SCS【11】单细胞ATAC-seq 可视化分析 (Cicero)

点击关注,桓峰基因
桓峰基因公众号推出单细胞系列教程,有需要生信分析的老师可以联系我们!首选看下转录分析教程整理如下:
Topic 6. 克隆进化之 Canopy
Topic 7. 克隆进化之 Cardelino
Topic 8. 克隆进化之 RobustClone
SCS【1】今天开启单细胞之旅,述说单细胞测序的前世今生
SCS【2】单细胞转录组 之 cellranger
SCS【3】单细胞转录组数据 GEO 下载及读取
SCS【4】单细胞转录组数据可视化分析 (Seurat 4.0)
SCS【5】单细胞转录组数据可视化分析 (scater)
SCS【6】单细胞转录组之细胞类型自动注释 (SingleR)
SCS【7】单细胞转录组之轨迹分析 (Monocle 3) 聚类、分类和计数细胞
SCS【8】单细胞转录组之筛选标记基因 (Monocle 3)
SCS【9】单细胞转录组之构建细胞轨迹 (Monocle 3)
SCS【10】单细胞转录组之差异表达分析 (Monocle 3)
SCS【11】单细胞ATAC-seq 可视化分析 (Cicero)
今天来说说单细胞ATAC-SEQ数据分析,学会这些分析结果,距离发文章就只差样本的选择了,有创新性的样本将成为文章的亮点,并不是分析内容了!
前 言
Cicero是一个R包,提供了分析单细胞染色质可及性实验的工具。Cicero的主要功能是利用单细胞染色质可及性数据,通过检测共可及性来预测基因组中顺式调控相互作用(如增强子和启动子之间的相互作用)。此外,Cicero扩展了Monocle 3,允许使用染色质可及性对单细胞进行聚类、排序和差异可及性分析。
Cicero的主要目的是利用单细胞染色质可及性数据来预测基因组中更有可能在细胞核中物理接近的区域。这可以用来识别假定的增强子-启动子对,并获得基因组区域顺式结构的总体结构的感觉。
由于单细胞数据的稀疏性,必须根据相似度对细胞进行聚合,以便对数据中的各种技术因素进行稳健校正。
最后,Cicero在用户定义的距离内的每对可及peak之间提供了一个介于-1到1之间的“Cicero可及性”分数,数值越大表示可及性越高。
此外,Cicero包提供了一个扩展工具包,用于使用Monocle 3提供的框架分析单细胞ATAC-seq实验。概述了使用Cicero的单细胞ATAC-Seq分析工作流程。
Cicero可以执行两种主要类型的分析:
-
构建和分析顺式调节网络。Cicero通过分析共可及性来确定假定的顺式调控相互作用,并使用各种技术来可视化和分析;
-
一般单细胞染色质可及性分析。Cicero还扩展了软件包Monocle
-
允许使用单细胞染色质可及性数据识别差异可及性、聚类、可视化和轨迹重建。
软件安装
Cicero 已更新与Monocle 3的工作!使用Monocle 3, Cicero可以使用改进的降维,并更好地处理大型数据集。Cicero的大部分功能保持不变,但有一些关键的区别,其中大部分来自Monocle 3的新cell_data_set对象。
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(c("Gviz", "GenomicRanges", "rtracklayer"))
#install.packages("devtools")
devtools::install_github("cole-trapnell-lab/cicero-release", ref = "monocle3")
数据读取
数据读取有三种方式,包括
- The cell_data_set class
2. Loading data from a simple sparse matrix format
- Loading 10X scATAC-seq data
The cell_data_set class
Cicero在cell_data_set (CDS)类的对象中保存数据。这个类是从Bioconductor singlecel实验类派生而来的,它提供了一个常用的接口,对于那些用Bioconductor分析过单细胞实验的人来说是很熟悉的。Monocle提供了关于如何在这里生成输入cd的详细文档。
为了修改CDS对象以保存染色质可访问性而不是表达数据,Cicero使用peak作为其特征数据fData,而不是基因或转录本。具体来说,许多Cicero函数需要以chr1_10390134_10391134的形式提供peak信息。例如,输入的fData表是这样的:

