Fast-SCNN:多分支结构共享低级特征的语义分割网络

介绍一篇 BMVC 2019 语义分割论文 Fast-SCNN:Fast Semantic Segmentation Network,谷歌学术显示该文已有62次引用。

论文:https://arxiv.org/pdf/1902.04502.pdf
代码:https://github.com/Tramac/Fast-SCNN-pytorch (PyTorch实现,星标200+,非官方)
0

绪论
自动驾驶和移动机器人的兴起,对实时语义分割算法的需求越来越强烈。在自动驾驶或者移动机器人的应用场景下,对语义分割算法一般有着额外的需求:
算法要有实时性,最好实时性非常高,因为语义分割仅仅是整个视觉感知系统中预处理的一部分,语义分割的结果往往作为后续感知或融合模块的输入;
算法要占用比较低的内存,以允许部署在低成本的嵌入式设备中。
一般来讲,基于卷积神经网络做语义分割通常使用encoder-decoder结构,比如下面2篇文章:
Fully convolutional networks for semantic segmentation.
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Im8 age Segmentation.
在此基础上,很多实时性的语义分割算法还会使用多分枝网络结构,比如下面3篇文章:
Contextnet: Exploring context and detail for semantic segmentation in real-time.
Bisenet: Bilateral segmentation network for real-time semantic segmentation.
Guided Upsampling Network for Real-Time Semantic Segmentation.
在2分支的网络结构中,较深的分支输入低分辨率图片,目的是为了在保证较少计算开销的前提下有效地提取全局上下文特征;较浅的网络分支输入高分辨率图像,目的是提取空间细节信息。两个分支的计算结果融合,形成最终的语义分割结果。
1
动机
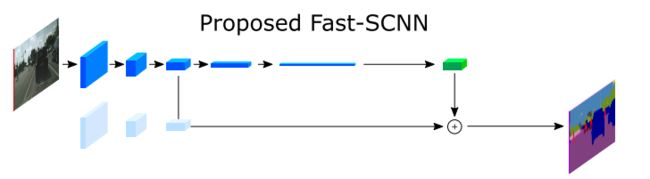
在2分支结构的网络中,2个分支基本保持着相对独立的计算流程。“深网络+低分辨率输入”和“浅网络+高分辨率输入”的组合能够较好地控制计算开销,以保证算法的实时性。如下图所示:

2个分支的浅层部分,实际上都是在提取浅层特征,若能将2个分支的浅层部分合并在一起,则可以进一步减少计算量。基于此,作者提出了“learning to downsample”模块,2个分支共用该模块提取浅层特征。并以learning to downsample模块和2个分支为基础,构建实时性语义分割网络Fast-SCNN。如下图所示:
2
Fast-SCNN
2.1 总体结构
Fast-SCNN的总体结构如下图所示:
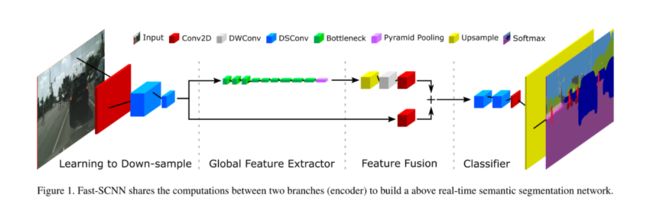
从上图可以看出,2个分支共享learning to downsample模块,以进一步减少计算量。整个网络由learning to downsample模块、全局特征提取器、特征融合模块和分类器4部分组成,下面分别介绍。
2.2 Learning to Downsample模块
该模块包括3个卷积层,第一个卷积层为普通的卷积层,后面两个卷积层使用深度可分离卷积以提高计算效率。
每个卷积层的步长都是2,因此该模块输出特征的长(或宽)为输入图像的1/8。每个卷积层的卷积核尺寸为3x3,每个卷积层后面都有BN层和ReLU激活函数。
2.3 全局特征提取器
Fast-SCNN使用全局特征提取器来提取全局特征,此处的全局特征提取器类似于传统2分支结构中的深度分支。传统的2分支结构中深度分支的输入是低分辨率的输入图像,而Fast-SCNN中全局特征提取器的输入为learning to downsample模块的输出feature map。可以这么理解:Fast-SCNN中的learning to downsample模块代替了传统2分支结构中深度分支的前几个卷积层。
使用MobileNet-v2中提出的bottleneck residual block构建全局特征提取器,bottleneck residual block中的深度可分离卷积有利于减少全局特征提取器的参数量和计算量。
全局特征提取器还包含pyramid pooling模块(PPM),用于提取不同尺度的上下文特征。关于PPM的相关内容可参考论文《Pyramid Scene Parsing Network》。
2.4 特征融合模块
特征融合模块用于融合2个分支的输出特征,Fast-SCNN使用了相对比较简单的结构完成特征融合,以最大限度地提高计算效率。
特征融合模块的结构如下表所示:
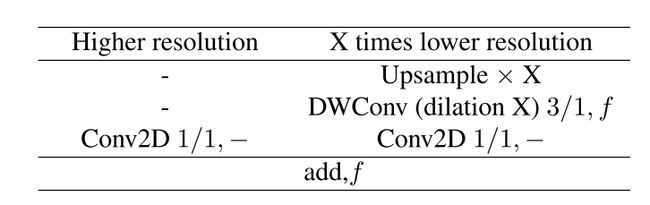
为了使得2个分支的输出特征尺寸一致,需要对深度分支的特征做上采样操作,即上表中的“Upsample x X”操作。两个分支的最后都有1个卷积核尺寸为1x1的卷积操作用于调整通道数,将两个卷积操作的输出特征相加,之后使用激活函数进行非线性变换。
2.5 分类器
分类器模块中包含2个深度可分离卷积和1个卷积核尺寸为1x1的卷积以提高网络性能。
在分类器模块中还包含1个softmax操作。在网络训练时,softmax操作用于计算损失。在推理时,使用argmax操作代替softmax以提高推理速度。
2.6 网络结构总结
下表为这4部分的网络结构参数:

