初始化的分类器。同理,只有上面的分类器以及训练好了,才能微调卷积基的顶部几层。如果分类器没有训练好,那么训练期间通过传播网络的误差信号会特别的大,微调的几层之前学到的表示都会被破坏。
3.2数据预处理
1.批量重命名文件
# -*- coding:utf8 -*-
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = r'E:\flower_10\Blanket flower'
self.label = ' Blanket flower_'
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist) #获取文件夹内所有文件个数
i = 0 #表示文件的命名是从1开始的
for item in filelist:
if item.endswith(('.jpeg','png','jpg')):
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path),
str(self.label)+str(i) + '.jpg')
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()2.使用keras已有的数据增强的方法ImageDataGenerator
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=25,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
vertical_flip = True,
fill_mode = 'nearest')
3.3 VGG16微调模型训练与测试
微调网络的步骤如下:
1.在已经训练好的基网络(base network)上添加自定义网络
2.冻结基网络
3.训练所添加的部分
4.解冻基网络的一些层
做特征提取的时候已经完成了前三个步骤。继续进行第四步:先解冻conv_base 然后冻结其中的部分层。
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
我们将微调最后三个卷积层,也就是说,知道block4_pool的所有层都应该被冻结,而block5_conv1,block_conv2和block_conv3三层应该是可以训练的。
为什么不微调更多的层数?为什么不微调整个卷积基?你当然可以这么做,但是需要考虑一下几点:
1.卷积基中更加靠近底部的层编码的是更加通用的可复用的特征,而更靠近顶部的层编码的是更专业化的特征。
2.微调更靠近底部的层,得到的回报会更少。
3.训练的参数越多,过拟合的风险就越大。卷积基有1500万个参数,所以在小型数据集上训练这么多参数是有风险的。
4.冻结直到某一层的所有层。
- 微调模型训练
# 微调模型
model.compile(loss='categorical_crossentropy',optimizer=optimizers.RMSprop(lr=1e-5),metrics=['acc'])
history = model.fit_generator(train_generator,steps_per_epoch=25,epochs=100,validation_data=validation_generator, validation_steps=32,shuffle=True)
# 测试集的准确率
test_datagen = test_datagen.flow_from_directory(
test_dir,
target_size=(100,100),
batch_size=30,
class_mode='categorical'
)
test_loss,test_acc = model.evaluate_generator(test_datagen,steps=30)
print('test acc:',test_acc)
# 良好实践,保存模型
model.save(r'.\model\flower.h5')
- 使用matplotlib绘制loss和acc结果图
# 绘制训练过程中的损失函数曲线和精度曲线
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title('Training and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Trainig and Validation loss')
plt.legend()
plt.show()

Training and Validation acc/loss图
- 微调模型误差分析
公式:模型的错误率=预测的类别和已知的类别标签不同的个数/总的预测标签数
import os
flower_lst = ['Blanket flower', 'Daisy', 'Echinacea purpurea', 'Gazania rigens', 'Lily of the Valley', 'Lotus flower', 'Michelia figo Spreng', 'Pansy', 'Passion flower', 'Plumeria Acutifolia']
import numpy as np
from keras.models import load_model
model=load_model(r".\CNN_Flower\WY_6.h5")
from keras.preprocessing.image import ImageDataGenerator
test_datagen = ImageDataGenerator(rescale=1./255)
path = r'.\dir'
flower_path=r".\test"
test_generator = test_datagen.flow_from_directory(path, target_size=(100, 100),batch_size=1,class_mode='categorical', shuffle=False,)
#建立预测结果和文件名之间的关系
filenames = test_generator.filenames
length = len(os.listdir(flower_path))
test_generator.reset()
pred = model.predict_generator(test_generator, verbose=1, steps=length)
predicted_class_indices = np.argmax(pred, axis=1)
correct=0
error=0
filenames = test_generator.filenames
for i in range(len(filenames)):
if filenames[i].split("\\")[1].split("_")[0]==
flower_lst[predicted_class_indices[i]]:
correct=correct+1
else:
error=error+1
print("这张图片检测错误!!!!!!!", filenames[i].split("\\")[1])
print("模型识别图片的正确个数是:",correct)
print("模型识别图片的错误个数是:",error)
print("模型识别图片的准确率是:",correct/(correct+error))
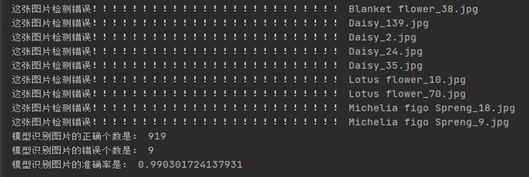
微调模型加大测试样本图片测试样图
- 微调模型预测图片标签
from keras.models import load_model
import cv2
import imageio
from keras.models import Model, load_model
from keras.applications.imagenet_utils import preprocess_input
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
test_model=load_model(r".\CNN_Flower\model.h5")
import os
import numpy as np
all_path = r".\test"
lst = os.listdir(all_path)
for file_path in os.listdir(all_path):
path = os.path.join(all_path,lst[label])
for file_name in os.listdir(path)[0:len(os.listdir(path))]:
img_path = os.path.join(path,file_name)
src=cv2.imread(img_path)
src=cv2.resize(src,(100,100))
src=src.reshape((1,100,100,3))
src=src.astype("int32")
src=src/255
predict = test_model.predict(src)
predict = np.argmax(predict, axis=1)
print(predict)
四、项目可视化
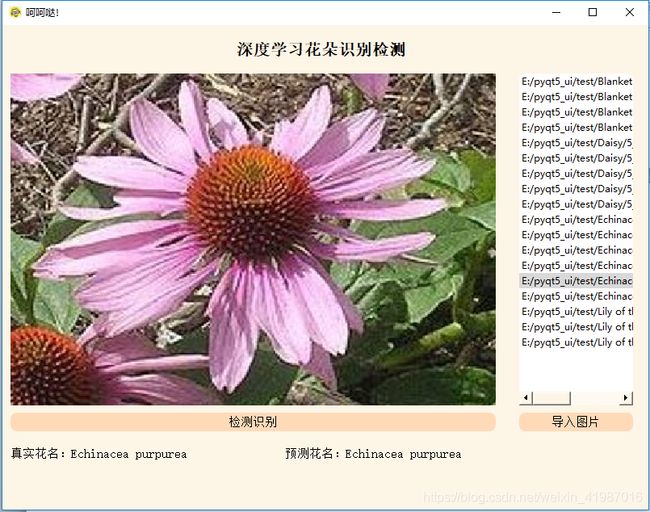
4.1 UI界面设计
首先进入cmd,然后执行命令pip install pyqt5和pip install pyqt5 pyqt5-tools。然后在这个画布上设计布局和空间,如下图所示。设计好之后在将其转为py文件。