Loading data from a simple sparse matrix format
一般的散点矩阵加载数据,例子给出的是来自Mouse sci-ATAC-seq Atlas肾脏数据的示例数据集。
library(cicero)
library(monocle3)
# Code to download (54M) and unzip the file - can take a couple minutes
# depending on internet connection: temp <-
# textConnection(readLines(gzcon(url('http://staff.washington.edu/hpliner/data/kidney_data.txt.gz'))))
# Loading your data read in the data
cicero_data <- read.table("kidney_data.txt.gz")
head(cicero_data)
## V1 V2 V3
## 1 chr1_4756552_4757256 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
## 2 chr1_5301522_5303149 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
## 3 chr1_9737433_9739057 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
## 4 chr1_16105718_16106446 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
## 5 chr1_30753276_30753533 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
## 6 chr1_30753594_30754167 GAATTCGTACCAGGCGCATTGGTAGTCGGGCTCTGA 1
input_cds <- make_atac_cds(cicero_data, binarize = TRUE)

Loading 10X scATAC-seq data
如果scATAC-seq数据来自10x Genomics平台,下面是一个从Cell Ranger ATAC的输出创建输入CDS的示例。输出结果将在名为filtered_peak_bc_matrix的文件夹中。
# read in matrix data using the Matrix package
indata <- Matrix::readMM("filtered_peak_bc_matrix/matrix.mtx")
# binarize the matrix
indata@x[indata@x > 0] <- 1
# format cell info
cellinfo <- read.table("filtered_peak_bc_matrix/barcodes.tsv")
row.names(cellinfo) <- cellinfo$V1
names(cellinfo) <- "cells"
# format peak info
peakinfo <- read.table("filtered_peak_bc_matrix/peaks.bed")
names(peakinfo) <- c("chr", "bp1", "bp2")
peakinfo$site_name <- paste(peakinfo$chr, peakinfo$bp1, peakinfo$bp2, sep="_")
row.names(peakinfo) <- peakinfo$site_name
row.names(indata) <- row.names(peakinfo)
colnames(indata) <- row.names(cellinfo)
# make CDS
input_cds <- suppressWarnings(new_cell_data_set(indata,
cell_metadata = cellinfo,
gene_metadata = peakinfo))
input_cds <- monocle3::detect_genes(input_cds)
#Ensure there are no peaks included with zero reads
input_cds <- input_cds[Matrix::rowSums(exprs(input_cds)) != 0,]
实例分析
Constructing cis-regulatory networks
由于单细胞染色质可及性数据极其稀疏,精确估计共可及性评分需要我们聚合类似的细胞,以创建更密集的计数数据。Cicero使用knn方法来实现这一点,该方法创建重叠的x细胞集。Cicero基于细胞相似度降维将坐标映射构造这些集合,例如,从UMAP嵌入。
可以使用任何降维方法来建立聚合CDS的基础。这种降维方法可以从Monocle 3中获得(并由Cicero加载)。
一旦有了降维坐标映射,就可以使用函数make_cicero_cds来创建聚合的CDS对象。make_cicero_cds的输入是输入CDS对象和降维坐标映射。降维映射reduced_coordinates应该采用data.frame或矩阵的形式,其中行名与cd的pData表中的细胞id相匹配。reduced_coordinates的列应该是降维对象的坐标,例如:

使用Monocle3作为指南,我们首先找到input_cds的UMAP坐标:
set.seed(2017)
input_cds <- detect_genes(input_cds)
input_cds <- estimate_size_factors(input_cds)
input_cds <- preprocess_cds(input_cds, method = "LSI")
input_cds <- reduce_dimension(input_cds, reduction_method = "UMAP", preprocess_method = "LSI")
我们可以使用Monocle的绘图函数来可视化降维图:
plot_cells(input_cds)

