可视化小项目-全国房价分析
1.目的
为了了解目前全国新一线城市新盘的房价情况,从房价的角度探究最宜居新一线城市概况,作此分析,也仅作表层分析,为下一步机器学习预测房价做准备。
2.数据采集
2.1 准备工作
常见的新盘网站有链家,房客网,贝壳等,为了方便,选择房客网(因为能够借鉴部分代码。。。暂时找不到借鉴代码的链接,后面找到了,再补上)
需要用到的数据有:采集时间,楼盘,平均价格,总价,地址(所在区,所在县,所在详细地址)等,根据需求进行合适构造。
2.2 构造参数
1.构造头参数
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 "
"Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
def create_request_headers():
headers = dict()
headers["User-Agent"] = random.choice(USER_AGENTS)
headers["Referer"] = "http://www.ke.com"
return headers
构造需要采集到的数据的维度:
时间维度
def get_local_time_string():
"""
返回形如"2021-04-09"这样的时间字符串
"""
current = time.localtime()
return time.strftime("%Y-%m-%d", current)
价格等维度
def get_price_info(self, city_name):
self.city_name = city_name
self.price_info_list = list()
target_web = 'http://{0}.fang.ke.com/loupan/'.format(city_name)
print('request target web:', target_web)
# 获得请求头部
headers = create_request_headers()
# 发起网页请求(获取总页数)
response = requests.get(target_web, timeout=10, headers=headers)
html = response.content
soup = BeautifulSoup(html, 'lxml')
# 获得response总页数
try:
page_box = soup.find_all('div', class_='page-box')[0]
matches = re.search(r'.*data-total-count="(\d+)".*', str(page_box))
total_page = int(math.ceil(int(matches.group(1)) / 10))
# total_page = 2 测试
except Exception as e:
print("warning: only find one page for {0}".format(city_name))
print(e)
print('total pages:', total_page)
headers = create_request_headers()
# 遍历房价网页
# for i in range(1, total_page + 1) :
for i in range(1, total_page + 1):
target_sub_web = target_web + "pg{0}".format(i)
print('request target web:', target_sub_web)
if True == RANDOM_DELAY:
# 随机延时(0-15)秒
random_delay = random.randint(0, DELAY_MAX + 1)
print('random delay: %s S...' % (random_delay))
time.sleep(random_delay)
# 发起网页请求
response = requests.get(target_sub_web, timeout=10, headers=headers)
html = response.content
soup = BeautifulSoup(html, 'lxml')
# 获取房价相关内容
house_contents = soup.find_all("li", class_="resblock-list")
for house_content in house_contents:
# 获取单价
house_price = house_content.find("span", class_="number")
# 获取总价
house_total = house_content.find("div", class_="second")
# 获取小区名称
house_name = house_content.find("a", class_="name")
部分价格可能会出现无的情况,采用try捕获异常
try:
price = house_price.text.strip()
except Exception as e:
price = "0"
# 整理小区名称数据
name = house_name.text.replace("\n", " ")
