机器学习_第一天(特征工程:特征抽取+特征预处理+特征降维)

机器学习
算法是核心,数据和计算是基础清楚算法原理与适用场景即可,不用深究数学问题。大部分复杂模型的算法设计都是算法工程师在做,机器学习重点是:
- 分析大量的数据
- 分析具体的业务
- 应用常见的算法
- 特征工程、调参数、优化
机器学习的数据多为文件形式(csv),不使用mysql(mysql读取速度慢;格式不符合机器学习要求)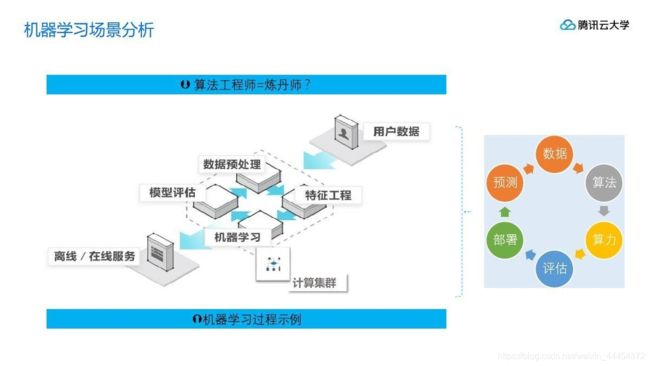
1、可用数据集
- Kaggle
特点:
大数据竞赛平台
80万科学家
真实数据
数据量巨大 - UCI数据集
特点:
覆盖科学、生活、经济等领域
收录了360个数据集
数据量几十万 - scikit-learn库
特点:
数据量较小
方便学习
2、特征工程
特征工程直接影响模型的预测结果。特征工程是将原始数据转换为更好地代表预测模型潜在问题特征的过程,从而提高了对未知数据的模型准确性。
- 数据的结构
结构:特征值+目标值
注:有些数据集可以没有目标值 - 对特征的处理
机器学习不用对重复数据进行去重,重复数据重复学习不影响模型
pandas:读取数据、简易处理格式
sklearn:对特征的处理提供了强大的接口
2.1 特征抽取
针对字符串类型数据进行数值的转换(特征化),特征值化是为了计算机更好的去理解数据
sklearn特征抽取的API:sklearn.feature_extraction
2.1.1 字典特征抽取
对字典数据进行特征值化:sklearn.feature_extraction.DictVectorizer
DictVectorizer(sparse=False)
- DictVectorizer.fit_transform(X)
X:字典或者包含字典的迭代器
返回值:默认返回sparse矩阵,sparse=False返回ndarry数组 - DictVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式 - DictVectorizer.get_feature_names()
返回类别名称 - DictVectorizer.transform(X)
按照原先的标准转换
def dict_demo():
"""
字典特征抽取
:return:
"""
data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=True)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray(), type(data_new))
print("data_new sparse矩阵:\n", data_new, type(data_new))
print("特征名字:\n", transfer.get_feature_names())
return None执行结果:
a. one-hot编码:
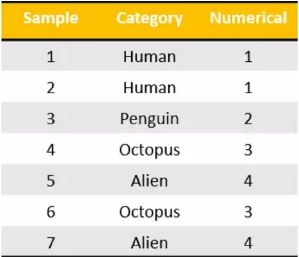
将每一个类别生成一个布尔列,同一个样本只有一个布尔列取值为1,避免单纯的数字分组产生优先级问题
2.1.2 文本特征抽取
a. 词频矩阵(Count)
对文本数据进行特征值化:sklearn.feature_extraction.text.CountVectorizer
作用:通过词频分析文本类型、情感方向(单个英文字母/中文词无分类依据,不计算词频)
CountVectorizer()
- CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵,通过.toarray()转换成数组类型 - CountVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式 - CountVectorizer.get_feature_names()
返回值:单词列表
e.g 英文文本特征抽取 -
def count_demo(): """ 文本特征抽取:CountVecotrizer :return: """ data = ["life is short,i like like python", "life is too long,i dislike python"] # 1、实例化一个转换器类 transfer = CountVectorizer(stop_words=["is", "too"]) # 2、调用fit_transform data_new = transfer.fit_transform(data) print("data_new:\n", data_new.toarray()) print("data_new sparse矩阵:\n", data_new) print("特征名字:\n", transfer.get_feature_names()) return None执行结果:英文文本特征抽取
 text.CountVectorizer以空格视为词语的分隔,对于中文需要先进行分词处理才能详细的进行特征值化
text.CountVectorizer以空格视为词语的分隔,对于中文需要先进行分词处理才能详细的进行特征值化
jieba.cut(’ '):对中文句子进行分词,返回的是一个迭代器,要先转换成列表,再以" ".join()相连成字符串,才能用于文本特征抽取。
e.g 中文文本特征抽取
def count_demo():
"""
文本特征抽取:CountVecotrizer
:return:
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["is", "too"])
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("data_new sparse矩阵:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None执行结果:

def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