接下来,我们从输入CDS对象中访问UMAP坐标,这些坐标存储在Monocle 3中,并运行make_cicero_cds:
umap_coords <- reducedDims(input_cds)$UMAP
cicero_cds <- make_cicero_cds(input_cds, reduced_coordinates = umap_coords)
Cicero包的主要功能是估计基因组中位点的共可及性,以预测顺式调控相互作用。有两种方法可以获得此信息:
- 函数run_cicero将使用默认值调用Cicero代码的每个相关片段,并在执行过程中计算最佳估计参数。对于大多数用户来说,这将是最好的起点。
考虑非默认参数。默认参数是为来自人类和小鼠细胞的数据设计的。每个用户都应该考虑某些非默认参数,特别是不使用人工数据的用户。
获得Cicero协同可访问性分数的最简单方法是运行run_cicero。要运行run_cicero,需要一个cicero CDS对象(上面创建的)和一个基因组坐标文件,其中包含有机体中每个染色体的长度。人类hg19坐标和老鼠mm9坐标包含在包中,可以通过数据(“human.hg19.genome”)和数据(“mouse.mm9.genome”)访问。下面是一个示例调用,继续使用示例数据:
注意:为了加快速度,在这里只在2号染色体的一小部分上运行Cicero。此外,将计算参数时使用的样本窗口的数量设置为2—在实际分析中这应该要大得多(默认为100)。
data("mouse.mm9.genome")
# use only a small part of the genome for speed
sample_genome <- subset(mouse.mm9.genome, V1 == "chr2")
sample_genome$V2[1] <- 1e+07
## Usually use the whole mouse.mm9.genome ## Usually run with sample_num = 100
## ##
conns <- run_cicero(cicero_cds, sample_genome, sample_num = 2)
## [1] "Starting Cicero"
## [1] "Calculating distance_parameter value"
## [1] "Running models"
## [1] "Assembling connections"
## [1] "Successful cicero models: 29"
## [1] "Other models: "
##
## Zero or one element in range
## 11
## [1] "Models with errors: 0"
## [1] "Done"
head(conns)
## Peak1 Peak2 coaccess
## 1 chr2_10001211_10002717 chr2_9752799_9753235 -0.01732054
## 2 chr2_10001211_10002717 chr2_9755255_9755584 -0.24392929
## 3 chr2_10001211_10002717 chr2_9767538_9767832 -0.23544150
## 4 chr2_10001211_10002717 chr2_9773328_9773904 -0.13085844
## 5 chr2_10001211_10002717 chr2_9774059_9774511 -0.26152722
## 6 chr2_10001211_10002717 chr2_9782941_9783191 0.24201192
-
单独调用Cicero函数 调用run_cicero的另一种方法是分块运行Cicero管道的每一部分。组成Cicero管道的三个功能是:
-
estimate_distance_parameter:该函数基于基因组的小随机窗口计算距离惩罚参数;
-
generate_cicero_models:该函数使用上述确定的距离参数,并使用图形LASSO计算基因组重叠窗口的可及性分数,使用基于距离的惩罚;
-
assemble_connections:该函数将generate_cicero_models的输出作为输入,并协调重叠的模型,以创建最终的共可访问性评分列表。
Visualizing Cicero Connections Cicero
包含一个名为plot_connections的通用绘图函数,用于可视化可及性。这个函数使用Gviz框架绘制基因组浏览器风格的图。从Sushi R包中改编了一个用于映射连接的函数。plot_connections有很多选项。
在这里,可选的gene_model数据,这样基因也可以绘制出来。
# Download the GTF associated with this data (mm9) from ensembl and load it
# using rtracklayer
# download and unzip temp <- tempfile()
# download.file('ftp://ftp.ensembl.org/pub/release-65/gtf/mus_musculus/Mus_musculus.NCBIM37.65.gtf.gz',
# temp)
gene_anno <- rtracklayer::readGFF("Mus_musculus.NCBIM37.65.gtf.gz")
# unlink(temp)
# rename some columns to match requirements
gene_anno$chromosome <- paste0("chr", gene_anno$seqid)
gene_anno$gene <- gene_anno$gene_id
gene_anno$transcript <- gene_anno$transcript_id
gene_anno$symbol <- gene_anno$gene_name
plot_connections(conns, "chr2", 9773451, 9848598, gene_model = gene_anno, coaccess_cutoff = 0.25,
connection_width = 0.5, collapseTranscripts = "longest")