# 整理总价数据
try:
total = house_total.text.strip().replace(u"总价", " ")
total = total.replace(u"/套起", " ")
except Exception as e:
total = "0"
格式化存储数据信息
def store_price_info(self):
# 创建数据存储目录
root_path = get_root_path()
store_dir_path = root_path + "/data/original_data/{0}".format(self.city_name)
is_dir_exit = os.path.exists(store_dir_path)
if not is_dir_exit:
os.makedirs(store_dir_path)
# 存储格式化的房价数据到相应日期的文件中
store_path = store_dir_path + "/{0}.csv".format(get_local_time_string())
with open(store_path, "w", encoding='utf-8') as fd:
fd.write("data,name,price,total,address,address1,adress2\n")
for price in self.price_info_list:
fd.write(price)2.3 爬取数据
if __name__ == '__main__':
# 'cd','cq','cs', 'wh', 'hz', 'xa', 'tj', 'su', 'nj'
# , 'zz', 'dg', 'sy', 爬取完毕
city_list = ['qd', 'fs']
for city in city_list:
try:
# 创建贝壳网爬虫实例
spider = beike_spider()
# 获取网页房价数据
spider.get_price_info(city) # # http://xa.fang.ke.com/,各地区的贝壳房价,自行查看拼音简写
# 存储房价数据bj
spider.store_price_info()
print("数据写入完毕")
except:
print("---------------------------")
with open(city + "_log.txt", 'w') as fl:
fl.write(city + "爬取过程中出现问题")
print("%s爬取过程中出现问题!" % city)
print("---------------------------")
3.数据清洗
数据清洗主要包括数据去重,空值填充,异常值处理三部分:
3.1 数据去重
在爬虫爬取数据过程中,由于网站数据本身会重复或爬虫本身的原因,往往会出现重复数据,针对重复数据,直接采用drop_duplicates()方法即可。
df.drop_duplicates(subset=['A','B'],keep='first',inplace=True)主要参数:
subset: 输入要进行去重的列名,默认为None
keep: 可选参数有三个:‘first’、 ‘last’、 False, 默认值 ‘first’。其中,
- first表示: 保留第一次出现的重复行,删除后面的重复行。
- last表示: 删除重复项,保留最后一次出现。
- False表示: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。
在实际使用过程中,一般不考虑参数情况,有需要,进行合适参数书写即可。
cd_data = cd_data.drop_duplicates()3.2 空值填充
pandas中fillna()方法,能够使用指定的方法填充NA/NaN值。
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)主要参数:
value:用于填充的空值的值。
method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。只可以为0或者1。0或'index',即按行删除;1或'columns',即按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
limit:int,默认为空。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
downcast:dict,默认为空,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
针对本次数据的空值填充,在爬虫阶段已经将空值填充为“价格未定”,需要对此做出处理:
在此将“价格未定”修改为1,为了方便将其转化为数值型数据处理。
county_price = cd_data[cd_data['address'] == county]['price'].str.strip().replace('价格待定', '1')
3.3 异常值处理
参见:https://www.cnblogs.com/tinglele527/p/11955103.html
常用的方法为盒图以及拉依达准则,盒图可以参考:https://blog.csdn.net/qq_37272891/article/details/115625658?spm=1001.2014.3001.5501