执行结果:
data_new:
[[0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 1 0]
[0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 0 1]
[1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0 0]]
特征名字:
['不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '还是', '这样']
b. 权重矩阵(TF-IDF)—分类机器学习算法的的重要依据
- 词频矩阵(tf:term frequency),统计词语出现次数
- 逆文档频率(idf:iverse document frequency),log(总文档数量/改词出现的文档数量),计算得到的输⼊值越⼩,log返回结果越⼩。
- 重要性程度 = tf * idf,log排除各文档公共词频高度重合的无意义词汇,剩下的词再通过词频判断词语的重要性,从而推断文章主题。
对文本数据进行特征值化:sklearn.feature_extraction.text.TfidfVectorizer
作用:评估词对于一个文件集或一个语料库中的其中一份文件的重要程度。若某个词在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词重要性程度高,具有很好的类别区分能力。
TfidfVectorizer(stop_words=None)
- TfidfVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵 - TfidfVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式 - TfidfVectorizer.get_feature_names()
返回值:单词列表
def tfidf_demo():
"""
用TF-IDF的方法进行文本特征抽取
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = TfidfVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
执行结果:
data_new:
[[0. 0.21821789 0. 0. 0. 0.43643578
0. 0. 0. 0. 0. 0.21821789
0. 0.21821789 0. 0. 0. 0.
0.21821789 0. 0.43643578 0. 0.21821789 0.
0.43643578 0.21821789 0. 0. 0. 0.21821789
0.21821789 0. 0. 0.21821789 0. ]
[0. 0. 0.2410822 0. 0. 0.
0.2410822 0.2410822 0.2410822 0. 0. 0.
0. 0. 0. 0. 0.2410822 0.55004769
0. 0. 0. 0.2410822 0. 0.
0. 0. 0.48216441 0. 0. 0.
0. 0. 0.2410822 0. 0.2410822 ]
[0.15895379 0. 0. 0.63581516 0.47686137 0.
0. 0. 0. 0.15895379 0.15895379 0.
0.15895379 0. 0.15895379 0.15895379 0. 0.12088845
0. 0.15895379 0. 0. 0. 0.15895379
0. 0. 0. 0.31790758 0.15895379 0.
0. 0.15895379 0. 0. 0. ]]
特征名字:
['不会', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '还是', '这样']
2.2 特征的预处理:对数据进行处理
特征的预处理对数据进行处理,通过特定的统计方法(数学方法)将数据转换成算法要求的数据
- 数据预处理方法:
数值型数据–标准缩放:
1. 归一化
2. 标准化
3. 缺失值
类别型数据:one-hot编码
时间类型:时间的切分
sklearn特征预处理的API:sklearn.preprocessing
2.2.1 归一化
通过对原始数据进行变换,把数据映射到(默认为[0,1])之间。当多个特征同等重要时,要使用归一化,避免因数量级上的不同导致某⼀个特征对最终结果造成更⼤影响。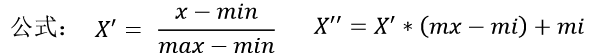
注:作用于每一列特征,max为一列的最大值,min为一列的最小值。X’’为最终结果,mx、mi分别为指定区间,值默认mx为1、mi为0
缺点:最大值与最小值非常容易受异常点的影响,使得公式出现偏差。所以归一化方法鲁棒性(稳定性)较差,只适合传统精确小数据场景(此场景很少)。
对数值数据进行归一化:sklearn.preprocessing.MinMaxScaler
MinMaxScalar(feature_range=(0,1))
- MinMaxScalar.fit_transform(X)
X:numpy array格式的二维数据[n_samples,n_features]
返回值:转换后的形状相同的array
def minmax_demo():
"""
归一化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3])
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None执行结果:
data:
milage Liters Consumtime
0 40920 8.326976 0.953952
1 14488 7.153469 1.673904
2 26052 1.441871 0.805124
3 75136 13.147394 0.428964
4 38344 1.669788 0.134296
.. ... ... ...