Comparing Cicero connections to other datasets
通常,将Cicero连接与具有类似连接类型的其他数据集进行比较是有用的。例如,可能想比较Cicero的输出与cia - pet结扎的输出。为此,Cicero包含了一个名为compare_connections的函数。该函数将连接对的两个数据框conns1和conns2作为输入,并返回在conns2中找到的来自conns1的连接的逻辑向量。这个函数中的比较是使用genomic icranges包进行的,并使用来自该包的max_gap参数来允许比较中的坡度。
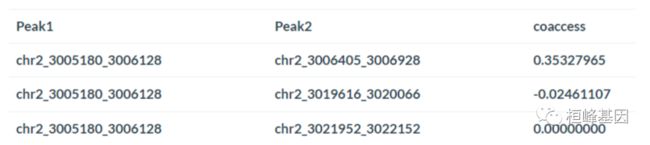
例如,如果想要比较Cicero预测和一组(编造的)cia - pet联系,我们可以运行:
chia_conns <- data.frame(Peak1 = c("chr2_3005100_3005200", "chr2_3004400_3004600",
"chr2_3004900_3005100"), Peak2 = c("chr2_3006400_3006600", "chr2_3006400_3006600",
"chr2_3035100_3035200"))
head(chia_conns)
## Peak1 Peak2
## 1 chr2_3005100_3005200 chr2_3006400_3006600
## 2 chr2_3004400_3004600 chr2_3006400_3006600
## 3 chr2_3004900_3005100 chr2_3035100_3035200
conns$in_chia <- compare_connections(conns, chia_conns)
head(conns)
## Peak1 Peak2 coaccess in_chia
## 1 chr2_10001211_10002717 chr2_9752799_9753235 -0.01732054 FALSE
## 2 chr2_10001211_10002717 chr2_9755255_9755584 -0.24392929 FALSE
## 3 chr2_10001211_10002717 chr2_9767538_9767832 -0.23544150 FALSE
## 4 chr2_10001211_10002717 chr2_9773328_9773904 -0.13085844 FALSE
## 5 chr2_10001211_10002717 chr2_9774059_9774511 -0.26152722 FALSE
## 6 chr2_10001211_10002717 chr2_9782941_9783191 0.24201192 FALSE
当比较完全不同的数据集时,可能会发现这种重叠过于严格。仔细看,cia - pet数据的第二行与最后一行显示的con非常接近。差异只有大约80个碱基对,这可能是一个peak调用的问题。这就是max_gap参数有用的地方:
conns$in_chia_100 <- compare_connections(conns, chia_conns, maxgap = 100)
head(conns)
## Peak1 Peak2 coaccess in_chia in_chia_100
## 1 chr2_10001211_10002717 chr2_9752799_9753235 -0.01732054 FALSE FALSE
## 2 chr2_10001211_10002717 chr2_9755255_9755584 -0.24392929 FALSE FALSE
## 3 chr2_10001211_10002717 chr2_9767538_9767832 -0.23544150 FALSE FALSE
## 4 chr2_10001211_10002717 chr2_9773328_9773904 -0.13085844 FALSE FALSE
## 5 chr2_10001211_10002717 chr2_9774059_9774511 -0.26152722 FALSE FALSE
## 6 chr2_10001211_10002717 chr2_9782941_9783191 0.24201192 FALSE FALSE
此外,Cicero的绘图函数有一种可视化比较数据集的方法。使用comparison_track参数。比较数据框必须包括在前两个peak列之外的第三列,称为“coaccess”。这就是绘图函数如何确定绘图连接的高度。这可以是一种定量测量,比如cia - pet中的结扎数,或者只是一列1。
# Add a column of 1s called "coaccess"
chia_conns <- data.frame(Peak1 = c("chr2_3005100_3005200", "chr2_3004400_3004600",
"chr2_3004900_3005100"),
Peak2 = c("chr2_3006400_3006600", "chr2_3006400_3006600",
"chr2_3035100_3035200"),
coaccess = c(1, 1, 1))
plot_connections(conns, "chr2", 3004000, 3040000,
gene_model = gene_anno,
coaccess_cutoff = 0,
connection_width = .5,
comparison_track = chia_conns,
comparison_connection_width = .5,
# nclude_axis_track = FALSE,
collapseTranscripts = "longest")

Finding cis-Co-accessibility Networks (CCANS)
除了成对的可及性评分,Cicero还有一个查找可及性网络(CCANs)的功能,CCANs是网站之间高度可及性的模块。我们使用Louvain社区检测算法(Blondel et al., 2008)来寻找倾向于共同访问的站点cluster。generate_ccans函数接受一个连接数据框作为输入,并为每个输入peak输出一个带有CCAN赋值的数据框。不包括在输出数据框中的站点没有被分配CCAN。