针对异常值常常采用
1.直接去除:可能会造成数据缺失。
2.平均值或模型填充:根据异常数据的情况,采用平均值或者拉格朗日插值法,异或数据符合的模型进行填充。
3.实际值填充:如果异常值多的情况下,会非常浪费时间与经理
针对本次数据的数据过程中,不需要进行过多复杂操作,因为本次数据分析需求简单,而且本次数据的异常值极大值比较奇怪,但是符合实际情况。极小值与实际不符
首先做一个简单筛选:
print(county_price[county_price<1000])发现存在着数据即price<2000的情况,对于新一线城市而言,十分不符合常理。

因此在数据处理过程中需要将其去除,筛掉不符合的小数据即可。
4.数据分析
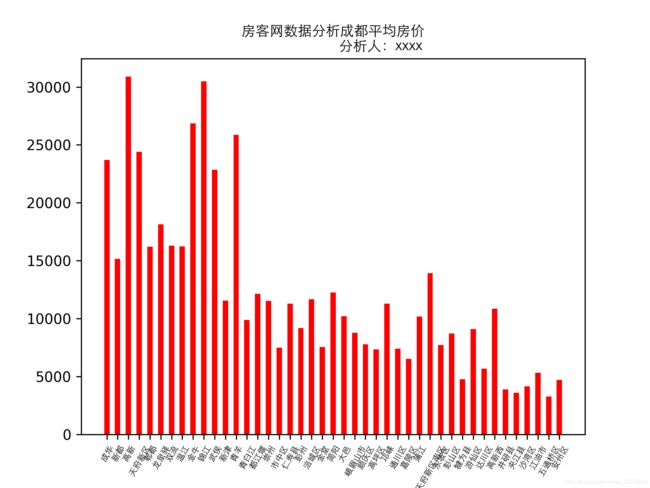
以成都数据为例,结合数据清洗情况,进行合适的分析(本次将数据清洗涵盖在了一下代码中)。
#!/usr/bin/python3.9
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 #
# @Time : 2021/4/15 8:51
# @Author : # @Email : # @File : fangke_data_analysis_g1.py
# @Software: PyCharm
"""
成都各区域新开楼盘平均房价
数据源:房客网4.13号数据新开楼盘前100页
分析人 xxx
结论
建议
"""
import os
import sys
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
FONT = FontProperties(fname='C:\Windows\Fonts\STXIHEI.TTF')
all_mean_price = []
city_list = []
def fangKe_analysis(path, city, city_chinese):
# cd_data = ''
city_list.append(city)
cd_data = pd.read_csv(path)
mean_price_all = 0 # 城市所有区域平均房价
# print(cd_data)
# csv文件在写入的时间一般是以“,”作为分割
# print(cd_data.columns) # 获取列名
# print(cd_data[' adress']) # 获得所有房子所在区域
# print(cd_data[' adress']==' 龙泉驿') # 数据筛选龙泉为True,其它False
# print(cd_data[cd_data[' adress']==' 龙泉驿']) # 筛选出龙泉数据
# 数据去重
# cd_data = cd_data.duplicated().value_counts()
cd_data = cd_data.drop_duplicates()
# 数据空值
# cd_data = cd_data.isnull()
# print()
# price = _150
# 异常值处理,因为暂时没法处理,我们仅作记录
# 数据分析
# print(cd_data.columns)
# print(cd_data['adress'].values) # 获取值,形成列表
# print(cd_data['adress'].value_counts()) # 获取值,计算值出现次数
# print(type(cd_data['adress'].value_counts()))
mean_price = []
for county in cd_data['address'].value_counts().index:
# print(county, end='')
# print("数据如下:")
# print(cd_data[cd_data[' adress'] == county]) # 获取每个区域所有数据
# print(cd_data[cd_data[' adress'] == county][' price'])
# 异常数据处理
# print(cd_data[cd_data[' adress'] == county][' price'].replace(' 价格待定','1'))
county_price = cd_data[cd_data['address'] == county]['price'].str.strip().replace('价格待定', '1')
index = 1
sum = 0
county_price = pd.to_numeric(county_price)
print(county_price[county_price>50000])
for price in county_price:
if float(price) > 1000:
index += 1
sum += float(price)
mean = round(sum / index, 2)
# print(mean)
mean_price.append(mean)
mean_price_all += mean
# print("------------------------------------")
print(city + "数据分析完毕,图片生成中....")
