基于CNN-LSTM命名实体识别和关系抽取联合学习
Word2vec
Gensim训练Word2vec步骤
-
1 将语料库预处理:一行一个文档或句子,将文档或句子分词(以空格分割,英文可以不用分词,英文单词之间已经由空格分割,中文预料需要使用分词工具进行分词,
常见的分词工具有StandNLP、ICTCLAS、Ansj、FudanNLP、HanLP、结巴分词等); -
2 将原始的训练语料转化成一个sentence的迭代器,每一次迭代返回的sentence是一个word(utf-8格式)的列表。可以使用Gensim中word2vec.py中的LineSentence()方法实现;
-
3 将上面处理的结果输入Gensim内建的word2vec对象进行训练即可:
import os
import json
from gensim.models.word2vec import LineSentence, Word2Vec
# 将json转换为原文,一行一句
def func(fin, fout):
for line in fin:
line = line.strip()
if not line:
continue
sentence = json.loads(line)
sentence = sentence["sentText"].strip().strip('"').lower()
fout.write(sentence + '\n')
def make_corpus():
with open('data/NYT_CoType/corpus.txt', 'wt', encoding='utf-8') as fout:
with open('data/NYT_CoType/train.json', 'rt', encoding='utf-8') as fin:
func(fin, fout)
with open('data/NYT_CoType/test.json', 'rt', encoding='utf-8') as fin:
func(fin, fout)
if __name__ == "__main__":
if not os.path.exists('data/NYT_CoType/corpus.txt'):
make_corpus()
sentences = LineSentence('data/NYT_CoType/corpus.txt')
'''
(1)size:是指词向量的维度,默认为100。这个维度的取值一般与我们的语料的大小相关
(2)workers:用于控制训练的并行数。
(3)sg:训练模型 0表示CBOW,1表示skip-gram
(4)iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
(5)negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间
'''
model = Word2Vec(sentences, sg=1, size=300, workers=4, iter=8, negative=8)
word_vectors = model.wv
word_vectors =word_vectors
word_vectors.save('data/NYT_CoType/word2vec')
word_vectors.save_word2vec_format('data/NYT_CoType/word2vec.txt', fvocab='data/NYT_CoType/vocab.txt')
Tagging scheme
根据中科院论文中的标注,这里举例如下:

预处理过程主要注意几个要点:
1 转换大小写
2 长度不够要padding
3 将带声调音节(如一些法语单词)变形,这里采用先转换为unicode再变回去的办法
def make_tag_set(tag_set, relation_label):
'''
make_tag_set(tag_set, relation_mention["label"])
'''
if relation_label == "None":
return
for pos in "BIES":
for role in "12":
tag_set.add("-".join([pos, relation_label, role]))#pos-relation_label-role
def update_tag_seq(em_text, sentence_text, relation_label, role, tag_set, tags_idx):
'''
res1 = update_tag_seq(em1_text, sentence_text, relation_mention["label"], 1, tag_set, tags_idx)
B-begin,I-inside,O-outside,E-end,S-single
以下均以词为单位
'''
overlap = False
start = search(em_text, sentence_text)#首词的词index
tag = "-".join(["S", relation_label, str(role)])
if len(em_text) == 1:
if tags_idx[start] != tag_set["O"]:
overlap = True
tags_idx[start] = tag_set[tag]
else:
tag = "B" + tag[1:]
if tags_idx[start] != tag_set["O"]:
overlap = True
tags_idx[start] = tag_set[tag]
tag = "E" + tag[1:]
end = start + len(em_text) - 1
if tags_idx[end] != tag_set["O"]:
overlap = True
tags_idx[end] = tag_set[tag]
tag = "I" + tag[1:]
for index in range(start + 1, end):
if tags_idx[index] != tag_set["O"]:
overlap = True
tags_idx[index] = tag_set[tag]
return overlap
def prepare_data_set(fin, charset, vocab, relation_labels, entity_labels, tag_set, dataset, fout):
'''
res=prepare_data_set(fin, charset, vocab, relation_labels, entity_labels, tag_set, train, fout)
fin:data/NYT_CoType/train.json
'''
num_overlap = 0
for line in fin:
overlap = False