函数generate_ccans有一个可选输入,称为coaccess_cutoff_override。当coaccess_cutoff_override为NULL时,该函数将根据处于不同截止点的总体CCAN的数量,为CCAN生成确定并报告一个适当的共可及性性评分截止值。还可以将coaccess_cutoff_override设置为0到1之间的数字,以覆盖函数的截断查找部分。自动找到的截止过于严格或松散,或者正在重新运行代码并知道截止将是什么,则此选项非常有用,因为截止查找过程可能很慢。
CCAN_assigns <- generate_ccans(conns)
## [1] "Coaccessibility cutoff used: 0.49"
head(CCAN_assigns)
## Peak CCAN
## chr2_10001211_10002717 chr2_10001211_10002717 1
## chr2_10044937_10045253 chr2_10044937_10045253 3
## chr2_10047122_10047366 chr2_10047122_10047366 3
## chr2_10047571_10048202 chr2_10047571_10048202 3
## chr2_10049729_10050732 chr2_10049729_10050732 3
## chr2_10051180_10052772 chr2_10051180_10052772 4
Cicero gene activity scores
启动子的可及性通常不能很好地预测基因表达。然而,使用Cicero链接,能够更好地了解启动子的整体可及性及其相关的远端位点。该区域可达性综合得分与基因表达具有较好的一致性。称这个分数为Cicero基因活性分数,是用两个函数计算出来的。
初始函数称为build_gene_activity_matrix。该函数接受一个输入CDS和一个Cicero连接列表,并输出一个基因活性评分的非规格化表。重要提示:输入的CDS必须在fData表中有一个名为“基因”的列,如果该peak是启动子,则表示该基因,如果该peak是远端,则表示NA。下面演示了添加此列的一种方法。
build_gene_activity_matrix的输出是非规范化的,必须使用第二个名为normalize_gene_activities的函数进行规范化。如果打算在不同的数据集的数据子集中比较基因活动,那么所有的基因活动子集应该通过传入一个非归一化矩阵列表来一起归一化。如果只希望规范化一个矩阵,只需将其单独传递给函数即可。Normalize_gene_activities还需要每个细胞的总可访问站点的命名向量。这很容易在cd的pData表中找到,称为“num_genes_expression”。参见下面的示例。归一化基因活性评分范围从0到1。
#### Add a column for the pData table indicating the gene if a peak is a
#### promoter #### Create a gene annotation set that only marks the
#### transcription start sites of the genes. We use this as a proxy for
#### promoters. To do this we need the first exon of each transcript
pos <- subset(gene_anno, strand == "+")
pos <- pos[order(pos$start), ]
# remove all but the first exons per transcript
pos <- pos[!duplicated(pos$transcript), ]
# make a 1 base pair marker of the TSS
pos$end <- pos$start + 1
neg <- subset(gene_anno, strand == "-")
neg <- neg[order(neg$start, decreasing = TRUE), ]
# remove all but the first exons per transcript
neg <- neg[!duplicated(neg$transcript), ]
neg$start <- neg$end - 1
gene_annotation_sub <- rbind(pos, neg)
# Make a subset of the TSS annotation columns containing just the coordinates
# and the gene name
gene_annotation_sub <- gene_annotation_sub[, c("chromosome", "start", "end", "symbol")]
# Rename the gene symbol column to 'gene'
names(gene_annotation_sub)[4] <- "gene"
input_cds <- annotate_cds_by_site(input_cds, gene_annotation_sub)
tail(fData(input_cds))
## DataFrame with 6 rows and 7 columns
## site_name chr bp1 bp2
##
## chrY_590469_590895 chrY_590469_590895 Y 590469 590895
## chrY_609312_609797 chrY_609312_609797 Y 609312 609797
## chrY_621772_623366 chrY_621772_623366 Y 621772 623366
## chrY_631222_631480 chrY_631222_631480 Y 631222 631480
## chrY_795887_796426 chrY_795887_796426 Y 795887 796426
## chrY_2397419_2397628 chrY_2397419_2397628 Y 2397419 2397628
## num_cells_expressed overlap gene
##
## chrY_590469_590895 5 NA NA
## chrY_609312_609797 7 NA NA
## chrY_621772_623366 106 2 Ddx3y
## chrY_631222_631480 2 NA NA
## chrY_795887_796426 1 2 Usp9y
## chrY_2397419_2397628 4 NA NA
### Generate gene activity scores #### generate unnormalized gene activity
### matrix
unnorm_ga <- build_gene_activity_matrix(input_cds, conns)
# remove any rows/columns with all zeroes
unnorm_ga <- unnorm_ga[!Matrix::rowSums(unnorm_ga) == 0, !Matrix::colSums(unnorm_ga) ==
0]
# make a list of num_genes_expressed
num_genes <- pData(input_cds)$num_genes_expressed
names(num_genes) <- row.names(pData(input_cds))
# normalize
cicero_gene_activities <- normalize_gene_activities(unnorm_ga, num_genes)
# if you had two datasets to normalize, you would pass both: num_genes should
# then include all cells from both sets
unnorm_ga2 <- unnorm_ga
cicero_gene_activities <- normalize_gene_activities(list(unnorm_ga, unnorm_ga2),
num_genes)
Advanced visualizaton
在这里将展示一些绘图参数的示例,可能需要使用这些参数来进一步直观地探索数据。视点:视点参数允许只查看来自基因组中特定位置的连接。这在将数据与4C-seq数据进行比较时可能很有用。
cons_4c <- data.frame(Peak1 = c("chr2_9811600_9811800", "chr2_9811600_9811800", "chr2_9811600_9811800"),
Peak2 = c("chr2_9780000_9785000", "chr2_9810000_9810100", "chr2_9830000_9830700"),
coaccess = c(1, 1, 1))
plot_connections(conns, "chr2", 9773451, 9848598, viewpoint = "chr2_9811600_9811800",
gene_model = gene_anno, coaccess_cutoff = 0, connection_width = 0.5, comparison_track = cons_4c,
comparison_connection_width = 0.5, include_axis_track = F, collapseTranscripts = "longest")