接下来就可以在这个py文件进行功能的添加和绑定。
- 文件打开
def open_img(self):
global imgName
imgName, imgType = QtWidgets.QFileDialog.getOpenFileNames(self.pushButton_2, "多文件选择","./test", "所有文件 (*);;文本文件 (*.txt)")
if len(self.imglist) == 0:
self.imglist = imgName
else:
for i in range(len(imgName)):
self.imglist.append(imgName[i])
from functools import reduce
img_func = lambda x, y: x if y in x else x + [y]
self.imglist = reduce(img_func, [[], ] + self.imglist)
slm = QStringListModel()
slm.setStringList(self.imglist)
self.listView.setModel(slm)
print("HEHEDA")
- 点击事件
def clicked(self, qModelIndex):
global path
jpg = QtGui.QPixmap(self.imglist[qModelIndex.row()]).scaled(self.label.width(), self.label.height())
self.label.setPixmap(jpg)
path = self.imglist[qModelIndex.row()]
self.pic_exists = 1
self.predict_request = 1
real_imglabel = path.split('/')
real_imglabel = "真实花名:" + str(real_imglabel[-2])
self.label_4.setText(real_imglabel)
predict_flower_name = '预测花名:'
self.label_5.setText(predict_flower_name)
- 测试结果
def predict_request_add(self):
if self.predict_request<1:
self.predict_request = self.predict_request + 1
def predict(self):
if self.pic_exists and self.predict_request:
print("模型测试正式开始")
import os
import cv2
import numpy as np
img_path = path
src = cv2.imread(img_path)
src = cv2.resize(src, (100, 100))
src = src.reshape((1, 100, 100, 3))
src = src.astype("int32")
src = src / 255
predict = self.model.predict(src)
predict = np.argmax(predict, axis=1)
print("预测结果是:")
print(self.img_label[predict[0]])
predict_flower_name = self.img_label[predict[0]]
predict_flower_name = '预测花名:' + predict_flower_name
self.label_5.setText(predict_flower_name)
print("执行中....")
self.predict_request = 0
else:
print("请选择图片!!!!!")
print("执行结束")
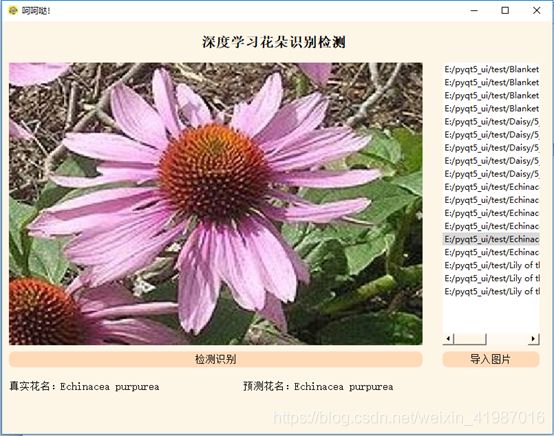
- 初始化界面展示


- UI界面预测图片效果展示


我是热爱学习的呵呵哒~如果你觉得文章很棒,对你有帮助的话,可以点赞+收藏+加关注喔~
如果文章有不正确的地方,欢迎交流指正,我将虚心请教~o(>ω<)o
我会定期更新文章,继续为您提供优质文章
后期呵呵哒将会把整个项目发到Github和其他平台供大家参考学习!!!