通过电影票房预测来一览机器学习一般流程
前言
学习机器学习很久了,最近也涉及相关工作。这里通过电影票房预测来和大家,了解机器学习处理的一般流程。
数据集为kaggle上的tmdb5000的电影数据集,算法使用的是相对容易理解的knn算法。硬件则是普通的笔记本。
获取数据
相关包的引入
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
这里选择的是文件读取的方式,当然获取数据的方式是多样的。从db读取的方式也是较为常见的。
data = pd.read_csv("/home/dada/myprokect/tmdb_5000_movies.csv")
我们来大致看一眼数据
data.head()
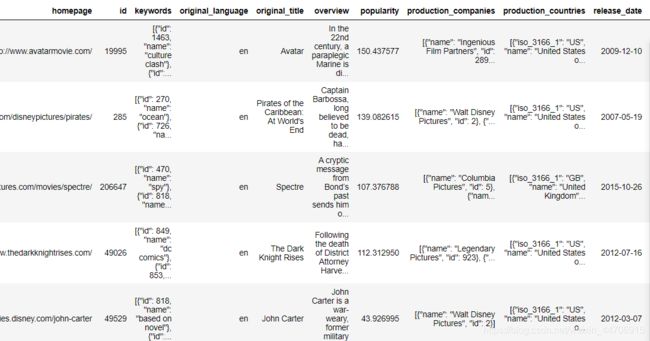
可以看到数据维度还是比较多的,我们需要对数据进行一些基本的预处理。
数据基本处理
空值去除
大致查看了一下数据,发现数据中除了有空值外,还有一些值以0的形式出现,我们先把这些值替换为空值。
data = data.replace(0, np.nan)
接着是为出现空值的行去掉
data = data.dropna(axis=0, how="any")
特征值提取
我们先提取特征值
feature_arr = data[['budget','popularity','runtime', 'vote_average', 'vote_count']].values
我们想通过’budget’(投资),‘popularity’(热度),‘runtime’(电影时长), ‘vote_average’(评分), ‘vote_count’(评分人数)这几个维度进行票房预测。
标签值提取
我们的标签值,也就是我们要预测的那个值,这里指的是电影的票房。
我们先将数据提取出来。
tag_arr = data['revenue']
我们可以大致看一下数据
0 2.787965e+09
1 9.610000e+08
2 8.806746e+08
3 1.084939e+09
4 2.841391e+08
...
4752 4.164980e+05
4758 6.008960e+05
4772 1.000000e+04
4773 3.151130e+06
4796 4.247600e+05
Name: revenue, Length: 1248, dtype: float64
由于这个标签值是连续型,也就是具体的值。我们此次使用的算法是k近邻分类算法。所以我们这里要略做处理。
我们通过pandas的分箱方法,把票房值转换为具体的高中低值。
tag_arr = np.array(pd.qcut(data['revenue'],3, labels=['低', '中', '高']))
array(['高', '高', '高', ..., '低', '低', '低'], dtype=object)
数据分割
x_train, x_test, y_train, y_test = train_test_split(feature_arr, tag_arr)
这里将数据分割为训练数据集与预测数据集,这里是默认7比3的方式。当然我们也可以自我选择分割比例。
特征工程
特征工程就对特征进行一些预处理操作,我们的训练特征均是连续型的,所以这里无需过多进行处理。这里只是对数据进行正则化转换,即把各个维度的数值拉到一个正态化的区间。
sklearn提供了相应的接口,我们可以轻松的调用。
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
模型训练
实例化一个KNN 预测器
revenue_predict = KNeighborsClassifier(n_neighbors=5)
模型训练
revenue_predict.fit(x_train, y_train)
模型评估
预测结果输出
然后我们就结果进行预测。
y_pre = revenue_predict.predict(x_test)
print("预测结果:\n", y_pre)
预测票房结果:
['低' '中' '中' '中' '低' '中' '高' '高' '中' '高' '中' '低' '低' '高' '中' '高' '高' '中'
'低' '低' '中' '中' '中' '高' '高' '低' '低' '高' '高' '高' '中' '中' '低' '低' '低' '高'
'中' '中' '中' '高' '低' '高' '中' '中' '中' '高' '低' '高' '低' '中' '中' '低' '高' '中'......
print("预测值和真实值的对比是:\n", y_pre==y_test)
预测值和真实值的对比是:
[ True True True True True True True False True True True True
True False False True True True True True True True True True
False False True True True True False False False True True True......
准确度计算
score = revenue_predict.score(x_test, y_test)
print(score)
0.7883333333333334
下面我们可以看准确度是否满足咱们的业务需求,后续可以更新超参数或者调整算法、算法调优等方式来提高准确度。
后记
当然真正的机器学习项目可能会更复杂一些,比如图表分析,超参数调优,损失函数优化等等。这里给大家展示一下机器学习的骨干流程。