Torch.nn模块学习-池化
池化对数据起到了浓缩的效果,通过池化可以减少数据量,降低内存压力,简单地理解,池化操作都是通过池化的kernel的选取一定的区域,通过某种计算将这个区域一系列数值转化为一个数值,需要注意的是:对于池化操作来说,池化的步长一般是卷积核大小。
该库提供了多种池化的类,最大池化、平均池化、最大自适应池化等操作。下面以二维数据处理为例子,列出常用的池化操作。
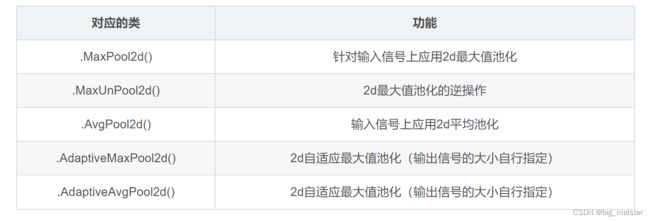
本次项目中使用的操作:
nn.Sequential
介绍
一个序列容器,用于搭建神经网络的模块,被按照被传入构造器的顺序添加到nn.Sequential()r容器中,除此之外,一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中,利用nn.Sequential()搭建好的模型架构,模型前向传播时调用 f o r w a r d ( ) forward() forward()方法,模型接受的输入首先被传入的nn.Sequential()包含的第一个网络模块中,然后**,第一个网络模块输出传入到第二个网咯模块作为输入**。按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
本质作用
按照上面说法,与一层一层的单独调用的模块组成的序列相比,
n n . S e q u e n t i a l ( ) nn.Sequential() nn.Sequential(),可以允许将整个容器视为单个模块,(相当于把多个模块封装成一个模块)forward()方法接收输入之后,
nn.Sequential(),按照内部模块的顺序自动依次计算并输出结果。
这意味着,我们可以利用其来自定义网络层。:
nn.Conv2d
nn.Conv2d对有多个输入平面组成的输入信号进行二维卷积。


函数详解
- torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
- in_channels: 输入图像通道数。
- out_channels:卷积产生的通道数。
- kernel_size: 卷积核尺寸,可以设为1个int型数或者一个(int, int)型的元组。例如(2,3)是高2宽3卷积核
- stride: 卷积步长:默认为1,可以设为1个int型数或者一个(int, int)型的元组
- padding: 填充操作:控制padding_mode的数目。
- padding_mode:padding模式,默认为Zero-padding
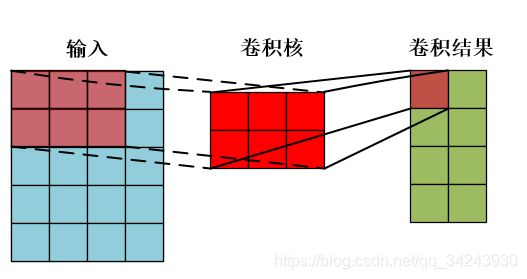
- dilation:扩张操作,控制kernel点(卷积核点)的间距,默认值为1.
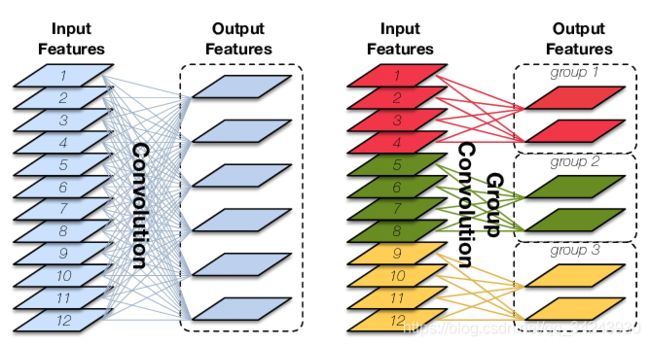
- groups:group参数作用是控制分组卷积,默认不分组,为1组。
- bias:为真,则在输出中添加一个可学习的偏差,默认为True.
参数dilation-扩张卷积
参数groups-分组卷积
nn.BatchNorm2d
paddle.nn.BatchNorm2D(num_features, momentum=0.9, epsilon=1e-05, weight_attr=None, bias_attr=None, data_format='NCHW', name=None):
目的:
加速神经网络的收敛过程,以及提高训练过程中的稳定性。
应用场景
通常用于解决多层神经网络中间层的协方差偏移问题。
行为方式
使一批(Batch) feature map满足均值为0,方差为1的分布规律。这样不仅数据分布一致,而且避免发生梯度消失。
通俗解释
类似于网咯输入中进行零均值化和方差归一化操作。不过是在中间层输入中的操作而已。
作用:卷积之后会添加BatchNorm2d进行数据的归一化处理,着使得数据在进行Relu之前,不会因为数据过大而导致网络性能不稳定。
数学原理
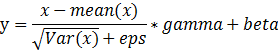
参数解释