# 画图
print(cd_data['address'].value_counts().index)
if len(mean_price) < 14:
font_size = 9
else:
font_size = 6
plt.bar(cd_data['address'].value_counts().index, mean_price, width=0.5, color='r')
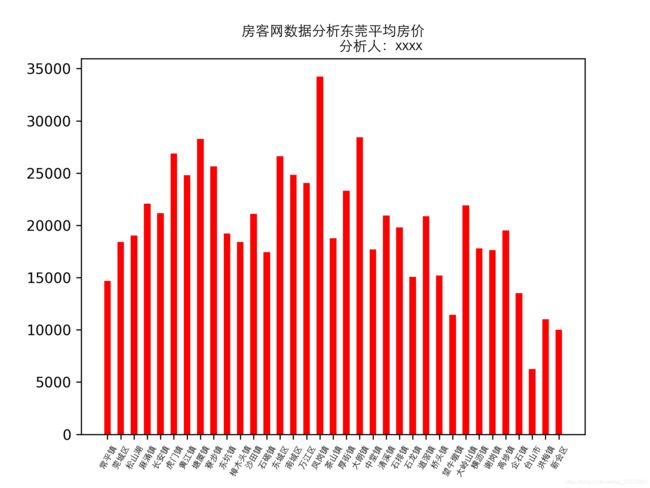
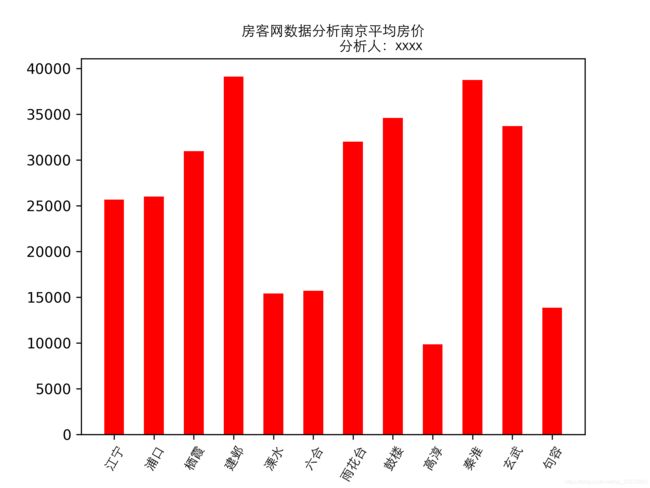
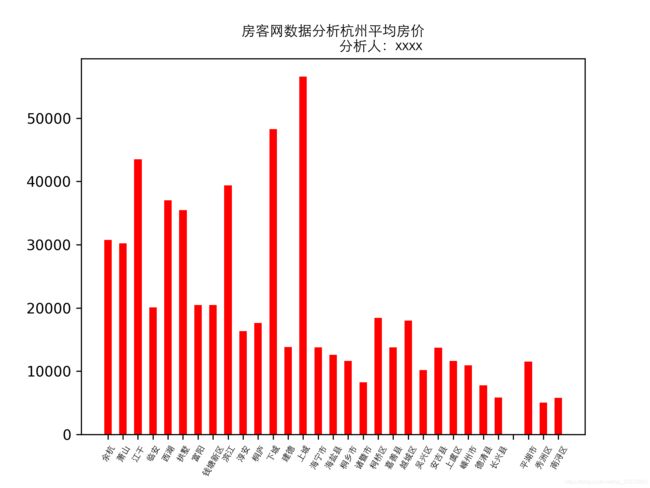
plt.title("房客网数据分析" + city_chinese + "平均房价\n"
" 分析人:xxxx", FontProperties=FONT)
plt.xticks(FontProperties=FONT, rotation=60, fontsize=font_size)
# plt.figure(figsize=(180,100))
plt.savefig(city_chinese + '.png', dpi=300)
print(city_chinese + "数据分析完毕,图片生成完毕,请检查。")
# del plt
plt.close()
all_mean_price.append(mean_price_all / len(mean_price))
if __name__ == '__main__':
rootdir = '../spider/data/original_data/'
city_list1 = ['成都', '重庆', '长沙', '东莞', '杭州', '南京', '青岛'
, '苏州', '沈阳', '天津', '武汉', '厦门', '郑州']
list_dir = os.listdir(rootdir)
k = 0;
for i in list_dir:
city_chinese = city_list1[k]
file = os.listdir(rootdir + i)
fangKe_analysis(path=rootdir + i + "/" + file[0], city=i, city_chinese=city_chinese)
k += 1
print(len(city_list1))
print(len(all_mean_price))
plt.bar(city_list1, all_mean_price, width=0.5, color='r')
plt.title("房客网数据分析-全国平均房价\n"
" 分析人:xxxx", FontProperties=FONT)
plt.xticks(FontProperties=FONT, fontsize=12)
plt.savefig('全国.png', dpi=300) # 设置分辨率为300,图片尺寸默认1920*1440
print("全国数据分析完毕,图片生成完毕,请检查。")
# del plt
plt.close() # 释放plt,防止数据堆积
5. 结果分析