Alpha_by_coaccess:当关心过度绘图时,Alpha_by_coaccess参数将非常有用。该参数导致连接曲线的alpha(透明度)根据共同可及性的大小进行缩放。比较下面两个图。
plot_connections(conns, alpha_by_coaccess = FALSE, "chr2", 9773451, 9848598, gene_model = gene_anno,
coaccess_cutoff = 0.2, connection_width = 0.5, collapseTranscripts = "longest")

plot_connections(conns, alpha_by_coaccess = TRUE, "chr2", 9773451, 9848598, gene_model = gene_anno,
coaccess_cutoff = 0.2, connection_width = 0.5, collapseTranscripts = "longest")

颜色:有几个参数与颜色有关: Peak_color comparison_peak_color connection_color comparison_connection_color gene_model_color viewpoint_color viewpoint_fill 这些参数中的每一个都可以以颜色名称的形式给出颜色值,例如:“blue”,或者颜色代码,例如:“#B4656F”。或者,对于上面的前四个参数,可以提供conns表中用于确定颜色的列的名称。在peak_color和comparison_peak_color的情况下,列应该对应于Peak1颜色分配。
# When the color column is not already colors, random colors are assigned
plot_connections(conns, "chr2", 3004000, 3040000, connection_color = "in_chia_100",
comparison_track = chia_conns, peak_color = "green", comparison_peak_color = "orange",
comparison_connection_color = "purple", comparison_connection_width = 0.5, gene_model_color = "#2DD881",
gene_model = gene_anno, coaccess_cutoff = 0.1, connection_width = 0.5, collapseTranscripts = "longest")

如果想要特定的配色方案,可以制作一列颜色名称
# If I want specific color scheme, I can make a column of color names
conns$conn_color <- "orange"
conns$conn_color[conns$in_chia_100] <- "green"
plot_connections(conns, "chr2", 3004000, 3040000, connection_color = "conn_color",
comparison_track = chia_conns, peak_color = "green", comparison_peak_color = "orange",
comparison_connection_color = "purple", comparison_connection_width = 0.5, gene_model_color = "#2DD881",
gene_model = gene_anno, coaccess_cutoff = 0.1, connection_width = 0.5, collapseTranscripts = "longest")