line = line.strip()#移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
if not line:
continue
sentence = json.loads(line)
for entity_mention in sentence["entityMentions"]:
entity_labels.add(entity_mention["label"])
for relation_mention in sentence["relationMentions"]:
relation_labels.add(relation_mention["label"])
make_tag_set(tag_set, relation_mention["label"])
sentence_text = sentence["sentText"].strip().strip('"')
sentence_text = unicodedata.normalize('NFKD', sentence_text).encode('ascii','ignore').decode().split()#原句的一个个词
#split():空白符分隔,不包含序列开头或末尾的空白符。
length_sent = len(sentence_text)
if length_sent > MAX_SENT_LENGTH:
continue
lower_sentence_text = [token.lower() for token in sentence_text]
sentence_idx = prepare_sequence(lower_sentence_text, vocab)#返回vocab编号构成的list
tokens_idx = []#字母编号
for token in sentence_text:
if len(token) <= MAX_TOKEN_LENGTH:
tokens_idx.append(prepare_sequence(token, charset) + [charset["" ]]*(MAX_TOKEN_LENGTH-len(token)))#补全
else:
tokens_idx.append(prepare_sequence(token[0:13] + token[-7:], charset))#两端开花
tags_idx = [tag_set["O"]] * length_sent #tag2id
for relation_mention in sentence["relationMentions"]:
if relation_mention["label"] == "None":
continue
em1_text = unicodedata.normalize('NFKD', relation_mention["em1Text"]).encode('ascii','ignore').decode().split()
res1 = update_tag_seq(em1_text, sentence_text, relation_mention["label"], 1, tag_set, tags_idx)
em2_text = unicodedata.normalize('NFKD', relation_mention["em2Text"]).encode('ascii','ignore').decode().split()
res2 = update_tag_seq(em2_text, sentence_text, relation_mention["label"], 2, tag_set, tags_idx)
if res1 or res2:
num_overlap += 1
overlap = True
dataset.append((sentence_idx, tokens_idx, tags_idx))
# if overlap:
# fout.write(line+"\n")
newsent = dict()
newsent['tokens'] = lower_sentence_text
newsent['tags'] = tags_idx
fout.write(json.dumps(newsent)+'\n')
return num_overlap
End2End Model
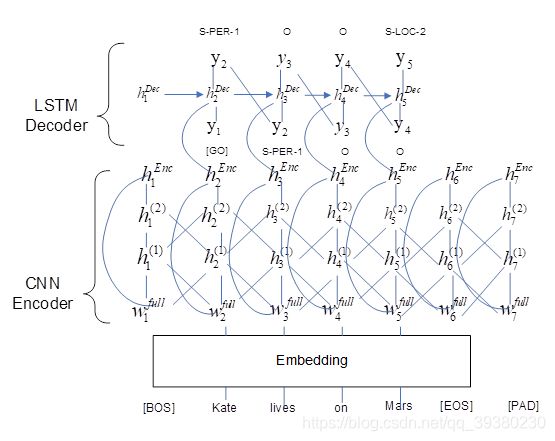
CNN Encoder
其中,第一层卷积层可表示为
![]()
卷积核为3,再经过两层卷积
LSTM Decoder

import torch
import torch.nn as nn
import torch.nn.functional as F
from conv_net import ConvNet
import numpy as np
import torch.autograd as autograd
from torch.autograd import Variable
class CharEncoder(nn.Module):
"""
Input: (batch_size, seq_len)
Output: (batch_size, conv_size)
"""
def __init__(self, char_num, embedding_size, channels, kernel_size, padding_idx, dropout, emb_dropout):
super(CharEncoder, self).__init__()
self.embed = nn.Embedding(char_num, embedding_size, padding_idx=padding_idx)
self.drop = nn.Dropout(emb_dropout)
self.conv_net = ConvNet(channels, kernel_size, dropout=dropout)
self.init_weights()
def forward(self, inputs):
seq_len = inputs.size(1)
# (batch_size, seq_len) -> (batch_size, seq_len, embedding_size) -> (batch_size, embedding_size, seq_len)
embeddings = self.drop(self.embed(inputs)).transpose(1, 2).contiguous()
# (batch_size, embedding_size, seq_len) -> (batch_size, conv_size, seq_len)
# -> (batch_size, conv_size, 1) -> (batch_size, conv_size)
return F.max_pool1d(self.conv_net(embeddings), seq_len).squeeze()
def init_weights(self):