上表中第3列~第6列表示网络结构的参数,其中t表示bottleneck residual block的expansion factor,具体含义在论文《MobileNetV2: Inverted Residuals and Linear Bottlenecks》中有讲解,简单来说,就是bottleneck residual block内部feature map的通道数与bottleneck residual block输入端feature map通道数的比值;c表示该计算模块输出的feature map通道数;n表示该模块重复的次数;s表示卷积的步长,若计算模块重复了很多次,s所表示的步长只适用于第一次使用该模块时。
3
一些实现细节
使用交叉熵损失函数进行训练,在learning to downsample模块和全局特征提取器后面分别添加了权重为0.4的辅助损失函数用于训练。
在softmax的前一个卷积层中使用了dropout。
使用ReLU激活函数,而没有使用MobileNet中的ReLU6激活函数,实验证明训练Fast-SCNN时使用ReLU收敛更快、性能更好。
训练时迭代多次性能仍有提高,在Cityscapes数据集上训练了1000个epochs。
4
实验结果
使用Cityscapes数据集训练Fast-SCNN,在Cityscapes测试集上测试,,结果如下表所示:
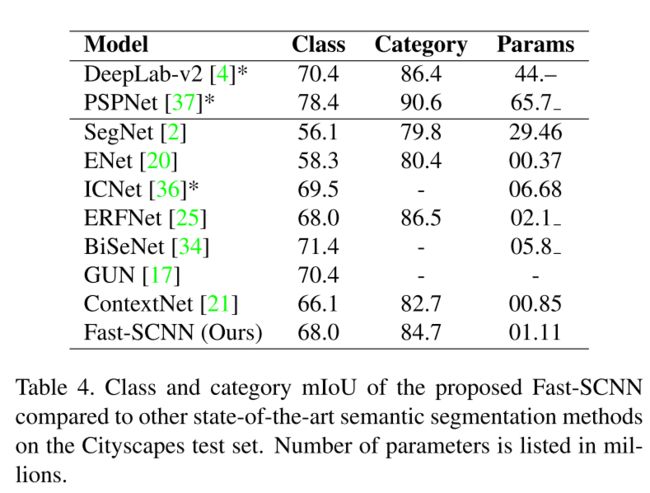
从表中可以看出,Fast-SCNN的性能好于大多数算法,比BiSeNet和GUN略差,但是Fast-SCNN的参数量只是BiSeNet的1/5。
调整Fast-SCNN的输入图片分辨率,测量算法的运行时间,得到下表:
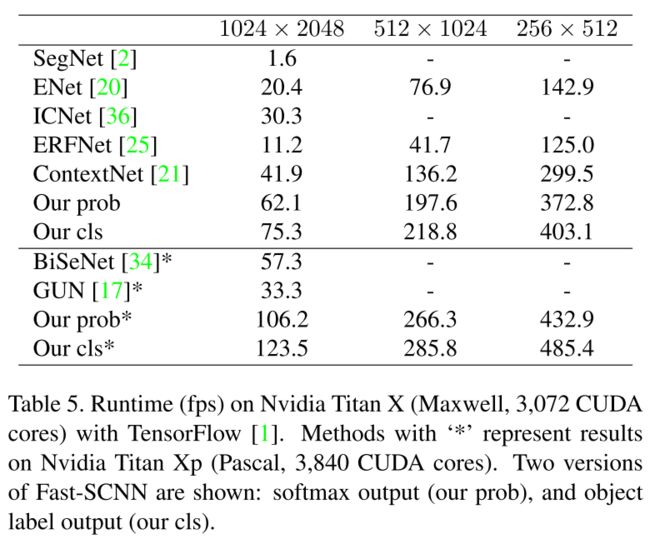
从表中可以看出,在同等GPU架构和输入图片分辨率下,Fast-SCNN的运行速度要远远快于BiSeNet和GUN。上表中的“Our prob”表示在Fast-SCNN推理时使用了softmax函数得到最终的类别,“Our cls”表示在推理时使用了计算量更小的argmax操作得到最终类别,可以看出使用argmax代替softmax,速度有很大的提升。
需要特别指出的是,Fast-SCNN网络结构支持多种输入图片分辨率,因此改变输入图片分辨率并不需要改变网络结构。
5
总结
指出在多分枝结构的语义分割网络中,2个分支共用浅层网络能够进一步精简网络结构,达到提高运算速度的目的。
设计出了learning to downsample模块,2个分支共用该模块提取低级特征。
以learning to downsample模块、bottleneck residual block为基础,构建了Fast-SCNN用于语义分割任务,通过实验证明了Fast-SCNN的高性能与高实时性。
仅用于学习交流!
END

备注:分割

图像分割交流群
语义分割、实例分割、全景分割、抠图等技术,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号 : aicvml
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 