Spark核心之Spark Streaming
前面说到Spark的核心技术的时候,有和大家说过,有五大核心技术,不知道大家还记不记得;
给大家回忆下,这五大核心技术:分布式计算引擎Spark Core 、基于Hadoop的SQL解决方案SparkSQL 、可以实现高吞吐量、具备容错机制的准实时流处理系统Spark Streaming、分布式图处理框架Spark GraphX和构建在Spark上的分布式机器学习库Spark MLlib,现在应该有个印象了吧,其它的我就不多说了,今天主要是对Spark Streaming做个简单介绍,以便理解。
Spark Streaming理解
Spark Streaming 是核心 Spark API 的扩展,支持可伸缩、高吞吐量、容错的实时数据流处理。数据可以从许多来源获取,如 Kafka、Flume、Kinesis 或 TCP sockets,可以使用复杂的算法处理数据,这些算法用高级函数表示,如 map、reduce、join 和 window。
最后,处理后的数据可以推送到文件系统、数据库和活动仪表板。实际上,还可以将 Spark 的 MLlib 机器学习和 GraphX 图形处理算法应用于数据流。Spark Streaming 处理的数据流如下图所示。

流是什么?
简单理解,就好比水流,是不是有源头,但不知道终点,有始没有终,你永远不知道水流什么时候结束,会一直进行传输,数据流也类似这样,有个源头不断往里面塞新数据,但不知道什么时候终止;那么数据流也就是分为数据的流入,数据的处理和数据的流出,这样是不是就很好理解。
流处理
是一种允许用户在接收到的数据后的短时间内快速查询连续数据流和检测条件的技术
为什么需要流处理?
- 它能够更快的提供洞察力,通常在毫秒到秒之间
- 大部分数据的产生过程都是一个永无止境的事件流
- 要进行批处理,需要存储它,在某个时间停止数据收集,并处理数据
- 流处理自然适合时间序列数据和检测模式随着时间推移
工作原理
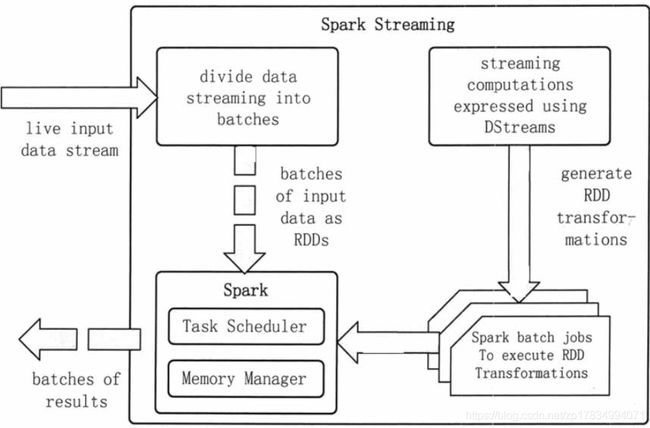
Spark Streaming 也是基于核心 Spark 的。Spark Streaming 在内部的处理机制是,接收实时的输入数据流,并根据一定的时间间隔(如 1 秒)拆分成一批批的数据,然后通过 Spark Engine 处理这些批数据,最终得到处理后的一批批结果数据。
工作原理如下图所示:

Spark 流提供了一种高级抽象,称为离散流或 DStream,它表示连续的数据流。DStreams 可以从 Kafka、Flume 和 Kinesis 等源的输入数据流创建,也可以通过对其他 DStreams 应用高级操作创建。在内部,DStream 表示为 RDDs 序列。
一批数据在 Spark 内核中对应一个 RDD 实例。因此,对应流数据的 DStream 可以看成是一组 RDD,即 RDD 的一个序列。也就是说,在流数据分成一批一批后,会通过一个先进先出的队列,Spark Engine 从该队列中依次取出一个个批数据,并把批数据封装成一个 RDD,然后再进行处理。
解析
- 离散流(Discretized Stream)或 DStream
Spark Streaming 对内部持续的实时数据流的抽象描述,即处理的一个实时数据流,在 Spark Streaming 中对应于一个 DStream 实例。 - 时间片或批处理时间间隔(BatchInterval)
拆分流数据的时间单元,一般为 500 毫秒或 1 秒。 - 批数据(BatchData)
一个时间片内所包含的流数据,表示成一个 RDD。 - 窗口(Window)
一个时间段。系统支持对一个窗口内的数据进行计算 - 窗口长度(Window Length)
一个窗口所覆盖的流数据的时间长度,必须是批处理时间间隔的倍数。 - 滑动步长(Sliding Interval)
前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。 - Input DStream
一个 Input DStream 是一个特殊的 DStream。
Spark Streaming 系统架构
Spark Streaming 引入了一个新结构,即 DStream,它可以直接使用 Spark Engine 中丰富的库,并且拥有优秀的故障容错机制。
传统流处理采用的是一次处理一条记录的方式,而 Spark Streaming 采用的是将流数据进行离散化处理,使之能够进行秒级以下的微型批处理。同时,Spark Streaming 的 Receiver 并行接收数据,将数据缓存至 Spark 工作结点的内存中。
经过延迟优化后,Spark Engine 对短任务(几十毫秒)能够进行批处理,并且可将结果输出至别的系统中。
值得注意的是,与传统连续算子模型不同,传统模型是静态分配给一个结点进行计算的,而 Spark Task 可基于数据的来源及可用资源情况动态分配给工作结点。这能够更好地实现流处理所需要的两个特性:负载均衡与快速故障恢复。此外,Executor 除了可以处理 Task 外,还可以将数据存在 cache 或者 HDFS 上。
Spark Streaming 中的流数据就是 Spark 的弹性分布式数据集(RDD),是 Spark 中容错数据集的一个基本抽象。正是如此,这些流数据才能使用 Spark 的任意指令与库。
Spark Streaming 的系统架构如下图所示:

计算流程
Spark Streaming 是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是 Spark Core。
park Streaming 首先把输入数据按照批段大小(如 1 秒)分成一段一段的数据(DStream),并把每一段数据都转换成 Spark 中的 RDD,然后将 Spark Streaming 中对 DStream 的 Transformation 操作变为 Spark 中对 RDD 的 Transformation 操作,并将操作的中间结果保存在内存中。
整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。如下图所示是整个计算过程:
动态负载均衡
Spark 系统将数据划分为小批量,允许对资源进行细粒度分配。
传统的流处理系统采用静态方式分配任务给结点,如果其中的一个分区的计算比别的分区更密集,那么该结点的处理将会遇到性能瓶颈,同时将会减缓管道处理。而在 Spark Streaming 中,作业任务将会动态地平衡分配给各个结点,一些结点会处理数量较少且耗时较长的任务,别的结点将会处理数量更多且耗时更短的任务。
动态负载均衡就能够根据工作量动态调整结点间的资源分配。这样工作结点间的不平衡分配加载造成部分结点性能的运行瓶颈的难题也会迎刃而解。