995 11145 3.410627 0.631838
996 68846 9.974715 0.669787
997 26575 10.650102 0.866627
998 48111 9.134528 0.728045
999 43757 7.882601 1.332446
[1000 rows x 3 columns]
data_new:
[[2.44832535 2.39805139 2.56233353]
[2.15873259 2.34195467 2.98724416]
[2.28542943 2.06892523 2.47449629]
...
[2.29115949 2.50910294 2.51079493]
[2.52711097 2.43665451 2.4290048 ]
[2.47940793 2.3768091 2.78571804]]
2.2.2 标准化(使用场景更常见)
通过对原始数据进行变换把数据变换到均值0附近,标准差为1范围内。对于标准化来说由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而对方差和标准差影响也小。
特点:适合现代嘈杂大数据场景,在已有样本足够多的情况下异常点影响小,比较稳定。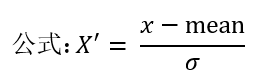

注:作用于每一列特征,mean为平均值,σ为标准差(考量数据的稳定性,数据集中标准差小,数据离散标准差大)
对数值数据进行标准差:sklearn.preprocessing.StandardScaler
StandardScaler()
- StandardScaler.fit_transform(X)
X:numpy array格式的二维数据[n_samples,n_features]
返回值:转换后的形状相同的array - StandardScaler.mean_
原始数据中每列特征的平均值
def stand_demo():
"""
标准化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None执行结果:
data:
milage Liters Consumtime
0 40920 8.326976 0.953952
1 14488 7.153469 1.673904
2 26052 1.441871 0.805124
3 75136 13.147394 0.428964
4 38344 1.669788 0.134296
.. ... ... ...
995 11145 3.410627 0.631838
996 68846 9.974715 0.669787
997 26575 10.650102 0.866627
998 48111 9.134528 0.728045
999 43757 7.882601 1.332446
[1000 rows x 3 columns]
data_new:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]2.2.3 缺失值(多用pandas处理)
缺失值处理方法
- 删除:如果每列或每行数据缺失值达到一定的比例,建议放弃整行或整列
- 填补:可以对每行或每列的缺失值填充平均值或中位数
a. sklearn处理缺失值
进行缺失值的填补
sklearn缺失值API: sklearn.impute.SimpleImputer
SimpleImputer(missing_values=np.nan, strategy=‘mean’)
- SimpleImputer.fit_transform(X)
X:numpy array格式数据
返回值:转换后的形状相同的array
from sklearn.impute import SimpleImputer
import numpy as np
def im():
'''
缺失值处理
:return:
'''
im = SimpleImputer(missing_values=np.nan, strategy='mean')
data = im.fit_transform([[1, 2],
[np.nan, 3],
[7, 6]]
)
print(data)
return None
if __name__ == '__main__':
im()
执行结果:

b. pandas处理缺失值
使用指定的统计值来代替缺失值np.nan,注意nan的数据类型为float类型。如果缺失值不是规范np.nan(float形式),可以通过replace(“?”, np.nan)将其他符号标记的缺失值,统一替换成np.nan。
- 判断是否为nan
1.pd.isnull(df)–为nan的元素返回Ture
2.pd.notnull(df)–为nan的元素返回False - 处理nan
1.删除数据
dropna (axis=0, how=‘any’, inplace=False)
axis=0删除行,axis=1删除列
how=‘any’(默认)只要该行/列含有nan就删除,how='all’整行/整列都为nan时删除
inplace=True在原对象上进行更改,默认inplace=False
2.填充数据
df.fillna(df.mean()/df.median()/0)-- 填均值/中位数/零
ps:对无意义的0可以先处理为nan再处理缺失值(df[df==0]=np.nan)
2.3 数据降维
2.3.1 特征选择
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,对特征数量进行降维。
- 特征选择原因:
避免冗余:部分特征的相关度高,容易消耗计算性能
消除噪声:部分特征对预测结果有负影响 - 特征选择的三大方法:
Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式):基本不使用
sklearn特征选择API:sklearn.feature_selection
a. 过滤式
通过方差的值,删除所有低方差特征。如当一列数值大都相同的情况下,即var≈0,则过滤此特征。
sklearn特征选择过滤式API:sklearn.feature_selection.VarianceThreshold
VarianceThreshold(threshold = 0.0)
训练集方差低于指定threshold的特征将被删除,threshold可取0~10之间的数,根据实际情况设定。默认值保留所有非零方差特征,即删除值相同的特征。
- VarianceThreshold.fit_transform(X)
X:numpy array格式的数据
from sklearn.feature_selection import VarianceThreshold
def var():
'''
过滤式特征选择--删除低方差的特征
:return: None
'''
var = VarianceThreshold(threshold=0.0) # threshold默认0.0
data = var.fit_transform([[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]]
)
print(data)
return None
if __name__ == '__main__':
var()
执行结果:
2.3.2 主成分分析
主成分分析又称为PCA,是一种简化数据集的技术,在特征数过百的情况下,考虑数据的简化。高维特征普遍存在特征与特征之间线性相关的情况,通过压缩数据维度,在损失少量信息情况下,尽可能降低原数据的维数(复杂度)。
作用:可以削减回归分析或者聚类分析中特征的数量
sklearn主成分分析降维API:sklearn. decomposition
sklearn主成分分析PCA语法API:sklearn. decomposition.PCA
PCA(n_components=None):
- n_components取值:
1.小数:指定信息保留率,保留率一般在90%~95%
2.整数:指定保留特征数量,一般不用 - PCA.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