在mini-batch上计算维度,的均值和标准差,gamma和beta是可学习的参数向量,gamma默认设置为1,beta默认设置为0,其中,标准差是通过有偏估计来计算的。等同于:
torch.var(input,unbiased=False)
通常默认情况下,训练过程中的BatchNorm 层会保持对其计算的均值和方差的估计,然后再测试时候,使用这个均值和方差进行标准化。Running estimates保持默认动量为0.1 。
如果参数track_running_stats被设置为False,BatchNorm层将不会进行running estimates,Batch统计的均值和方差将会使用测试数据的均值和方差来代替。
BatchNorm中的momentum参数与优化器中的momentum和传统概念中的momentum不同。
在BatchNorm中,Running statistics的更新规则是:

- affine参数设为True表示weight和bias将被使用
nn.ReLU
R e L U ( x ) = m a x ( 0 , m a x ) ReLU(x)=max(0, max) ReLU(x)=max(0,max)
nn.ReLU()函数默认inplace 默认是False
- inplace = False
输出对象地址,不会修改输入对象的值,而是返回一个新创建的对象,所以打印出对象存储地址不同,类似于C语言的值传递 - inplace = True
输出对象地址,会修改输入对象的值,所以打印出对象存储地址相同,类似于C语言的地址传递
inplace = True,节省反复申请与释放内存的空间与时间,只是将原来的地址传递,效率更好。
nn.MaxPool2d
# 这个类是是许多池化类的基类,这里有必要了解一下
class _MaxPoolNd(Module):
__constants__ = ['kernel_size', 'stride', 'padding', 'dilation',
'return_indices', 'ceil_mode']
return_indices: bool
ceil_mode: bool
# 构造函数,这里只需要了解这个初始化函数即可。
def __init__(self, kernel_size: _size_any_t, stride: Optional[_size_any_t] = None,
padding: _size_any_t = 0, dilation: _size_any_t = 1,
return_indices: bool = False, ceil_mode: bool = False) -> None:
super(_MaxPoolNd, self).__init__()
self.kernel_size = kernel_size
self.stride = stride if (stride is not None) else kernel_size
self.padding = padding
self.dilation = dilation
self.return_indices = return_indices
self.ceil_mode = ceil_mode
def extra_repr(self) -> str:
return 'kernel_size={kernel_size}, stride={stride}, padding={padding}' \
', dilation={dilation}, ceil_mode={ceil_mode}'.format(**self.__dict__)
class MaxPool2d(_MaxPoolNd):
kernel_size: _size_2_t
stride: _size_2_t
padding: _size_2_t
dilation: _size_2_t
def forward(self, input: Tensor) -> Tensor:
return F.max_pool2d(input, self.kernel_size, self.stride,
self.padding, self.dilation, self.ceil_mode,
self.return_indices)
MaxPool2d 这个类的实现十分简单。
先来看一下基本参数,一共六个:
- kernel_size :表示做最大池化的窗口大小,可以是单个值,也可以是tuple元组
- stride :步长,可以是单个值,也可以是tuple元组
- padding :填充,可以是单个值,也可以是tuple元组
- dilation :控制窗口中元素步幅
- return_indices :布尔类型,返回最大值位置索引
- ceil_mode :布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整
关于kernel_size的解释
这里的kernel_szie跟卷积核不是一个东西,kernel_size可以看作是一个滑动窗口,这个窗口的大小由自己定,如果输入的是单个值,例如3,那么窗口的大小都是 3 × 3 3 \times 3 3×3。还可以输入元组 ( 3 , 2 ) (3,2) (3,2),
那么窗口的大小都是 3 × 2 3 \times 2 3×2
最大池化的方法都是取这个窗口覆盖元素中的最大值。
关于stride的解释。
上一个参数,我们确定了滑动窗口的大小,现在我们来确定这个窗口如何进行滑动的,如果不指定这个参数, 那么默认步长跟最大池化窗口一致,如果指定了参数,那么将按照我们指定的参数进行滑动。例如 s t r i d e = ( 2 , 3 ) stride =(2,3) stride=(2,3) 那么窗口将每次向右滑动3个窗口的位置**,或者向下滑动两个元素的位置,**。
关于padding的理解
这参数控制如何进行填充,填充值默认为0,如果是单个值,例如1,那么将在周围填充一圈0,还可以用元组指定如何填充,例如:
p a d d i n g = ( 2 , 1 ) padding = (2,1) padding=(2,1),表示再上下两个方向上填充两个0,在左右方向上各填充一个0.
关于return_indices的详解
这是个布尔类型值,表示返回值中是否包含最大值位置的索引。注意这个最大值指的是在所有窗口中产生的最大值,如果窗口产生的最大值总共有5个,就会有5个返回值。
关于ceil_mode详解
这个也是布尔类型值,它决定的是在计算输出结果形状的时候,是使用向上取整还是向下取整。怎么计算输出形状,下面会讲到。一看就知道了。(向上取整,还是向下取整)
最大池化输出形状计算

总结
会自己根据项目进行各种参数的调节,会自己进行各种的调参以及计算都行啦的样子与打算,。