为peak着色,需要对应的颜色列Peak1:
# For coloring Peaks, I need the color column to correspond to Peak1:
conns$peak1_color <- FALSE
conns$peak1_color[conns$Peak1 == "chr2_3005180_3006128"] <- TRUE
plot_connections(conns, "chr2", 3004000, 3040000, connection_color = "green", comparison_track = chia_conns,
peak_color = "peak1_color", comparison_peak_color = "orange", comparison_connection_color = "purple",
comparison_connection_width = 0.5, gene_model_color = "#2DD881", gene_model = gene_anno,
coaccess_cutoff = 0.1, connection_width = 0.5, collapseTranscripts = "longest")

使用return_as_list自定义所有内容。可能希望在绘制cicero连接的同时绘制其他类型的数据。因此,包含了return_as_list选项。这个参数允许使用Gviz的广泛功能来绘制许多不同类型的基因组数据。
如果return_as_list设置为TRUE时,图像将不会被绘制,而是返回一个绘图组件列表。看一个更简单的例子:
plot_list <- plot_connections(conns, "chr2", 3004000, 3040000, gene_model = gene_anno,
coaccess_cutoff = 0.1, connection_width = 0.5, collapseTranscripts = "longest",
return_as_list = TRUE)
plot_list
## [[1]]
## CustomTrack ''
##
## [[2]]
## AnnotationTrack 'Peaks'
## | genome: NA
## | active chromosome: chr2
## | annotation features: 7
##
## [[3]]
## Genome axis 'Axis'
##
## [[4]]
## GeneRegionTrack 'Gene Model'
## | genome: NA
## | active chromosome: chr2
## | annotation features: 10
# I will replace the genome axis track with a track on conservation values
# To make the plot, I will now use Gviz's plotTracks function The included
# options are the defaults in plot_connections, but all can be modified
# according to Gviz's documentation
# The main new parameter that you must include, is the sizes parameter. This
# parameter controls what proportion of the height of your plot is allocated
# for each track. The sizes parameter must be a vector of the same length as
# plot_list
Gviz::plotTracks(plot_list, sizes = c(2, 1, 1, 1), from = 3004000, to = 3040000,
chromosome = "chr2", transcriptAnnotation = "symbol", col.axis = "black", fontsize.group = 6,
fontcolor.legend = "black", lwd = 0.3, title.width = 0.5, background.title = "transparent",
col.border.title = "transparent")

Single-cell accessibility trajectories
Cicero包的第二个主要功能是扩展Monocle 3,以便使用单细胞可访问性数据。染色质可及性数据要克服的主要障碍是稀疏性,所以大多数扩展和方法都是为了解决这个问题而设计的。
利用可达性数据构建轨迹。简单地说,Monocle通过三步推断拟时间轨迹:
-
预处理
-
降维
-
聚类的细胞
-
学习轨迹图
-
按拟时间顺序排列细胞
这些步骤可以在可访问性数据上运行,只需要稍加修改: 首先,下载并加载数据:
set.seed(2017)
input_cds <- estimate_size_factors(input_cds)
# 1
input_cds <- preprocess_cds(input_cds, method = "LSI")
# 2
input_cds <- reduce_dimension(input_cds, reduction_method = "UMAP", preprocess_method = "LSI")
# 3
input_cds <- cluster_cells(input_cds)
# 4
input_cds <- learn_graph(input_cds)
##
|
| | 0%
|
|======================================================================| 100%
# 5 cell ordering can be done interactively by leaving out 'root_cells'
input_cds <- order_cells(input_cds, root_cells = "GAGATTCCAGTTGAATCACTCCATCGAGATAGAGGC")
plot_cells(input_cds, color_cells_by = "pseudotime")