nn.init.kaiming_uniform_(self.embed.weight.data, mode='fan_in', nonlinearity='relu')
class WordEncoder(nn.Module):
"""
Input: (batch_size, seq_len), (batch_size, seq_len, char_features)
"""
def __init__(self, weight, channels, kernel_size, dropout, emb_dropout):
super(WordEncoder, self).__init__()
self.embed = nn.Embedding.from_pretrained(weight, freeze=False)
self.drop = nn.Dropout(emb_dropout)
self.conv_net = ConvNet(channels, kernel_size, dropout, dilated=True, residual=False)
def forward(self, word_input, char_input):
# (batch_size, seq_len) -> (batch_size, seq_len, embedding_size)
# -> (batch_size, seq_len, embedding_size + char_features)
# -> (batch_size, embedding_size + char_features, seq_len)
embeddings = torch.cat((self.embed(word_input), char_input), 2).transpose(1, 2).contiguous()
#print("embeddings:----------",embeddings.size())
# (batch_size, embedding_size + char_features, seq_len) -> (batch_size, conv_size, seq_len)
conv_out = self.conv_net(self.drop(embeddings))
# (batch_size, conv_size, seq_len) -> (batch_size, conv_size + embedding_size + char_features, seq_len)
# -> (batch_size, seq_len, conv_size + embedding_size + char_features)
return torch.cat((embeddings, conv_out), 1).transpose(1, 2).contiguous()
#self.char_conv_size+self.word_embedding_size+self.word_conv_size, num_tag
class Decoder(nn.Module):
def __init__(self,input_size,hidden_dim,output_size,NUM_LAYERS):
super(Decoder, self).__init__()
self.input_size=input_size
self.hidden_dim = hidden_dim
self.output_size=output_size
self.lstm = nn.LSTM(input_size, hidden_dim, num_layers = NUM_LAYERS,bidirectional=True)#update on 5.21
self.hidden2label = nn.Linear(2*self.hidden_dim, output_size)#update on 5.21
self.init_weight()
def forward(self, inputs):
self.lstm.flatten_parameters()
lstm_out, self.hidden = self.lstm(inputs,None)
y = self.hidden2label(lstm_out)
return y
def init_weight(self):
nn.init.kaiming_uniform_(self.hidden2label.weight.data, mode='fan_in', nonlinearity='relu')
def init_hidden(self, batch_size):
return (autograd.Variable(torch.randn(1, batch_size, self.hidden_dim)),
autograd.Variable(torch.randn(1, batch_size, self.hidden_dim)))
class Model(nn.Module):
def __init__(self, charset_size, char_embedding_size, char_channels, char_padding_idx, char_kernel_size,
weight, word_embedding_size, word_channels, word_kernel_size, num_tag, dropout, emb_dropout):
super(Model, self).__init__()
self.char_encoder = CharEncoder(charset_size, char_embedding_size, char_channels, char_kernel_size,
char_padding_idx, dropout=dropout, emb_dropout=emb_dropout)
self.word_encoder = WordEncoder(weight, word_channels, word_kernel_size,
dropout=dropout, emb_dropout=emb_dropout)
self.drop = nn.Dropout(dropout)
self.char_conv_size = char_channels[-1]
self.word_embedding_size = word_embedding_size
self.word_conv_size = word_channels[-1]
#self.decoder = nn.Linear(self.char_conv_size+self.word_embedding_size+self.word_conv_size, num_tag)
self.decoder = Decoder(self.char_conv_size+self.word_embedding_size+self.word_conv_size,
self.char_conv_size + self.word_embedding_size + self.word_conv_size,