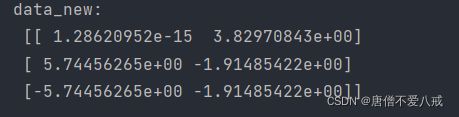
def pca_demo():
"""
PCA降维
:return:
"""
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1、实例化一个转换器类
transfer = PCA(n_components=0.95)
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None执行结果:
a. 案例:研究用户对物品类别的喜好细分降维
- 数据:
products.csv:商品信息
order_products__prior.csv:订单与商品信息
orders.csv:用户的订单信息
aisles.csv:商品所属具体物品类别 - 第一步:合并各张表到一张表(pandas–pd.merge())
products:product_id, aisle_id
prior:order_id,product_id
orders:order_id,user_id
aisles:aisle_id
import pandas as pd
from sklearn.decomposition import PCA
# 读取四张表的数据
aisles=pd.read_csv(r"F:\working\pycharm_project\machine_learn\data\aisles.csv")
prior=pd.read_csv(r"F:\working\pycharm_project\machine_learn\data\order_products__prior.csv")
orders=pd.read_csv(r"F:\working\pycharm_project\machine_learn\data\orders.csv")
products=pd.read_csv(r"F:\working\pycharm_project\machine_learn\data\products.csv")
# 将四张表合并至一张表
_mg=pd.merge(products, prior, on=('product_id','product_id'))
_mg=pd.merge(_mg, orders, on=('order_id','order_id'))
mg=pd.merge(_mg, aisles, on=('aisle_id','aisle_id'))

- 第二步:建立行为用户id,列为物品种类的交叉表
pd.crosstab(表[行维度],表[列维度])
# 交叉表:特殊的分组工具
cross=pd.crosstab(mg['product_id'],mg['aisle'])

- 第三步:进行主成分分析,进行降维
# 进行主成分分析
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
附:最全代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from sklearn.decomposition import PCA
from scipy.stats import pearsonr
import jieba
import pandas as pd
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值:\n", iris.data, iris.data.shape)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
def dict_demo():
"""
字典特征抽取
:return:
"""
data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=True)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray(), type(data_new))
print("data_new sparse矩阵:\n", data_new, type(data_new))
print("特征名字:\n", transfer.get_feature_names())
return None
def count_demo():
"""
文本特征抽取:CountVecotrizer
:return:
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["is", "too"])
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("data_new sparse矩阵:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
def count_chinese_demo():
"""
中文文本特征抽取:CountVecotrizer
:return:
"""
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("data_new sparse矩阵:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
def cut_word(text):
"""
进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门"
:param text:
:return:
"""
return " ".join(list(jieba.cut(text)))
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def tfidf_demo():
"""
用TF-IDF的方法进行文本特征抽取
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = TfidfVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def minmax_demo():
"""
归一化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3])
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
def stand_demo():
"""
标准化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
# 计算某两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\n", r2)
return None
def pca_demo():
"""
PCA降维
:return:
"""
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1、实例化一个转换器类
transfer = PCA(n_components=0.95)
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
# datasets_demo()
# 代码2:字典特征抽取
# dict_demo()
# 代码3:文本特征抽取:CountVecotrizer
# count_demo()
# 代码4:中文文本特征抽取:CountVecotrizer
# count_chinese_demo()
# 代码5:中文文本特征抽取,自动分词
# count_chinese_demo2()
# 代码6:中文分词
# print(cut_word("我爱北京天安门"))
# 代码7:用TF-IDF的方法进行文本特征抽取
# tfidf_demo()
# 代码8:归一化
# minmax_demo()
# 代码9:标准化
# stand_demo()
# 代码10:低方差特征过滤
# variance_demo()
# 代码11:PCA降维
pca_demo()