Differential Accessibility Analysis
聚合:为差异分析寻址稀疏性 Cicero包处理单细胞染色质可及性数据的稀疏性的主要方法是通过聚合。聚合单个细胞或单个peak的计数可以让我们产生一个“一致的”计数矩阵,减少噪音,并允许二进制模式。在这种分组下,可以用二项分布来模拟可访问特定位置的细胞数量,或者对于足够大的群体,用相应的高斯近似。将分组可及性计数建模为正态分布,Cicero可以通过简单地拟合线性模型,并将其残差作为每组细胞的可及性调整得分,轻松地针对任意技术协变量对其进行调整。下面实际演示如何应用这个分组。
一旦有了细胞的拟时间排序,就可以问基因组中染色质可及性的变化时间。如果知道对的系统很重要的特定站点,那么可能希望在拟时间内可视化这些站点的可访问性。
跨拟时间plot_accessibility_in_pseudotime可视化可访问性 为了简单起见,将只包括轨迹的主要部分。
input_cds_lin <- input_cds[, is.finite(pseudotime(input_cds))]
plot_accessibility_in_pseudotime(input_cds_lin[c("chr1_3238849_3239700", "chr1_3406155_3407044",
"chr1_3397204_3397842")])

使用单细胞染色质可及性数据运行fit_models 感兴趣的是站点级别的统计信息(站点是否在拟时间中发生变化),因此我们将聚合类似的细胞。为此,Cicero提供了一个有用的函数aggregate_by_cell_bin。aggregate_by_cell_bin 我们使用aggregate_by_cell_bin函数按pData表中的列聚合输入CDS对象。通过将拟时间轨迹切割为10个部分来将细胞分配给箱子。
# First, assign a column in the pData table to umap pseudotime
pData(input_cds_lin)$Pseudotime <- pseudotime(input_cds_lin)
pData(input_cds_lin)$cell_subtype <- cut(pseudotime(input_cds_lin), 10)
binned_input_lin <- aggregate_by_cell_bin(input_cds_lin, "cell_subtype")
现在,我们准备运行Monocle 3的fit_models函数来查找跨拟时间可访问的不同站点。将num_genes_expression作为协变量来减去它的影响。
# For speed, run fit_models on 1000 randomly chosen genes
set.seed(1000)
acc_fits <- fit_models(binned_input_lin[sample(1:nrow(fData(binned_input_lin)), 1000),
], model_formula_str = "~Pseudotime + num_genes_expressed")
fit_coefs <- coefficient_table(acc_fits)
# Subset out the differentially accessible sites with respect to Pseudotime
pseudotime_terms <- subset(fit_coefs, term == "Pseudotime" & q_value < 0.05)
head(pseudotime_terms)
## # A tibble: 2 × 15
## site_name num_c…¹ use_f…² gene_id model model_su…³ status estim…⁴ std_err
##
## 1 chr12_11… 3 FALSE chr12_… OK -0.694 0.0661
## 2 chr16_32… 3 FALSE chr16_… OK 0.641 0.00905
## # … with 6 more variables: test_val , p_value ,
## # normalized_effect , term , model_component , q_value ,
## # and abbreviated variable names ¹num_cells_expressed, ²use_for_ordering,
## # ³model_summary, ⁴estimate
我们这期主要介绍ATAC-SEQ可视化分析,目前单细胞测序的费用也在降低,单细胞系列可算是目前的测序神器,有这方面需求的老师,联系桓峰基因,提供最高端的科研服务!
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
有想进生信交流群的老师可以扫最后一个二维码加微信,备注“单位+姓名+目的”,有些想发广告的就免打扰吧,还得费力气把你踢出去!
References:
-
Blondel, V.D., Guillaume, J.-L., Lambiotte, R., and Lefebvre, E. (2008). Fast unfolding of communities in large networks.
-
Dekker, J., Marti-Renom, M.A., and Mirny, L.A. (2013). Exploring the three-dimensional organization of genomes: interpreting chromatin interaction data. Nat. Rev. Genet. 14, 390–403.
-
Sanborn, A.L., Rao, S.S.P., Huang, S.-C., Durand, N.C., Huntley, M.H., Jewett, A.I., Bochkov, I.D., Chinnappan, D., Cutkosky, A., Li, J., et al. (2015). Chromatin extrusion explains key features of loop and domain formation in wild-type and engineered genomes… Proc. Natl. Acad. Sci. U. S. A. 112, E6456–E6465.
-
Sexton, T., Yaffe, E., Kenigsberg, E., Bantignies, F., Leblanc, B., Hoichman, M., Parrinello, H., Tanay, A., and Cavalli, G. (2012). Three-Dimensional Folding and Functional Organization Principles of the Drosophila Genome… Cell 148:3, 458-472.