num_tag,NUM_LAYERS=1)
self.init_weights()
def forward(self, word_input, char_input):
batch_size = word_input.size(0)
seq_len = word_input.size(1)
char_output = self.char_encoder(char_input.view(-1, char_input.size(2))).view(batch_size, seq_len, -1)
word_output = self.word_encoder(word_input, char_output)
y = self.decoder(word_output)
return F.log_softmax(y, dim=2)
def init_weights(self):
pass
#self.decoder.bias.data.fill_(0)
#nn.init.kaiming_uniform_(self.decoder.weight.data, mode='fan_in', nonlinearity='relu')
word_embeddings = torch.tensor(np.load("data/NYT_CoType/word2vec.vectors.npy"))
print(word_embeddings.shape)
dropout=(0.5,)
emb_dropout=0.25
if __name__ == "__main__":
model=Model(charset_size=96, char_embedding_size=50, char_channels=[50, 50, 50, 50],
char_padding_idx=94, char_kernel_size=3, weight=word_embeddings,
word_embedding_size=300, word_channels=[350, 300, 300, 300],
word_kernel_size=3, num_tag=193, dropout=0.5,
emb_dropout=0.25)
print(model)
Evaluate
def measure(output, targets, lengths):
assert output.size(0) == targets.size(0) and targets.size(0) == lengths.size(0)
tp = 0
tp_fp = 0
tp_fn = 0
batch_size = output.size(0)
output = torch.argmax(output, dim=-1)#得到最大值的序号索引,dim:要消去的维度
for i in range(batch_size):
length = lengths[i]
out = output[i][:length].tolist()
target = targets[i][:length].tolist()
out_triplets = get_triplets(out)
tp_fp += len(out_triplets)
target_triplets = get_triplets(target)
tp_fn += len(target_triplets)
for target_triplet in target_triplets:
for out_triplet in out_triplets:
if out_triplet == target_triplet:
tp += 1
return tp, tp_fp, tp_fn
def evaluate(data_groups):
model.eval()
total_loss = 0
count = 0
TP = 0
TP_FP = 0
TP_FN = 0
with torch.no_grad():#不跟踪计算梯度
for batch_indices in GroupBatchRandomSampler(data_groups, args.batch_size, drop_last=False):
sentences, tokens, targets, lengths = get_batch(batch_indices, train_data)
output = model(sentences, tokens)
tp, tp_fp, tp_fn = measure(output, targets, lengths)
TP += tp
TP_FP += tp_fp
TP_FN += tp_fn
output = pack_padded_sequence(output, lengths, batch_first=True).data
targets = pack_padded_sequence(targets, lengths, batch_first=True).data
loss = criterion(output, targets)
total_loss += loss.item()
count += len(targets)
return total_loss / count, TP/TP_FP, TP/TP_FN, 2*TP/(TP_FP+TP_FN)
def get_triplets(tags):
temp = {}
triplets = []
for idx, tag in enumerate(tags):
if tag == tag_set["O"]:
continue
pos, relation_label, role = tag_set[tag].split("-")
if pos == "B" or pos == "S":
if relation_label not in temp:
temp[relation_label] = [[], []]
temp[relation_label][int(role) - 1].append(idx)
for relation_label in temp:
role1, role2 = temp[relation_label]
if role1 and role2:
len1, len2 = len(role1), len(role2)
if len1 > len2:
for e2 in role2:
idx = np.argmin([abs(e2 - e1) for e1 in role1])
e1 = role1[idx]
triplets.append((e1, relation_label, e2))
del role1[idx]
else:
for e1 in role1:
idx = np.argmin([abs(e2 - e1) for e2 in role2])
e2 = role2[idx]
triplets.append((e1, relation_label, e2))
del role2[idx]
return triplets